













純技術干貨分享:分布式事務處理方式總結
在項目開發中,經常會需要處理分布式事務。例如數據庫分庫分表之后,原來在一個單庫上的操作可能會跨越多個數據庫。系統服務化拆分之后,原來的在一個系統上的操作可能會跨越多個系統。就連我們平時經常使用到的緩存(如redis、memcache等)也可能涉及分布式事務,因為緩存和數據庫是兩個不同的實體,如何保證數據在緩存和數據庫間的一致性也是要重點考慮的。分布式事務就是指事務要處理的資源分別位于分布式系統中的不同節點之上的事務。
對于單機系統,通常我們借助數據庫實現本地事務,例如下面JDBC代碼實現了一個事務:
- Connection con = datasource.getConnection();
- con.setAutoCommit(false);
- ...
- 執行CRUD操作,可能會涉及到多個表
- ...
- con.commit()/con.rollback()
由于在分布式系統中,多個系統無法共用同一個數據庫鏈接,所以無法簡單借用上面的處理方式實現分布式事務。
下面將介紹幾種本人在實際開發中使用過的處理分布式事務的方式,最后再引出分布式事務的相關理論并進行總結。
避免出現分布式事務
由于分布式事務比較難于處理,所以應該盡量避免分布式事務的發生。例如對于一個客戶信息系統,由于注冊用戶數太多導致存儲的數據量過大,所以對其進行分庫分表存儲。而客戶信息模型又分為多個子模型,對應數據庫中的多個表,例如客戶基本信息表、客戶登錄賬號表、客戶登錄密碼表、客戶聯系方式表等等。假設登錄賬號表和客戶基本信息表的關聯關系如下所示:
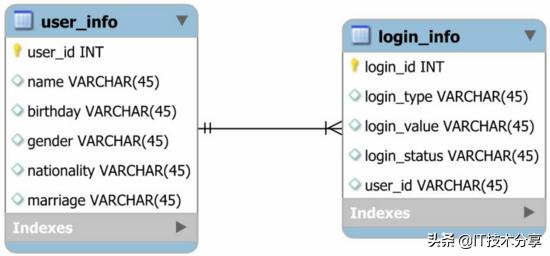
user_id和login_id分別是兩個表的主鍵,user_id還作為login_info表的外鍵使兩個表關聯。在用戶注冊時會自動生成user_id和login_id的值。 user_info和login_info兩個表分別采用user_id和login_id計算分庫分表規則 。假設我們對每個模型分十庫一百表存儲,即存在user_info_00 ~ user_info_99一百個表,其中user_info_00 ~ user_info_09屬于第一個庫,user_info_10 ~ user_info_19屬于第二個庫,依次類推。
在分庫分表之后,如果我們不仔細的考慮user_id和login_id的生成規則(例如隨意生成一個數字字符串或簡單使用遞增sequence),就可能導致同一個用戶的user_info信息和login_info信息被存儲到兩個不同的庫,這就會導致分布式事務發生。
面對這種問題,最好的解決思路就是考慮如何避免分布式事務的發生。只要想辦法讓跟一個用戶相關的所有模型數據全部存入到一個庫中,就可以避免分布式事務了。由于每個模型數據的分庫分表路由規則又是由各個表的主鍵id決定的(例如user_id、login_id),所以只要對各個表的主鍵生成規則進行定制,就可以保證一個用戶的所有模型數據全部存到同一個庫。假設有下面的id生成規則:

- 開始的兩位是標識模型位,例如user_id以01開頭,login_id以02開頭。
- 接下來的11位是sequence遞增序列號,如果想要更多的ID可以擴大這部分的位數,但對于存儲用戶信息而言,11位的長度足夠。
- 接下來是分庫分表位,如果每個模型的分庫分表算法都相同,那么只要保證每個模型的主鍵ID的分庫分表位都相同,就能保證一個用戶的所有模型數據都會存到同一個庫中。
