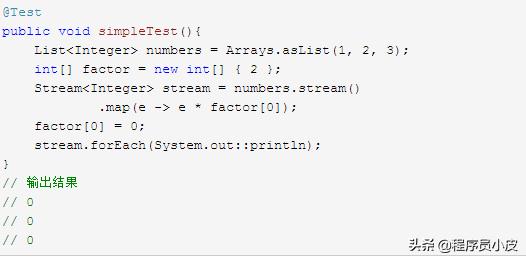
看不懂同事的代碼?超強的 Stream 流操作姿勢還不學習一下
我們都知道 Lambda 和 Stream 是 Java 8 的兩大亮點功能,在前面的文章里已經介紹過 Lambda 相關知識,這次介紹下 Java 8 的 Stream 流操作。它完全不同于 java.io 包的 Input/Output Stream ,也不是大數據實時處理的 Stream 流。這個 Stream 流操作是 Java 8 對集合操作功能的增強,專注于對集合的各種高效、便利、優雅的聚合操作。借助于 Lambda 表達式,顯著的提高編程效率和可讀性。且 Stream 提供了并行計算模式,可以簡潔的編寫出并行代碼,能充分發揮如今計算機的多核處理優勢。
1. Stream 流介紹
Stream 不同于其他集合框架,它也不是某種數據結構,也不會保存數據,但是它負責相關計算,使用起來更像一個高級的迭代器。在之前的迭代器中,我們只能先遍歷然后在執行業務操作,而現在只需要指定執行什么操作, Stream 就會隱式的遍歷然后做出想要的操作。另外 Stream 和迭代器一樣的只能單向處理,如同奔騰長江之水一去而不復返。
由于 Stream 流提供了惰性計算和并行處理的能力,在使用并行計算方式時數據會被自動分解成多段然后并行處理,最后將結果匯總。所以 Stream 操作可以讓程序運行變得更加高效。
2. Stream 流概念
Stream 流的使用總是按照一定的步驟進行,可以抽象出下面的使用流程。
數據源(source) -> 數據處理/轉換(intermedia) -> 結果處理(terminal )
2.1. 數據源
數據源(source)也就是數據的來源,可以通過多種方式獲得 Stream 數據源,下面列舉幾種常見的獲取方式。
- Collection.stream(); 從集合獲取流。
- Collection.parallelStream(); 從集合獲取并行流。
- Arrays.stream(T array) or Stream.of(); 從數組獲取流。
- BufferedReader.lines(); 從輸入流中獲取流。
- IntStream.of() ; 從靜態方法中獲取流。
- Stream.generate(); 自己生成流
2.2. 數據處理
數據處理/轉換(intermedia)步驟可以有多個操作,這步也被稱為intermedia(中間操作)。在這個步驟中不管怎樣操作,它返回的都是一個新的流對象,原始數據不會發生任何改變,而且這個步驟是惰性計算處理的,也就是說只調用方法并不會開始處理,只有在真正的開始收集結果時,中間操作才會生效,而且如果遍歷沒有完成,想要的結果已經獲取到了(比如獲取第一個值),會停止遍歷,然后返回結果。惰性計算可以顯著提高運行效率。
數據處理演示。
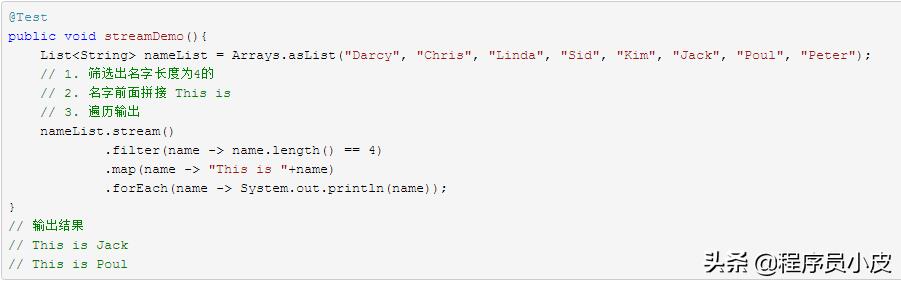
數據處理/轉換操作自然不止是上面演示的過濾 filter 和 map映射兩種,另外還有 map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered 等。
2.3. 收集結果
結果處理(terminal )是流處理的最后一步,執行完這一步之后流會被徹底用盡,流也不能繼續操作了。也只有到了這個操作的時候,流的數據處理/轉換等中間過程才會開始計算,也就是上面所說的惰性計算。結果處理也必定是流操作的最后一步。
常見的結果處理操作有 forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator 等。
下面演示了簡單的結果處理的例子。
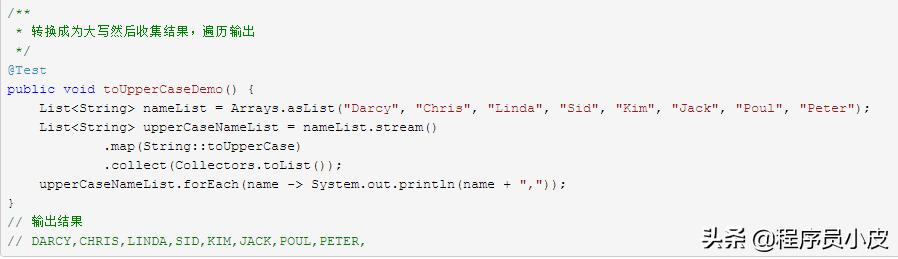
2.4. short-circuiting
有一種 Stream 操作被稱作 short-circuiting ,它是指當 Stream 流無限大但是需要返回的 Stream 流是有限的時候,而又希望它能在有限的時間內計算出結果,那么這個操作就被稱為short-circuiting。例如 findFirst 操作。
3. Stream 流使用
Stream 流在使用時候總是借助于 Lambda 表達式進行操作,Stream 流的操作也有很多種方式,下面列舉的是常用的 11 種操作。
3.1. Stream 流獲取
獲取 Stream 的幾種方式在上面的 Stream 數據源里已經介紹過了,下面是針對上面介紹的幾種獲取 Stream 流的使用示例。

