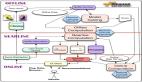
強大!SpringBoot3.4 整合 Flink,打造高效用戶個性化推薦系統(tǒng)!
在如今大數(shù)據(jù)時代,如何高效地處理大量的實時數(shù)據(jù)并從中提取出有價值的信息,已經成為各大企業(yè)面臨的核心挑戰(zhàn)之一。尤其是在用戶個性化推薦領域,實時數(shù)據(jù)流的處理能力對于提供準確、及時的推薦結果至關重要。Spring Boot作為廣泛應用的后端框架,以其高效、易用的特性,成為了構建微服務架構和處理復雜業(yè)務邏輯的首選。而Flink作為一款高性能的流處理引擎,能夠以毫秒級延遲處理海量數(shù)據(jù),特別適合實時推薦、欺詐檢測、實時分析等場景。
本篇文章將帶你深入探討如何結合Spring Boot 3.4與Apache Flink,構建一個高效、可擴展的用戶個性化推薦系統(tǒng)。我們將從如何集成Flink到Spring Boot項目,如何利用Flink處理實時用戶行為數(shù)據(jù),到最終如何生成個性化推薦并反饋給用戶,逐步展示這一解決方案的實現(xiàn)過程。在此過程中,我們還會講解一些典型應用場景,幫助讀者深入理解流處理技術的巨大潛力,尤其是如何通過技術優(yōu)化提升用戶體驗,增強企業(yè)的競爭力。以下是幾種常見的應用場景:
- 個性化推薦系統(tǒng)實時處理用戶行為數(shù)據(jù),動態(tài)更新用戶畫像并提供個性化的產品推薦。
- 事件驅動架構在微服務架構中處理跨服務消息,確保系統(tǒng)保持低延遲和高吞吐量。
- 欺詐檢測實時分析金融交易或網絡活動,識別并報警異常行為,減少潛在的損失。
- 流數(shù)據(jù)分析實時處理來自傳感器或物聯(lián)網設備的海量數(shù)據(jù),分析用戶行為,及時反饋信息。
- 日志處理對系統(tǒng)日志進行實時收集、解析和聚合,幫助開發(fā)者優(yōu)化系統(tǒng)性能和排查故障。
- 實時報表生成生成實時的銷售報告、市場趨勢等,幫助決策者做出快速反應。
- 供應鏈管理實時監(jiān)控庫存、訂單及物流信息,自動調整生產計劃以響應需求變化。
- 社交媒體分析實時分析輿情,監(jiān)測公眾對品牌或話題的情緒反饋。
- 網絡安全通過實時監(jiān)控網絡流量,檢測并應對安全威脅。
代碼演示:如何根據(jù)用戶的行為實時生成個性化推薦
以下演示了如何通過SpringBoot和Flink的結合,處理Kafka中的用戶行為數(shù)據(jù),并生成個性化推薦結果。
添加必要的依賴
在pom.xml中添加以下依賴:
<dependencies>
<!-- Spring Boot Web Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Flink dependencies -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.6</version>
</dependency>
<!-- Jackson JSON processing -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
</dependencies>數(shù)據(jù)模型定義
定義兩個模型類,用于表示用戶行為數(shù)據(jù)和推薦結果。
package com.icoderoad.demo.model;
public class UserBehavior {
private String userId;
private String productId;
private String action; // 如: "view", "click", "purchase"
private long timestamp;
// Getters and setters
}
package com.icoderoad.demo.model;
import java.util.List;
public class RecommendationResult {
private String userId;
private List<String> recommendedProducts;
// Getters and setters
}編寫Flink作業(yè)
使用Flink從Kafka中讀取用戶行為數(shù)據(jù),計算熱門產品,并生成個性化推薦。
package com.icoderoad.demo;
import com.icoderoad.demo.model.RecommendationResult;
import com.icoderoad.demo.model.UserBehavior;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class RecommendationJob {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("user-behavior-topic", new SimpleStringSchema(), properties);
kafkaConsumer.setStartFromEarliest();
ObjectMapper objectMapper = new ObjectMapper();
DataStream<UserBehavior> userBehaviors = env.addSource(kafkaConsumer)
.map((MapFunction<String, UserBehavior>) value -> objectMapper.readValue(value, UserBehavior.class));
DataStream<Tuple2<String, Map<String, Integer>>> productCountsPerUser = userBehaviors
