閑話高并發(fā)的那些神話,看京東架構(gòu)師如何把它拉下神壇
高并發(fā)也算是這幾年的熱門詞匯了,尤其在互聯(lián)網(wǎng)圈,開口不聊個(gè)高并發(fā)問(wèn)題,都不好意思出門。高并發(fā)有那么邪乎嗎?動(dòng)不動(dòng)就千萬(wàn)并發(fā)、億級(jí)流量,聽上去的確挺嚇人。但仔細(xì)想想,這么大的并發(fā)與流量不都是通過(guò)路由器來(lái)的嗎?
一、一切源自網(wǎng)卡
高并發(fā)的流量通過(guò)低調(diào)的路由器進(jìn)入我們系統(tǒng),第一道關(guān)卡就是網(wǎng)卡,網(wǎng)卡怎么抗住高并發(fā)?這個(gè)問(wèn)題壓根就不存在,千萬(wàn)并發(fā)在網(wǎng)卡看來(lái),一樣一樣的,都是電信號(hào),網(wǎng)卡眼里根本區(qū)分不出來(lái)你是千萬(wàn)并發(fā)還是一股洪流,所以衡量網(wǎng)卡牛不牛都說(shuō)帶寬,從來(lái)沒(méi)有并發(fā)量的說(shuō)法。
網(wǎng)卡位于物理層和鏈路層,最終把數(shù)據(jù)傳遞給網(wǎng)絡(luò)層(IP層),在網(wǎng)絡(luò)層有了IP地址,已經(jīng)可以識(shí)別出你是千萬(wàn)并發(fā)了,所以搞網(wǎng)絡(luò)層的可以自豪的說(shuō),我解決了高并發(fā)問(wèn)題,可以出來(lái)吹吹牛了。誰(shuí)沒(méi)事搞網(wǎng)絡(luò)層呢?主角就是路由器,這玩意主要就是玩兒網(wǎng)絡(luò)層。
二、一頭霧水
非專業(yè)的我們,一般都把網(wǎng)絡(luò)層(IP層)和傳輸層(TCP層)放到一起,操作系統(tǒng)提供,對(duì)我們是透明的,很低調(diào)、很靠譜,以至于我們都把他忽略了。
吹過(guò)的牛是從應(yīng)用層開始的,應(yīng)用層一切都源于Socket,那些千萬(wàn)并發(fā)最終會(huì)經(jīng)過(guò)傳輸層變成千萬(wàn)個(gè)Socket,那些吹過(guò)的牛,不過(guò)就是如何快速處理這些Socket。處理IP層數(shù)據(jù)和處理Socket究竟有啥不同呢?
三、沒(méi)有連接,就沒(méi)用等待
最重要的一個(gè)不同就是IP層不是面向連接的,而Socket是面向連接的,IP層沒(méi)有連接的概念,在IP層,來(lái)一個(gè)數(shù)據(jù)包就處理一個(gè),不用瞻前也不用顧后;而處理Socket,必須瞻前顧后,Socket是面向連接的,有上下文的,讀到一句我愛(ài)你,激動(dòng)半天,你不前前后后地看看,就是瞎激動(dòng)了。
你想前前后后地看明白,就要占用更多的內(nèi)存去記憶,就要占用更長(zhǎng)的時(shí)間去等待;不同連接要搞好隔離,就要分配不同的線程(或者協(xié)程)。所有這些都解決好,貌似還是有點(diǎn)難度的。
四、感謝操作系統(tǒng)
操作系統(tǒng)是個(gè)好東西,在Linux系統(tǒng)上,所有的IO都被抽象成了文件,網(wǎng)絡(luò)IO也不例外,被抽象成Socket,但是Socket還不僅是一個(gè)IO的抽象,它同時(shí)還抽象了如何處理Socket,最著名的就是select和epoll了,知名的nginx、netty、redis都是基于epoll搞的,這仨家伙基本上是在千萬(wàn)并發(fā)領(lǐng)域必備神技。
但是多年前,Linux只提供了select的,這種模式能處理的并發(fā)量非常小,而epoll是專為高并發(fā)而生的,感謝操作系統(tǒng)。不過(guò)操作系統(tǒng)沒(méi)有解決高并發(fā)的所有問(wèn)題,只是讓數(shù)據(jù)快速地從網(wǎng)卡流入我們的應(yīng)用程序,如何處理才是老大難。
操作系統(tǒng)的使命之一就是最大限度的發(fā)揮硬件的能力,解決高并發(fā)問(wèn)題,這也是最直接、最有效的方案,其次才是分布式計(jì)算。前面我們提到的nginx、netty、redis都是最大限度發(fā)揮硬件能力的典范。如何才能最大限度的發(fā)揮硬件能力呢?
