超好用的自信學(xué)習(xí):1行代碼查找標(biāo)簽錯誤,3行代碼學(xué)習(xí)噪聲標(biāo)簽
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
你知道嗎?就連ImageNet中也可能至少存在10萬個標(biāo)簽問題。
在大量的數(shù)據(jù)集中去描述或查找標(biāo)簽錯誤本身就是挑戰(zhàn)性超高的任務(wù),多少英雄豪杰為之頭痛不已。
最近,MIT和谷歌的研究人員便提出了一種廣義的自信學(xué)習(xí)(Confident Learning,CL)方法,可以直接估計給定標(biāo)簽和未知標(biāo)簽之間的聯(lián)合分布。
這種廣義的CL,也是一個開源的Clean Lab Python包,在ImageNet和CIFAR上的性能比其他前沿技術(shù)高出30%。
這種方法有多厲害?舉個栗子。
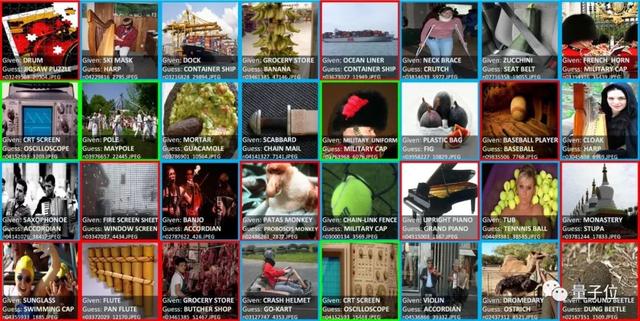
上圖是2012年ILSVRC ImageNet訓(xùn)練集中使用自信學(xué)習(xí)發(fā)現(xiàn)的標(biāo)簽錯誤示例。研究人員將CL發(fā)現(xiàn)的問題分為三類:
1、藍(lán)色:圖像中有多個標(biāo)簽;
2、綠色:數(shù)據(jù)集中應(yīng)該包含一個類;
3、紅色:標(biāo)簽錯誤。
通過自信學(xué)習(xí),就可以在任何數(shù)據(jù)集中使用合適的模型來發(fā)現(xiàn)標(biāo)簽錯誤。下圖是其他三個常見數(shù)據(jù)集中的例子。

△目前存在于Amazon Reviews、MNIST和Quickdraw數(shù)據(jù)集中的標(biāo)簽錯誤的例子,這些數(shù)據(jù)集使用自信學(xué)習(xí)來識別不同的數(shù)據(jù)模式和模型。
這么好的方法,還不速來嘗鮮?
什么是自信學(xué)習(xí)?
自信學(xué)習(xí)已然成為監(jiān)督學(xué)習(xí)的一個子領(lǐng)域。
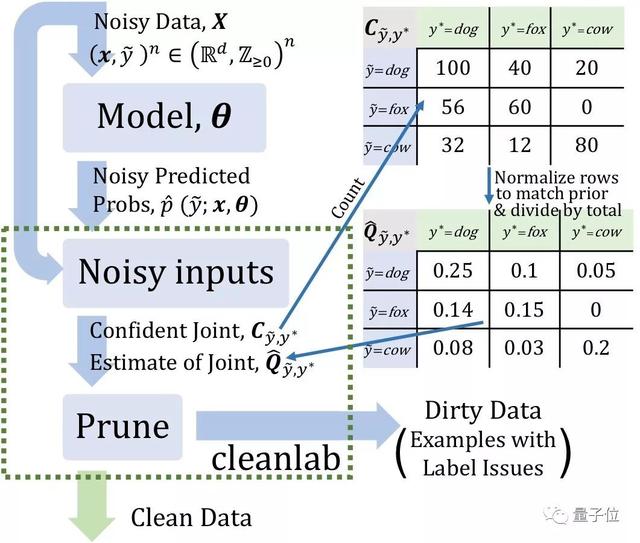
從上圖不難看出,CL需要2個輸入:
1、樣本外預(yù)測概率;
2、噪聲標(biāo)簽;
對于弱監(jiān)督而言,CL包括三個步驟:
1、估計給定的、有噪聲的標(biāo)簽和潛在的(未知的)未損壞標(biāo)簽的聯(lián)合分布,這樣就可以充分描述類條件標(biāo)簽噪聲;
2、查找并刪除帶有標(biāo)簽問題的噪聲(noisy)示例;
3、進(jìn)行消除錯誤的訓(xùn)練,然后根據(jù)估計的潛在先驗重新加權(quán)示例。
那么CL的工作原理又是什么呢?
