Netflix應用架構之用于個性化和推薦的系統架構
本文我們將探索如何創建一個能夠交付并支持快速創新的軟件架構。提出一種能夠處理大量現有數據、響應用戶交互并易于試驗新的推薦方法的軟件體系結構并非易事。在這篇文章中,我們將描述我們如何解決Netflix面臨的一些挑戰。
首先,我們在下圖中展示了推薦系統的總體系統圖。該體系結構的主要組件包含一個或多個機器學習算法。
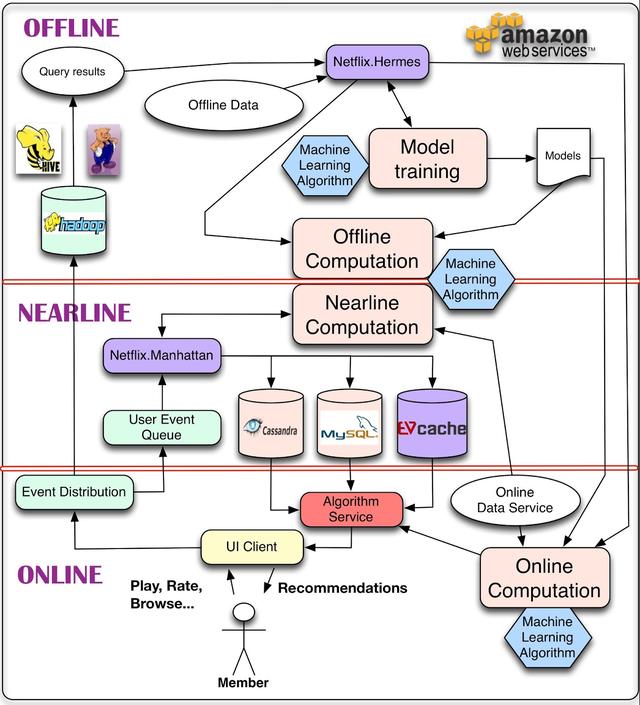
對于數據,我們能做的最簡單的事情就是將其存儲起來,以便稍后進行脫機處理,這就引出了管理脫機作業的部分體系結構。然而,計算可以離線、近線或在線進行。在線計算可以更好地響應最近的事件和用戶交互,但必須實時響應請求。這可以限制所使用算法的計算復雜度以及可處理的數據量。離線計算對數據量和算法的計算復雜度的限制較小,因為它以批處理方式運行,對時間的要求比較寬松。但是,由于沒有包含最新的數據,在更新的過程中很容易變得陳舊。
個性化體系結構中的一個關鍵問題是如何以無縫的方式組合和管理在線和離線計算。近線計算是這兩種模式之間的一種折衷,在這種模式下,我們可以執行類似于在線的計算,但不要求它們是實時的。模型訓練是使用現有數據生成模型的另一種計算形式,該模型稍后將在實際計算結果時使用。體系結構的另一部分描述了事件和數據分發系統需要如何處理不同類型的事件和數據。一個相關的問題是如何組合不同的信號和模型,這些信號和模型是離線、近線和在線系統所需要的。最后,我們還需要找出如何以一種對用戶有意義的方式組合中間推薦結果。
本文的其余部分將詳細介紹此體系結構的這些組件及其交互。為了做到這一點,我們將把一般的圖分解成不同的子系統,并且我們將詳細討論每一個子系統。當您繼續閱讀本文時,值得記住的是,我們的整個基礎設施都運行在公共Amazon Web Services云上。
Offline, Nearline, and Online Computation
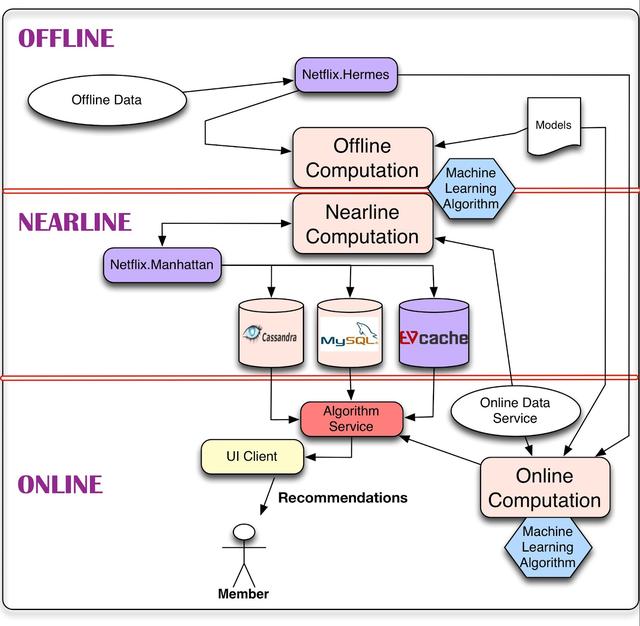
如上所述,我們的算法結果既可以在線實時計算,也可以離線批量計算,或者在兩者之間的近線計算。每種方法都有其優點和缺點,需要考慮到每種用例。
在線計算可以快速響應事件并使用最新的數據。例如,使用當前上下文為成員組裝一個動作電影庫。在線組件受可用性和響應時間服務級別協議(SLA)的約束,SLA指定了在我們的成員等待建議出現時響應客戶端應用程序請求的流程的最大延遲。這使得用這種方法來擬合復雜且計算量大的算法變得更加困難。此外,在某些情況下,純在線計算可能無法滿足其SLA,因此考慮快速回退機制(如恢復到預計算結果)總是很重要的。在線計算還意味著所涉及的各種數據源也需要在線可用,這可能需要額外的基礎設施。