- 最后一位是id校驗位,這一位根據前面15位的內容生成,方便對一個id進行校驗。
根據這個思想,我們可以在用戶注冊的時候先生成user_id,user_id的分庫分表位可以隨機生成。然后在為其它模型生成主鍵id時(例如login_id),必須讓這個模型的主鍵id的分庫分表位與user_id的分庫分表位相同。另外一點也要注意,一個表的查詢條件不一定只有主鍵id一個,如果有其它查詢條件列,那就要保證那一列的生成規則也要包含相同的分庫分表位,否則就不能使用該列進行查詢。
通過這種方式,就可以保證一個用戶的所有模型數據全部存儲到同一個庫中,有效的避免分布式事務的發生。
事務補償
通常情況下,應對高并發的一個主要手段就是增加分布式緩存(如redis)以提高查詢性能。增加分布式緩存后系統查詢數據的流程如下圖:
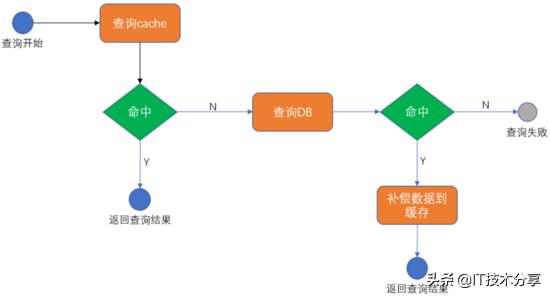
即先嘗試從緩存中查詢數據,如果緩存命中就直接返回結果,否則嘗試從DB中查詢數據。如果查詢DB命中則將數據補充到緩存,以備下次查詢時可以命中緩存。
而在更新數據時,通常是先更新DB中的數據,DB寫入成功后再更新緩存中的數據。那么就有一個問題, 如何保證緩存和DB間數據的一致性? 由于緩存和DB是兩個不同的實體,寫入DB成功后再去更新緩存,如果緩存更新失敗(例如網絡抖動造成短暫的緩存不可用)就會造成緩存和DB的不一致。此時按照上圖的查詢邏輯,先查緩存就會查詢到“臟”的數據,就會嚴重影響業務。這也是一個典型的分布式事務問題——緩存和DB要嘛同時更新成功,要嘛同時更新失敗。解決這個問題的一個較好方式就是事務補償。
我們可以在DB中創建一張事務補償表transaction_log,transaction_log表可以和業務數據在一個庫中,也可以在不同的庫。在更新數據前,先將要更新的模型數據記錄到transaction_log中。例如我們更新user_info表中的數據,就將userId記錄到transaction_log中。
transaction_log記錄成功后,再去更新業務數據表user_info中的內容,最后更新緩存中的userInfo數據。緩存更新成功后,就可以刪除transaction_log表中對應的記錄。
假設在更新完user_info表之后,由于網絡抖動等原因導致緩存更新失敗,則transaction_log表中對應的記錄就會一直存在,表示這個事務沒有完成的一種記錄。
應用會創建一個定時任務,周期性的掃描transaction_log表中的記錄(例如每隔2S掃描一次)。發現有符合條件的記錄,就嘗試執行補償邏輯。例如更新用戶信息時,DB中的user_info表更新成功,但緩存更新失敗,定時任務發現transaction_log表中對應的記錄沒有刪除且已經超過正常等待時間,就嘗試使緩存和DB一致(可以刪除緩存中對應的數據,也可以根據userId重新查詢DB再補充的緩存)。補償任務執行完成后,就可以刪除transaction_log表中對應的記錄。如果補償任務執行再次失敗,就保留transaction_log表中的記錄,等待下個周期再次執行。
事務補償這種方式保證的是事務的最終一致性,即如果發生意外,會存在一個時間窗口(例如2S),在這個窗口內DB和緩存間是不一致的,但能保證最終兩者的數據是一致的。至于定時任務周期的設定,要結合業務對“臟”數據的敏感程度以及系統的負載。