五、核心矛盾
要最大限度的發(fā)揮硬件能力,首先要找到核心矛盾所在。我認(rèn)為,這個(gè)核心矛盾從計(jì)算機(jī)誕生之初直到現(xiàn)在,幾乎沒(méi)有發(fā)生變化,就是CPU和IO之間的矛盾。
CPU以摩爾定律的速度野蠻發(fā)展,而IO設(shè)備(磁盤,網(wǎng)卡)卻乏善可陳。龜速的IO設(shè)備成為性能瓶頸,必然導(dǎo)致CPU的利用率很低,所以提升CPU利用率幾乎成了發(fā)揮硬件能力的代名詞。
六、中斷與緩存
CPU與IO設(shè)備的協(xié)作基本都是以中斷的方式進(jìn)行的,例如讀磁盤的操作,CPU僅僅是發(fā)一條讀磁盤到內(nèi)存的指令給磁盤驅(qū)動(dòng),之后就立即返回了,此時(shí)CPU可以接著干其他事情,讀磁盤到內(nèi)存本身是個(gè)很耗時(shí)的工作,等磁盤驅(qū)動(dòng)執(zhí)行完指令,會(huì)發(fā)個(gè)中斷請(qǐng)求給CPU,告訴CPU任務(wù)已經(jīng)完成,CPU處理中斷請(qǐng)求,此時(shí)CPU可以直接操作讀到內(nèi)存的數(shù)據(jù)。
中斷機(jī)制讓CPU以最小的代價(jià)處理IO問(wèn)題,那如何提高設(shè)備的利用率呢?答案就是緩存。
操作系統(tǒng)內(nèi)部維護(hù)了IO設(shè)備數(shù)據(jù)的緩存,包括讀緩存和寫緩存,讀緩存很容易理解,我們經(jīng)常在應(yīng)用層使用緩存,目的就是盡量避免產(chǎn)生讀IO。
寫緩存應(yīng)用層使用的不多,操作系統(tǒng)的寫緩存,完全是為了提高IO寫的效率。操作系統(tǒng)在寫IO的時(shí)候會(huì)對(duì)緩存進(jìn)行合并和調(diào)度,例如寫磁盤會(huì)用到電梯調(diào)度算法。
七、高效利用網(wǎng)卡
高并發(fā)問(wèn)題首先要解決的是如何高效利用網(wǎng)卡。網(wǎng)卡和磁盤一樣,內(nèi)部也是有緩存的,網(wǎng)卡接收網(wǎng)絡(luò)數(shù)據(jù),先存放到網(wǎng)卡緩存,然后寫入操作系統(tǒng)的內(nèi)核空間(內(nèi)存),我們的應(yīng)用程序則讀取內(nèi)存中的數(shù)據(jù),然后處理。
除了網(wǎng)卡有緩存外,TCP/IP協(xié)議內(nèi)部還有發(fā)送緩沖區(qū)和接收緩沖區(qū)以及SYN積壓隊(duì)列、accept積壓隊(duì)列。
這些緩存,如果配置不合適,則會(huì)出現(xiàn)各種問(wèn)題。例如在TCP建立連接階段,如果并發(fā)量過(guò)大,而nginx里面socket的backlog設(shè)置的值太小,就會(huì)導(dǎo)致大量連接請(qǐng)求失敗。
如果網(wǎng)卡的緩存太小,當(dāng)緩存滿了后,網(wǎng)卡會(huì)直接把新接收的數(shù)據(jù)丟掉,造成丟包。當(dāng)然如果我們的應(yīng)用讀取網(wǎng)絡(luò)IO數(shù)據(jù)的效率不高,會(huì)加速網(wǎng)卡緩存數(shù)據(jù)的堆積。如何高效讀取網(wǎng)絡(luò)數(shù)據(jù)呢?目前在Linux上廣泛應(yīng)用的就是epoll了。