.filter(behavior -> behavior.getAction().equals("purchase"))
.keyBy(UserBehavior::getUserId)
.flatMap((value, out) -> {
Map<String, Integer> productCounts = new HashMap<>();
productCounts.put(value.getProductId(), productCounts.getOrDefault(value.getProductId(), 0) + 1);
out.collect(Tuple2.of(value.getUserId(), productCounts));
})
.keyBy(Tuple2::f0)
.reduce((t1, t2) -> {
t1.f1.forEach((productId, count) -> t2.f1.merge(productId, count, Integer::sum));
return t1;
});
DataStream<RecommendationResult> recommendations = productCountsPerUser
.map((MapFunction<Tuple2<String, Map<String, Integer>>, RecommendationResult>) value -> {
RecommendationResult result = new RecommendationResult();
result.setUserId(value.f0);
List<String> recommendedProducts = new ArrayList<>(value.f1.keySet());
result.setRecommendedProducts(recommendedProducts.subList(0, Math.min(5, recommendedProducts.size())));
return result;
});
FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<>("recommendations-topic",
(RecommendationResult recommendation) -> objectMapper.writeValueAsString(recommendation),
properties);
recommendations.map(ObjectMapper::writeValueAsString).addSink(kafkaProducer);
env.execute("Recommendation Job");
}
}啟動Spring Boot應用
創(chuàng)建一個Spring Boot應用程序來啟動Flink作業(yè):
package com.icoderoad.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Bean
public Runnable flinkRunner() {
return () -> {
try {
RecommendationJob.main(new String[]{});
} catch (Exception e) {
throw new RuntimeException(e);
}
};
}
}測試
確保您的Kafka和其他相關服務已經設置好,然后向user-behavior-topic發(fā)送消息,如下所示:
{"userId":"user1","productId":"productA","action":"purchase","timestamp":1672531200000}
{"userId":"user1","productId":"productB","action":"purchase","timestamp":1672531200000}
{"userId":"user2","productId":"productB","action":"purchase","timestamp":1672531200000}檢查recommendations-topic中的消息,您將看到個性化推薦結果:
{"userId":"user1","recommendedProducts":["productA","productB"]}
{"userId":"user2","recommendedProducts":["productB"]}通過這一系列的步驟,您已經完成了一個基于SpringBoot與Flink集成的高效個性化推薦系統(tǒng)!
結論:
通過Spring Boot與Flink的深度結合,我們可以高效、實時地處理用戶行為數(shù)據(jù),進而為用戶提供精準的個性化推薦。在本文中,我們不僅介紹了如何通過Flink從Kafka讀取實時數(shù)據(jù)并處理,還展示了如何根據(jù)用戶的行為生成推薦結果并返回給系統(tǒng)。借助Flink強大的流處理能力,企業(yè)能夠在瞬息萬變的市場環(huán)境中迅速響應用戶需求,提供個性化的服務,從而提升用戶滿意度和粘性。
不僅如此,這一系統(tǒng)還具備了極高的可擴展性,可以應對不同規(guī)模的數(shù)據(jù)流并保證系統(tǒng)的高可用性。這為大數(shù)據(jù)時代的企業(yè)提供了一種可持續(xù)發(fā)展的解決方案,使其能夠在海量的數(shù)據(jù)中提煉出真正的商業(yè)價值。
展望未來,隨著數(shù)據(jù)量的不斷增長和實時數(shù)據(jù)處理需求的日益增加,Spring Boot與Flink的結合將成為更多企業(yè)實現(xiàn)高效數(shù)據(jù)流處理、個性化推薦和實時決策的核心技術。本文所述的架構和實現(xiàn)方式,展示了技術如何驅動商業(yè)創(chuàng)新,也為企業(yè)在數(shù)字化轉型過程中提供了一個重要的參考模型。