事務型消息
對于一個金融系統,假設有一個需求是用戶注冊成功后自動為用戶創建一個賬戶。客戶的信息維護在客戶中心系統,客戶的賬戶信息維護的賬務中心系統,如果用戶注冊成功,必須保證客戶的賬戶在賬務系統創建成功。這顯然也是一個分布式事務問題。
處理這個問題,顯然也可以采用上一小節介紹的事務補償機制來處理。但注冊和開戶并不要求一定是同步完成,且需要感知用戶注冊成功事件的系統并不只有賬務系統一個(例如營銷系統可能也需要感知用戶注冊成功的事件,給用戶發優惠券),所以使用消息機制異步通知更加合適。那么問題就變成了“如果用戶注冊成功,一定要保證消息發送成功”。
應對這種場景,可以使用事務型消息。但前提條件是使用的MQ中間件必須支持事務型消息,比如阿里的RocketMQ。目前市面上其它一些主流的MQ中間件都不支持事務型消息,比如Kafka和RabbitMQ都不支持。
下面的序列圖是事務型消息的執行流程:
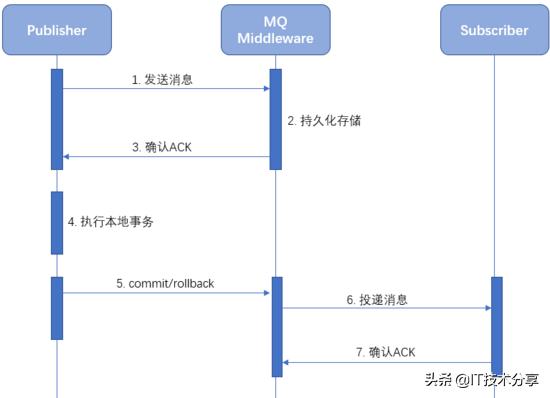
- 相比于普通消息,發布者發送消息后,MQ并不是馬上將消息發送給訂閱者,而僅僅是將消息持久化存儲下來。
- 發送消息成功之后,發布者執行本地事務。例如我們例子中提到的用戶注冊。
- 根據本地事務執行是否成功,發布者決定對之前已經發送的消息是commit還是rollback。如果是rollback,MQ會刪除之前存儲的消息。假設我們這里發送commit。
- MQ接收到發布者發送的commit后,才會將消息發送給訂閱者。之后,就可以利用MQ的消息可靠傳輸特性促使訂閱者完成剩余事務操作,例如上面例子中提到的開戶操作。
細心的小伙伴會發現,如果在上圖中的第5步發生問題導致發送commit失敗,不還是會導致消息發布者和消息訂閱者間事務的不一致嗎?為了防止這種情況的發生,增加MQ超時回調機制。
下面的序列圖是事務型消息commit失敗時的執行流程:
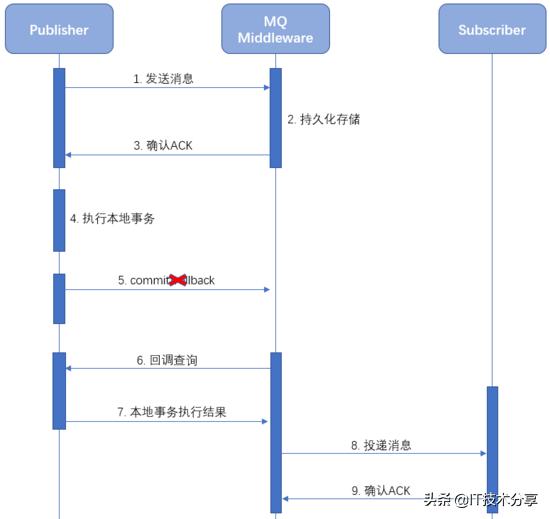
當MQ長時間收不到發布者的commit/rollback通知時,MQ會回調發布者應用詢問本地事務是否執行成功,是commit還是rollback之前的消息。發布者需要提供對應的callback,在callback中判斷本地事務是否執行成功。
TCC兩階段提交
在某些場景下,一個分布式事務可能會涉及到多個參與者,且每個參與者需要根據自己當時的狀態對事務進行響應。
假設這樣一個場景,一個電商網站可以允許用戶在支付時選擇多種支付方式。例如總共需要支付100元錢,用戶可以選擇積分支付10元,賬戶余額支付90元。用戶的積分由營銷系統負責,賬戶余額由賬務系統負責,訂單的狀態管理由訂單系統負責。
- 首先,要先確保事務的各個參與者滿足條件才能執行事務。例如積分系統要確保用戶的積分超過10元錢,賬務系統要確保用戶的賬戶余額大于90元錢才能發起這次交易。
- 其次,就是要滿足事務的原子性。這里的用戶積分、用戶余額、訂單狀態,要嘛全部處理成功,要嘛全部保持不變。
應對這種分布式事務場景,可以采用TCC兩階段提交的方式進行處理。
TCC將整個事務分成兩個階段——try和commit/cancel。TCC整個流程具有三種角色——事務發起者、事務參與者、事務協調者。以上面的訂單支付為例,采用TCC實現處理事務的流程如下:
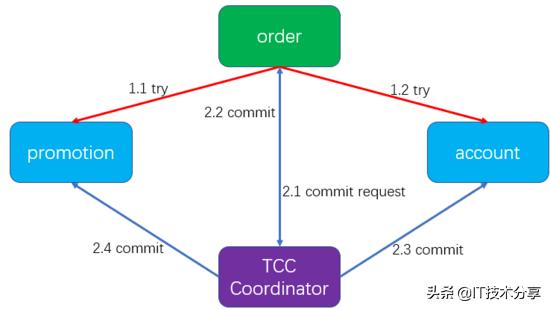