3.2. forEach
forEach 是 Strean 流中的一個重要方法,用于遍歷 Stream 流,它支持傳入一個標準的 Lambda 表達式。但是它的遍歷不能通過 return/break 進行終止。同時它也是一個 terminal 操作,執行之后 Stream 流中的數據會被消費掉。
如輸出對象。

3.3. map / flatMap
使用 map 把對象一對一映射成另一種對象或者形式。
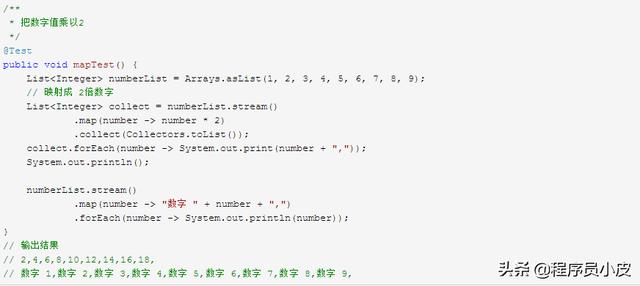
上面的 map 可以把數據進行一對一的映射,而有些時候關系可能不止 1對 1那么簡單,可能會有1對多。這時可以使用 flatMap。下面演示使用 flatMap把對象扁平化展開。

3.4. filter
使用 filter 進行數據篩選,挑選出想要的元素,下面的例子演示怎么挑選出偶數數字。

得到如下結果。
2,4,6,8,
3.5. findFirst
findFirst 可以查找出 Stream 流中的第一個元素,它返回的是一個 Optional 類型,如果還不知道 Optional 類的用處,可以參考之前文章 Jdk14都要出了,還不能使用 Optional優雅的處理空指針? 。

findFirst 方法在查找到需要的數據之后就會返回不再遍歷數據了,也因此 findFirst 方法可以對有無限數據的 Stream 流進行操作,也可以說 findFirst 是一個 short-circuiting 操作。
3.6. collect / toArray
Stream 流可以輕松的轉換為其他結構,下面是幾種常見的示例。

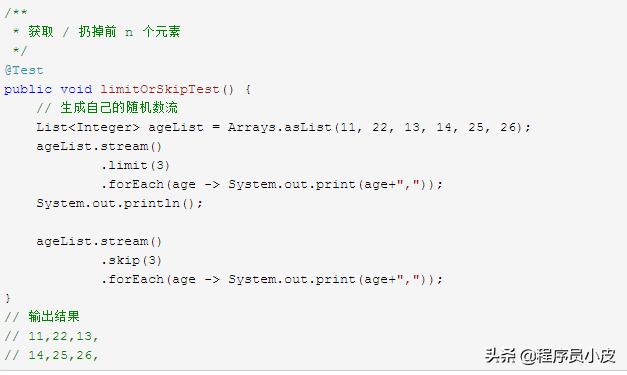
3.7. limit / skip
獲取或者扔掉前 n 個元素
3.8. Statistics
數學統計功能,求一組數組的最大值、最小值、個數、數據和、平均數等。

