Reddit網(wǎng)友吵爆!算力和數(shù)據(jù)真能解決一切?
眾所周知,算力和數(shù)據(jù)非常重要,但只有它們就夠了嗎?
近日,一位reddit用戶發(fā)起一個討論帖:如果我們只有更多的數(shù)據(jù)和計算能力而停止理論工作的發(fā)展,今天的哪些問題可以解決?哪些問題絕對無法解決?
友吵爆!算力和數(shù)據(jù)真能解決一切?")
這個問題引發(fā)了reddit網(wǎng)友的熱烈討論:

MrAcurite表示:我猜想任何涉及罕見疾病診斷的事情。我們沒有更多數(shù)據(jù),因為數(shù)據(jù)不存在。但這只是一個猜測,也許小樣本學(xué)習(xí)還是可以解決這個問題的。

MichaelMMeskhi回復(fù)道:小樣本學(xué)習(xí)并不解決任何問題。如果我們有數(shù)據(jù),那么以往的的深度學(xué)習(xí)就可以了。但是從理論上講,小樣本學(xué)習(xí)可能能做到。

pm-me-your-covfefes表示:
我想說的是,有了足夠的數(shù)據(jù),我們可以找到大多數(shù)問題的解決方案,但這并不能使問題解決(或更容易解決)。
我是美國最大的醫(yī)療保健公司的高級數(shù)據(jù)科學(xué)總監(jiān)。我們很龐大。我們基本上有你想知道的任何事情的數(shù)據(jù)。我懷疑除了中國的醫(yī)療體系之外,沒有其他機構(gòu)擁有比我們更多的醫(yī)療數(shù)據(jù)。
有了這些數(shù)據(jù),我們就可以制作成千上萬的生產(chǎn)模型,這些模型比我在公開場合甚至私下里看到的任何東西都讓人印象深刻。這包括那些試圖進入醫(yī)療行業(yè)的“性感”科技公司所做的一切。
但是,這些模型對改善醫(yī)療保健并不重要。我們有一些模型可以很容易地預(yù)測出每種疾病(甚至是最罕見的疾病)。疾病預(yù)測模型根本不是新穎的。也許10到15年前。這些模型對改善醫(yī)療保健甚至沒有真正的幫助。
以糖尿病預(yù)測模型為例。我不需要一個花哨的模型來告訴我,這個350磅重、每天吃兩個漢堡的不聽話的病人,將會得2型糖尿病。但是,即使當他們被告知“嗨,你應(yīng)該改變你的飲食和生活方式”,他們的病情隨著時間的推移只會變得越來越嚴重和惡化(90%的概率)。這只會讓他們的健康狀況惡化,花更多的錢。
長話短說,至少在醫(yī)療保健領(lǐng)域,即使沒有無限的數(shù)據(jù),我們也可以創(chuàng)建我們想要的所有幻想模型,但這無助于解決問題,因為在大多數(shù)情況下,問題只是人(患者和providers)。我想對于其他依賴于人們做出他們可能不想做的改變的行業(yè)來說,情況也是一樣的。

DoorsofPerceptron表示:“基本上,我認為可以使用無限標記的數(shù)據(jù)和近鄰取樣解決任何問題。如果你有足夠的數(shù)據(jù),那么你應(yīng)該已經(jīng)看過這一場景,你只需查找答案即可。
我們也可以大幅改進現(xiàn)有的深度學(xué)習(xí)方法,僅僅通過在問題上拋出足夠的計算來找到最優(yōu)的架構(gòu)和在搜索空間上的brute forcing,而不是試圖想出一些聰明的東西。(在某種程度上,行業(yè)已經(jīng)做到了這一點,這就是為什么很多最好的架構(gòu)都來自谷歌這樣的地方)。
如果你不需要擔(dān)心計算或數(shù)據(jù),則可以通過關(guān)注探索/利用tradeoff的探索部分來最佳地進行強化學(xué)習(xí)。
因此,將需要更多地限制問題。對于無限的數(shù)據(jù)和無限的計算,我認為我們甚至不需要現(xiàn)代方法來解決所有問題。”

m--w認為:對于現(xiàn)代計算而言,大規(guī)模貝葉斯推理仍然過于昂貴。
談到哪些問題是絕對解決不了的,Phylliida表示:
我們甚至還沒有一個理論模型來解釋如何使技術(shù)奇點發(fā)生。例如,對于許多理論問題,我們可以說“如果我們有一個形式問題X(如P=NP)的解決方案,我們就可以解決這個問題”。對于奇點我們也不能說,因為它還沒有一個正式的定義。即使我們能夠以某種方式解決halting問題,我們也沒有一條清晰的路徑去達到技術(shù)奇點(不,AIXI不是這樣的理論,AIXI描述了一個在一個有明確行動和回報的環(huán)境中的optimal agent)。
對于AGI來說也是如此,盡管在AGI的情況下,至少具有足夠的計算能力和數(shù)據(jù),我們可以通過試圖復(fù)制人類行為來制作人類智能的“duck typed”(如果它看起來像鴨子,并且行為像鴨子,那就是鴨子)模型。我們認為這是使用talktoatransformer進行的小規(guī)模操作,尚不足以進行對話,但是subreddit模擬器GPT2非常逼真,而這正是我們目前擁有的計算能力和數(shù)據(jù)。