另一方面,離線計算允許在算法方法上有更多的選擇,比如復雜的算法,并且對使用的數據量有更少的限制。一個簡單的例子可能是定期聚合來自數百萬電影播放事件的統計數據,以編譯推薦的基準流行度指標。離線系統也有更簡單的工程需求。例如,可以很容易地滿足客戶機施加的寬松響應時間sla。可以在生產環境中部署新的算法,而不需要在性能調優方面投入太多精力。這種靈活性支持敏捷創新。在Netflix,我們利用這個來支持快速實驗:如果一個新的實驗算法執行慢,我們可以選擇簡單的部署更多的Amazon EC2實例來達到所需的吞吐量運行實驗,而不是花費寶貴的工程時間算法的優化性能,可能小的業務價值。然而,由于離線處理沒有很強的延遲需求,它不會對上下文或新數據中的更改做出快速反應。最終,這可能導致過時,降低成員的體驗。離線計算還需要存儲、計算和訪問大量預計算結果集的基礎設施。
近線計算可以看作是前兩種模式的折衷。在本例中,計算的執行與在線情況完全相同。但是,我們刪除了在計算結果時立即提供結果的需求,并可以存儲它們,從而允許它是異步的。近線計算是根據用戶事件進行的,因此系統可以在請求之間做出更快速的響應。這為每個事件可能進行的更復雜的處理打開了大門。例如,更新建議,以反映在成員開始觀看電影之后,電影已經立即被觀看。結果可以存儲在中間緩存或后端存儲中。近線計算也是應用增量學習算法的一種自然設置。
在任何情況下,選擇聯機/近線/脫機處理都不是一個非此即非的問題。所有的方法都可以而且應該結合起來。組合它們的方法有很多。我們已經提到了使用離線計算作為備份的想法。另一種選擇是使用離線進程預先計算結果的一部分,而將算法中成本較低或上下文敏感的部分留給在線計算。
甚至建模部分也可以以離線/在線混合方式完成。在傳統的監督分類應用中,分類器必須從標記數據批量訓練,并且只能在線應用于對新輸入進行分類,這并不自然適合。然而,矩陣分解等方法更自然地適合于混合的在線/離線建模:一些因素可以離線預先計算,而另一些可以實時更新,以創建更新鮮的結果。其他非監督方法,如集群,也允許離線計算集群中心和在線分配集群。這些例子表明,一方面可以將我們的模型培訓劃分為大規模的、潛在復雜的全局模型培訓,另一方面可以在線執行更輕松的特定于用戶的模型培訓或更新階段。
Offline Jobs
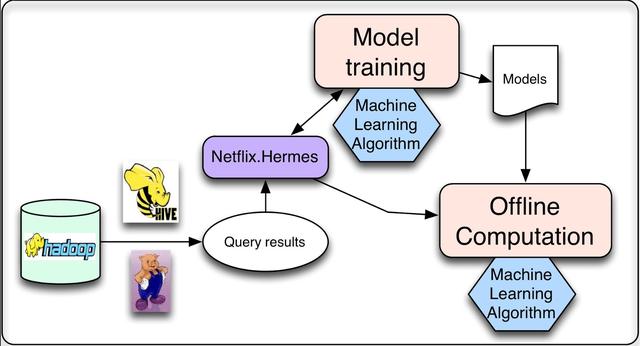