3.9. groupingBy
分組聚合功能,和數據庫的 Group by 的功能一致。

3.10. partitioningBy

3.11. 進階 - 自己生成 Stream 流
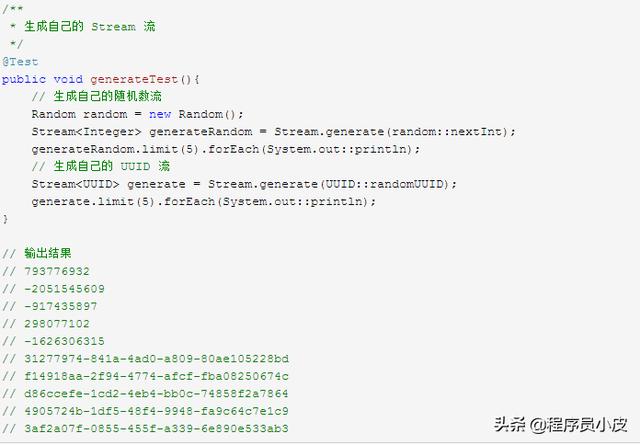
上面的例子中 Stream 流是無限的,但是獲取到的結果是有限的,使用了 Limit 限制獲取的數量,所以這個操作也是 short-circuiting 操作。
4. Stream 流優點
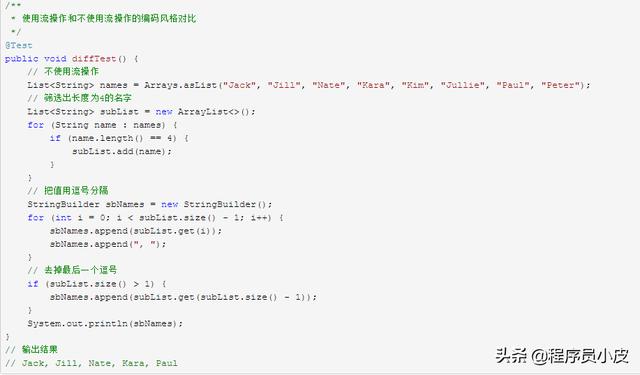
4.1. 簡潔優雅
正確使用并且正確格式化的 Stream 流操作代碼不僅簡潔優雅,更讓人賞心悅目。下面對比下在使用 Stream 流和不使用 Stream 流時相同操作的編碼風格。
如果是使用 Stream 流操作。

4.2. 惰性計算
上面有提到,數據處理/轉換(intermedia) 操作 map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered 等這些操作,在調用方法時并不會立即調用,而是在真正使用的時候才會生效,這樣可以讓操作延遲到真正需要使用的時刻。
下面會舉個例子演示這一點。
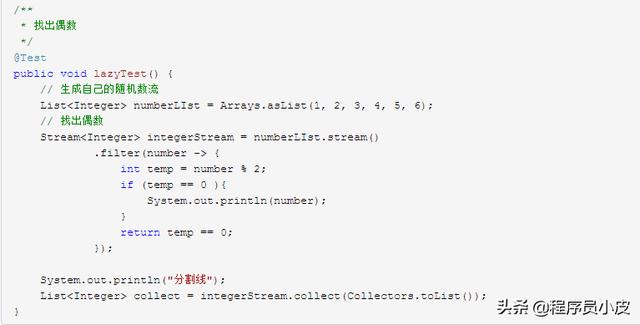
如果沒有 惰性計算,那么很明顯會先輸出偶數,然后輸出 分割線。而實際的效果是。
分割線
2
4
6
可見 惰性計算 把計算延遲到了真正需要的時候。
4.3. 并行計算
獲取 Stream 流時可以使用 parallelStream 方法代替 stream 方法以獲取并行處理流,并行處理可以充分的發揮多核優勢,而且不增加編碼的復雜性。
下面的代碼演示了生成一千萬個隨機數后,把每個隨機數乘以2然后求和時,串行計算和并行計算的耗時差異。

得到如下輸出。

效果顯而易見,代碼簡潔優雅。
5. Stream 流建議
5.1 保證正確排版
從上面的使用案例中,可以發現使用 Stream 流操作的代碼非常簡潔,而且可讀性更高。但是如果不正確的排版,那么看起來將會很糟糕,比如下面的同樣功能的代碼例子,多幾層操作呢,是不是有些讓人頭大?

5.1 保證函數純度
如果想要你的 Stream 流對于每次的相同操作的結果都是相同的話,那么你必須保證 Lambda 表達式的純度,也就是下面亮點。
- Lambda 中不會更改任何元素。
- Lambda 中不依賴于任何可能更改的元素。
這兩點對于保證函數的冪等非常重要,不然你程序執行結果可能會變得難以預測,就像下面的例子。