- 第一階段try,訂單系統分別調用promotion和account兩個系統,詢問該用戶是否有足夠的積分和賬戶余額。為了防止資源爭搶,在這個階段會對資源進行鎖定,即營銷系統會鎖住用戶的10元積分,賬務系統會鎖住用戶的90元賬戶余額。
- 如果在try階段有任何一個參與者處理失敗(例如用戶積分不夠10元或者用戶的余額不夠90元),則事務發起方(訂單系統)會通知事務協調組件,后者會通知所有的事務參與者cancel在try階段鎖定的資源。
- 如果在try階段所有的參與者都處理成功,則事務發起方通知協調者commit這個事務,協調者會通知所有的參與者完成事務的commit。這時系統會完成真正的余額和積分扣減。2.2步是假設訂單系統也要更新訂單的狀態。
但僅是這樣處理還是有一致性問題,例如在第二階段commit時如果發生宕機、網絡抖動等異常情況,就可能導致事務處于“非最終一致”狀態(參與者只執行了try階段,沒有執行第二階段。或部分參與者第二階段commit成功,部分參與者commit失敗)。為了應對這種情況,需要增加事務日志,以便發生異常時回復事務。
可以利用DB這種可靠存儲來記錄事務日志。日志中應包含事務執行過程中的上下文、事務執行狀態、事務的參與者等信息。事務日志可以由事務發起發負責記錄,也可以交由事務協調方進行記錄。
事務日志可以由主事務記錄日志和從事務記錄日志組成:
- 主事務記錄日志 用于記錄事務發起方信息以及事務執行的整體狀態。
- 從事務記錄日志 用于記錄所有的事務參與者信息,以及每個參與者所屬的從事務的執行狀態。與主事務記錄日志是一對多的關系。
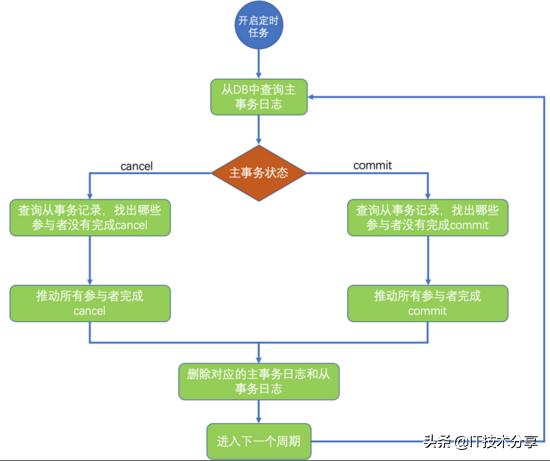
有了事務日志后,就可以周期性的不斷掃描事務日志,找到異常中斷的事務。根據事務日志中記錄的信息,推動剩余的參與者commit或者cancel,以便使整個分布式事務達到“最終一致性”。
下面是commit階段發生異常時的事務補償邏輯:
TCC兩階段提交的實現需要注意如下事項:
- 事務中的任何一個參與者都要確保在try階段操作成功,在第二階段就一定能commit成功。
- 參與者在實現commit和cancel接口時要考慮冪等,對重復的commit/cancel請求要能夠正確處理。
- 業務上要考慮對兩階段中間狀態(一階段已完成,二階段未開始)的處理。一般可以通過一些特殊文案,比如顯示當前被凍結的賬戶余額。
- 對于狀態型數據,當多個事務共同操作同一個資源時,要確保資源隔離。例如賬戶余額,確保不同的事務操作的金額是隔離的,彼此互不影響。
- 由于網絡丟包、亂序等因素的影響,可能會導致參與者接收到一階段try請求后,永遠收不到commit/cancel請求,導致參與者的資源一直被鎖定,永遠不會被釋放,這種情況叫做事務懸掛。為了防止事務懸掛的發生,可以在第一階段try成功后,指定一個最大等待時間。超過這個最大等待時間就自動釋放被鎖定的資源。
總結
傳統的單機事務應滿足A(原子性)、C(一致性)、I(隔離型)、D(持久性)四個特性,屬于剛性事務。由于分布式系統具有多個節點的特點,要求完全滿足ACID這四個規范會非常的困難。所以就誕生了柔性事務BASE理論(Basic availability、Soft state、Eventual consistency)。
相比于單機事務,分布式事務在A和D上仍能夠嚴格保證,但在C和I上就要有一定程度的限制放寬(允許看到中間狀態數據、最終一致性)。
