當運行個性化機器學習算法時,我們需要做的大部分計算都可以離線完成。這意味著可以將作業計劃為定期執行,并且它們的執行不需要與結果的請求或表示同步。這類任務主要有兩類:模型訓練和中間結果或最終結果的批處理計算。在模型訓練工作中,我們收集相關的現有數據,應用機器學習算法生成一組模型參數(我們將其稱為模型)。這個模型通常會被編碼并存儲在一個文件中供以后使用。雖然大多數模型都是離線批處理模式培訓的,但我們也有一些在線學習技術,其中增量培訓確實是在線執行的。批量計算結果是上面定義的離線計算過程,我們使用現有的模型和相應的輸入數據來計算結果,這些結果將在稍后用于后續的在線處理或直接呈現給用戶。
這兩個任務都需要處理精制的數據,而這些數據通常是通過運行數據庫查詢生成的。由于這些查詢運行在大量數據上,因此以分布式方式運行它們是有益的,這使得它們非常適合通過Hive或Pig作業在Hadoop上運行。一旦查詢完成,我們就需要一種發布結果數據的機制。我們對該機制有幾個要求:首先,當查詢結果準備好時,它應該通知訂閱者。其次,它應該支持不同的存儲庫(例如,不僅支持HDFS,還支持S3或Cassandra)。最后,它應該透明地處理錯誤,允許監視和警報。在Netflix,我們使用一個名為Hermes的內部工具,它提供所有這些功能,并將它們集成到一個一致的發布-訂閱框架中。它允許向訂閱者提供近乎實時的數據。在某種意義上,它涵蓋了與Apache Kafka相同的一些用例,但它不是消息/事件隊列系統。
信號和模型
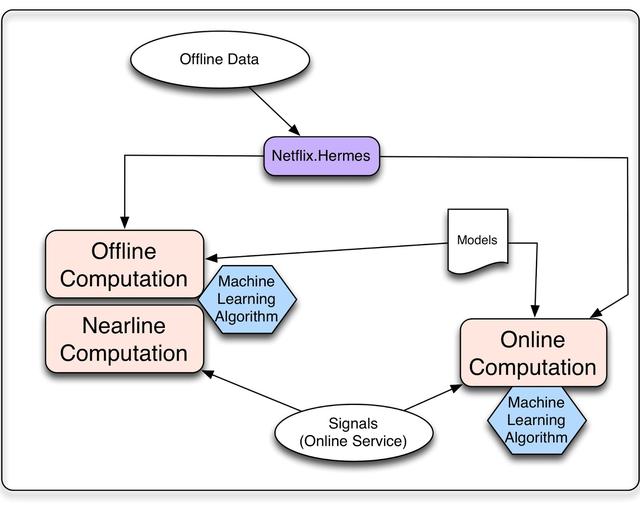
無論我們是在線計算還是離線計算,我們都需要考慮算法將如何處理三種輸入:模型、數據和信號。模型通常是之前離線訓練的參數的小文件。數據是預先處理的信息,這些信息已經存儲在某種數據庫中,比如電影元數據或流行度。我們使用"信號"這個術語來指代我們輸入到算法中的新信息。這些數據來自live services,可以由用戶相關的信息(如成員最近觀看了什么)或上下文數據(如會話、設備、日期或時間)組成。
Event & Data Distribution
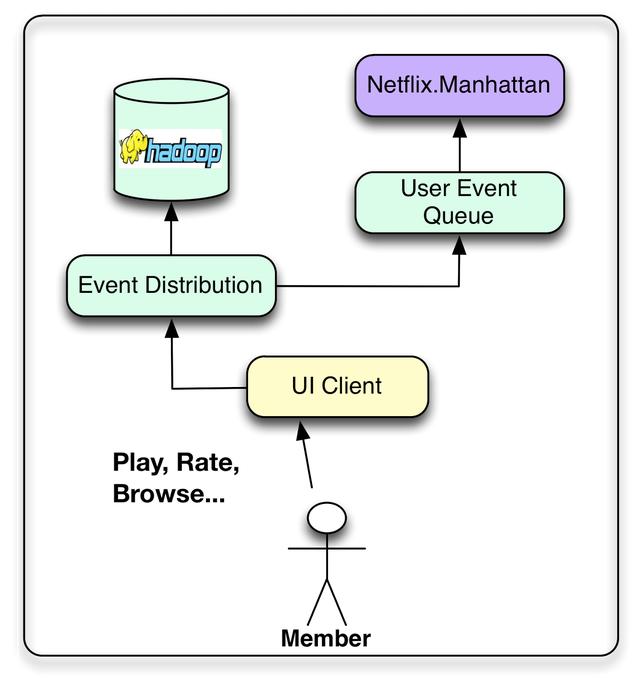
我們的目標是將成員交互數據轉換為可用于改進成員體驗的洞察力。因此,我們希望Netflix的各種用戶界面應用程序(智能電視、平板電腦、游戲機等)不僅能提供令人愉快的用戶體驗,還能收集盡可能多的用戶事件。這些操作可以與任何時候的單擊、瀏覽、查看,甚至是視圖的內容相關。然后可以聚合事件,為我們的算法提供基本數據。在這里,我們試圖在數據和事件之間做出區分,盡管邊界肯定是模糊的。我們認為事件是時間敏感信息的小單元,需要以盡可能少的延遲處理。這些事件被路由來觸發后續的操作或過程,例如更新近線結果集。另一方面,我們認為數據是更密集的信息單元,可能需要處理和存儲以便稍后使用。在這里,延遲并不像信息的質量和數量那么重要。當然,有些用戶事件可以同時作為事件和數據處理,因此可以發送到兩個流。