我們假設(shè)有一個數(shù)據(jù)集包含狗、狐貍和奶牛的圖像。CL的工作原理就是估計噪聲標(biāo)簽和真實標(biāo)簽的聯(lián)合分布(下圖中右側(cè)的Q矩陣)。
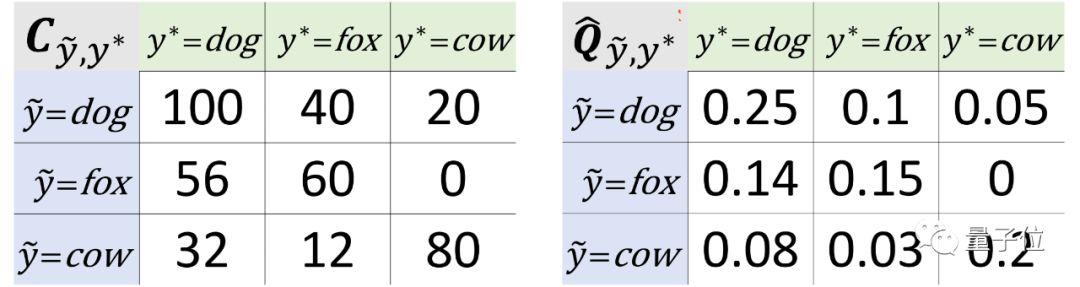
△左:自信計數(shù)的示例;右:三類數(shù)據(jù)集的噪聲標(biāo)簽和真實標(biāo)簽的聯(lián)合分布示例。
接下來,CL計數(shù)了100張被標(biāo)記為“狗”的圖像,這些圖像就很可能是“狗”類(class dog),如上圖左側(cè)的C矩陣所示。
CL還計數(shù)了56張標(biāo)記為狗,但高概率屬于狐貍的圖像,以及32張標(biāo)記為狗,但高概率屬于奶牛的圖像。
而后的中心思想就是,當(dāng)一個樣本的預(yù)測概率大于每個類的閾值時,我們就可以自信地認(rèn)為這個樣本是屬于這個閾值的類。
此外,每個類的閾值是該類中樣本的平均預(yù)測概率。
輕松上手Clean Lab
剛才也提到,本文所說的廣義CL,其實是一個Clean Lab Python包。而它之所以叫Clean Lab,是因為它能“clean”標(biāo)簽。
Clean Lab具有以下優(yōu)勢:
速度快:單次、非迭代、并行算法(例如,不到1秒的時間就可以查找ImageNet中的標(biāo)簽錯誤);
魯棒性:風(fēng)險最小化保證,包括不完全概率估計;
通用性:適用于任何概率分類器,包括 PyTorch、Tensorflow、MxNet、Caffe2、scikit-learn等;
獨特性:唯一用于帶有噪聲標(biāo)簽或查找任何數(shù)據(jù)集/分類器標(biāo)簽錯誤的多類學(xué)習(xí)的軟件包。
1行代碼就查找標(biāo)簽錯誤!
3行代碼學(xué)習(xí)噪聲標(biāo)簽!
接下來,是Clean Lab在MNIST上表現(xiàn)。可以在這個數(shù)據(jù)集上自動識別50個標(biāo)簽錯誤。

原始MNIST訓(xùn)練數(shù)據(jù)集的標(biāo)簽錯誤使用rankpruning算法進(jìn)行識別。描述24個最不自信的標(biāo)簽,從左到右依次排列,自頂向下增加自信(屬于給定標(biāo)簽的概率),在teal中表示為conf。預(yù)測概率最大的標(biāo)簽是綠色的。明顯的錯誤用紅色表示。
傳送門
項目地址:
https://github.com/cgnorthcutt/cleanlab/
自信學(xué)習(xí)博客:
https://l7.curtisnorthcutt.com/confident-learning