Turings_Ego則認為:我認為我們應(yīng)該走另一條路。該領(lǐng)域在很大程度上受到數(shù)據(jù)集/基準測試的經(jīng)驗支持。如果我們真的想解決更復(fù)雜的問題,就需要做大量的工作來理解收斂性和什么不是收斂性。我預(yù)感到拓撲數(shù)據(jù)分析將提供這些證明的一些關(guān)鍵方面。
人工智能進步來自計算力?周志華:絕對錯誤!
再來看看國內(nèi)的AI大佬們是如何看待算力和數(shù)據(jù)的。
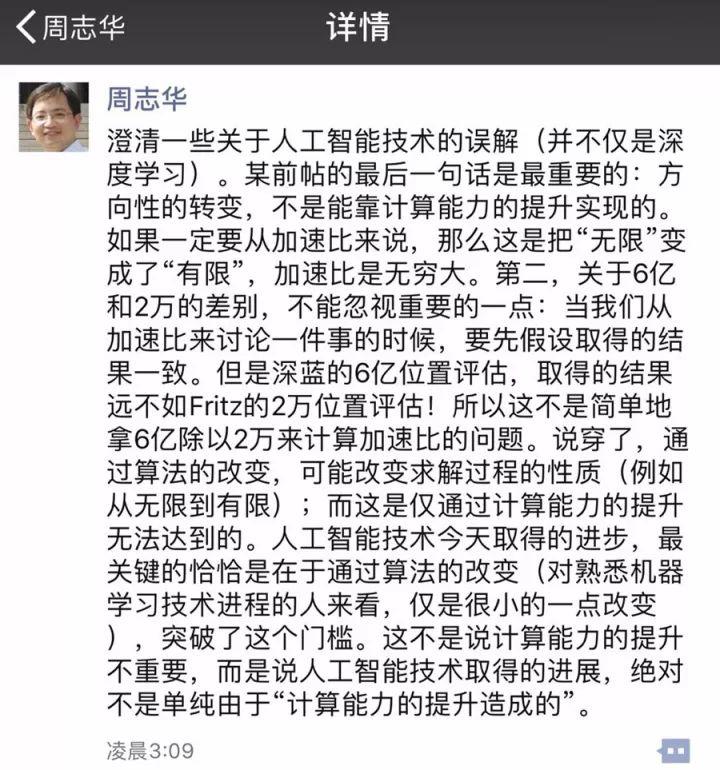
對于“人工智能進步是計算能力帶來的”這種觀點,南大周志華教授曾表示:這個說法絕對錯誤的!周老師將IBM深藍和AlphaGo做對比,深藍下國際象棋每秒需要評估6億個位置,而AlphaGo面對更加復(fù)雜的圍棋,每秒也僅需評估2萬個位置,“從6億到2萬,這是機器學(xué)習(xí)算法帶來的提高,更不用說是計算過程的目標方向已經(jīng)有了根本的改變”。
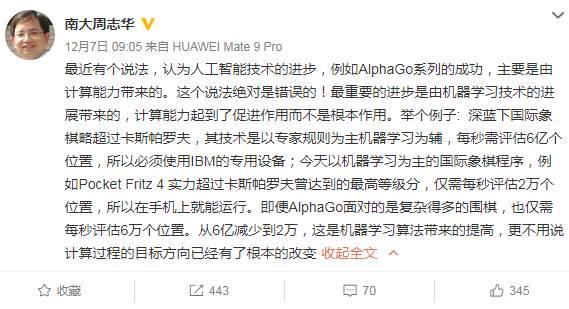
對此,中科院計算所先進計算機系統(tǒng)研究中心主任包云崗回應(yīng),算法起到了至關(guān)重要的作用,而計算力的進步也不可或缺。包云崗用“登月”來類比兩者相輔相成的關(guān)系。“AI進步中算法的作用是導(dǎo)航+一級火箭,計算能力的作用相當于二級+三級火箭”,對于登月缺一不可。包云崗還表示,周老師提供的數(shù)據(jù),從IBM評估6億個位置到AlphaGo評估2萬個,“20年算法效率提高了3萬倍”,客觀展示了算法的進步。
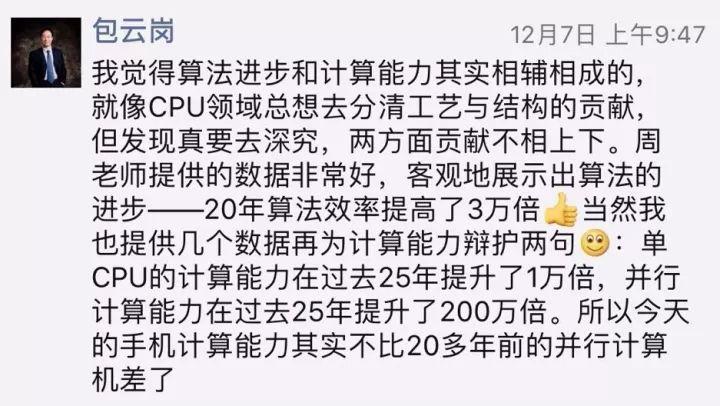
對此,周志華教授表示,不是說計算能力的提升不重要,而是說人工智能技術(shù)取得的進展,絕對不是單純由于“計算能力的提升造成的”。周老師做了進一步闡釋:方向性的轉(zhuǎn)變,不是能靠計算能力的提升實現(xiàn)的。如果算法沒有取得突破,仍然依靠專家規(guī)則,哪怕是研發(fā)出量子計算機來加速也沒有用。
此外,關(guān)于6億和2萬的位置評估,兩者取得的結(jié)果并不一致。因此,不能簡單地拿6億除以2萬來計算加速比。周志華教授說,算法的改變可能改變求解過程的性質(zhì),今天人工智能取得的進步恰恰是通過這一點,而且這是僅通過計算能力的提升無法實現(xiàn)的。
Hinton 認為未來的 AI 系統(tǒng)將主要是無監(jiān)督的。無監(jiān)督學(xué)習(xí)是機器學(xué)習(xí)的一個分支,可以從未標記、未分類的測試數(shù)據(jù)中提取知識 —— 在學(xué)習(xí)共性和對共性是否存在做出反應(yīng)的能力方面,無監(jiān)督學(xué)習(xí)的能力幾乎達到人類水平。
Hinton 說:“如果你采用一個擁有數(shù)十億參數(shù)的系統(tǒng),對某個目標函數(shù)執(zhí)行隨機梯度下降,它的效果會比你想象的好得多…… 規(guī)模越大,效果越好。”