在Netflix,我們近乎實時的活動流程是通過一個名為Manhattan的內部框架來管理的。曼哈頓是一個分布式計算系統,它是我們推薦算法體系結構的核心。這有點類似于Twitter的Storm,但它解決了不同的問題,并響應了不同的一組內部需求。數據流主要通過從Chukwa到Hadoop的日志記錄來管理,以完成流程的初始步驟。稍后,我們使用Hermes作為發布-訂閱機制。
推薦結果
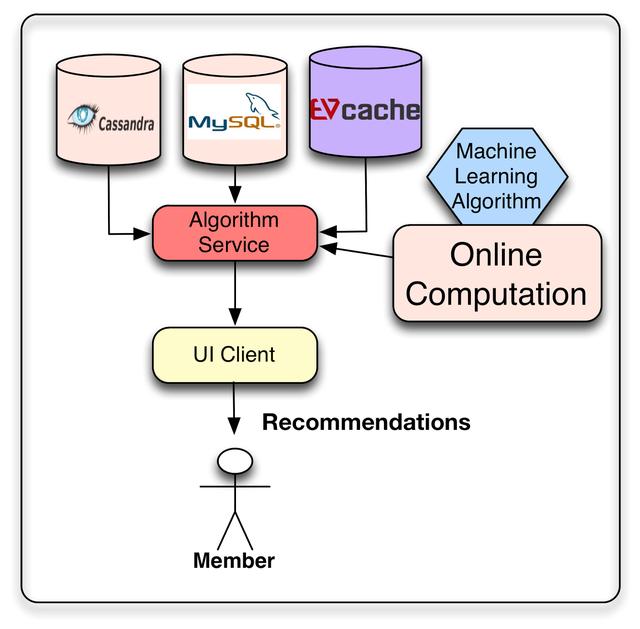
我們機器學習方法的目標是提出個性化的建議。這些推薦結果可以直接從我們之前計算過的列表中得到,也可以通過在線算法動態生成。當然,我們可以考慮同時使用這兩種方法,離線計算推薦的大部分內容,并使用使用實時信號的在線算法對列表進行后處理,從而增加一些新鮮度。
在Netflix,我們將離線和中間結果存儲在各種存儲庫中,以便稍后在請求時使用:我們使用的主要數據存儲庫是Cassandra、EVCache和MySQL。每種解決方案都有其優缺點。MySQL允許存儲結構化關系數據,這些數據將來可能需要通過通用查詢進行處理。然而,這種通用性是以分布式環境中的可伸縮性問題為代價的。Cassandra和EVCache都提供了鍵值存儲的優點。當需要分布式和可伸縮的無sql存儲時,Cassandra是一個著名的標準解決方案。Cassandra在某些情況下工作得很好,但是在我們需要密集且持續的寫操作的情況下,我們發現EVCache更適合。然而,關鍵問題不在于將它們存儲在哪里,而在于如何以一種相互沖突的目標(如查詢復雜性、讀寫延遲和事務一致性)在每個用例的最優點上滿足的方式處理需求。
結論
在以前的文章中,我們強調了數據、模型和用戶界面對于創建世界級推薦系統的重要性。在構建這樣一個系統時,還必須考慮將在其中部署該系統的軟件體系結構。我們希望能夠使用復雜的機器學習算法,可以增長到任意的復雜性,并能夠處理大量的數據。我們還需要一個允許靈活和敏捷創新的體系結構,在這個體系結構中可以輕松地開發和插入新方法。此外,我們希望我們的推薦結果是新鮮的,并快速響應新的數據和用戶操作。在這些需求之間找到最佳平衡點并非易事:它需要對需求進行深思熟慮的分析,仔細選擇技術,并對推薦算法進行戰略性分解,從而為我們的成員實現最佳結果。