神經(jīng)網(wǎng)絡(luò)和深度學(xué)習(xí)在幾十年前失敗,但是現(xiàn)在卻成功了,原因是什么?而它的局限又在什么地方?賈揚清曾談到:
- 成功的原因,一點是大數(shù)據(jù),一點是高性能計算。
- 局限的原因,一點是結(jié)構(gòu)化的理解,一點是小數(shù)據(jù)上的有效學(xué)習(xí)算法。
阿里巴巴副總裁賈揚清認為:“大量的數(shù)據(jù),比如說移動互聯(lián)網(wǎng)的興起,以及 AWS 這樣低成本獲得標注數(shù)據(jù)的平臺,使機器學(xué)習(xí)算法得以打破數(shù)據(jù)的限制;由于 GPGPU 等高性能運算的興起,又使得我們可以在可以控制的時間內(nèi)(以天為單位甚至更短)進行 exaflop 級別的計算,從而使得訓(xùn)練復(fù)雜網(wǎng)絡(luò)變得可能。要注意的是,高性能計算并不僅限于 GPU ,在 CPU 上的大量向量化計算,分布式計算中的 MPI 抽象,這些都和 60 年代就開始興起的 HPC 領(lǐng)域的研究成果密不可分。
但是,我們也要看到深度學(xué)習(xí)的局限性。今天,很多深度學(xué)習(xí)的算法還是在感知這個層面上形成了突破,可以從語音、圖像,這些非結(jié)構(gòu)化的數(shù)據(jù)中進行識別的工作。在面對更加結(jié)構(gòu)化的問題的時候,簡單地套用深度學(xué)習(xí)算法可能并不能達到很好的效果。有的同學(xué)可能會問為什么 AlphaGo 和 Starcraft 這樣的算法可以成功, 一方面,深度學(xué)習(xí)解決了感知的問題,另一方面,我們也要看到還有很多傳統(tǒng)的非深度學(xué)習(xí)算法,比如說 Q-learning 和其他增強學(xué)習(xí)的算法,一起支撐起了整個系統(tǒng)。而且,在數(shù)據(jù)量非常小的時候,深度學(xué)習(xí)的復(fù)雜網(wǎng)絡(luò)往往無法取得很好的效果,但是很多領(lǐng)域,特別是類似醫(yī)療這樣的領(lǐng)域,數(shù)據(jù)是非常難獲得的,這可能是接下去的一個很有意義的科研方向。
接下去,深度學(xué)習(xí)或者更廣泛地說,AI 這個方向會怎么走?我個人的感覺,雖然大家前幾年一直關(guān)注 AI 框架,但是近年來框架的同質(zhì)化說明了它不再是一個需要花大精力解決的問題,TensorFlow 這樣的框架在工業(yè)界的廣泛應(yīng)用,以及各種框架利用 Python 在建模領(lǐng)域的優(yōu)秀表現(xiàn),已經(jīng)可以幫助我們解決很多以前需要自己編程實現(xiàn)的問題,因此,作為 AI 工程師,我們應(yīng)該跳出框架的桎梏,往更廣泛的領(lǐng)域?qū)ふ覂r值。”