操作系統(tǒng)把IO設(shè)備抽象為文件,網(wǎng)絡(luò)被抽象成了Socket,Socket本身也是一個(gè)文件,所以可以用read/write方法來(lái)讀取和發(fā)送網(wǎng)絡(luò)數(shù)據(jù)。在高并發(fā)場(chǎng)景下,如何高效利用Socket快速讀取和發(fā)送網(wǎng)絡(luò)數(shù)據(jù)呢?
要想高效利用IO,就必須在操作系統(tǒng)層面了解IO模型,在《UNIX網(wǎng)絡(luò)編程》這本經(jīng)典著作里,總結(jié)了五種IO模型,分別是阻塞式IO,非阻塞式IO,多路復(fù)用IO,信號(hào)驅(qū)動(dòng)IO和異步IO。
八、阻塞式IO
我們以讀操作為例,當(dāng)我們調(diào)用read方法讀取Socket上的數(shù)據(jù)時(shí),如果此時(shí)Socket讀緩存是空的(沒(méi)有數(shù)據(jù)從Socket的另一端發(fā)過(guò)來(lái)),操作系統(tǒng)會(huì)把調(diào)用read方法的線程掛起,直到Socket讀緩存里有數(shù)據(jù)時(shí),操作系統(tǒng)再把該線程喚醒。
當(dāng)然,在喚醒的同時(shí),read方法也返回了數(shù)據(jù)。我理解所謂的阻塞,就是操作系統(tǒng)是否會(huì)掛起線程。
九、非阻塞式IO
而對(duì)于非阻塞式IO,如果Socket的讀緩存是空的,操作系統(tǒng)并不會(huì)把調(diào)用read方法的線程掛起,而是立即返回一個(gè)EAGAIN的錯(cuò)誤碼,在這種情景下,可以輪詢r(jià)ead方法,直到Socket的讀緩存有數(shù)據(jù)則可以讀到數(shù)據(jù),這種方式的缺點(diǎn)非常明顯,就是消耗大量的CPU。
十、多路復(fù)用IO
對(duì)于阻塞式IO,由于操作系統(tǒng)會(huì)掛起調(diào)用線程,所以如果想同時(shí)處理多個(gè)Socket,就必須相應(yīng)地創(chuàng)建多個(gè)線程,線程會(huì)消耗內(nèi)存,增加操作系統(tǒng)進(jìn)行線程切換的負(fù)載,所以這種模式不適合高并發(fā)場(chǎng)景。有沒(méi)有辦法較少線程數(shù)呢?
非阻塞IO貌似可以解決,在一個(gè)線程里輪詢多個(gè)Socket,看上去可以解決線程數(shù)的問(wèn)題,但實(shí)際上這個(gè)方案是無(wú)效的,原因是調(diào)用read方法是一個(gè)系統(tǒng)調(diào)用,系統(tǒng)調(diào)用是通過(guò)軟中斷實(shí)現(xiàn)的,會(huì)導(dǎo)致進(jìn)行用戶態(tài)和內(nèi)核態(tài)的切換,所以很慢。
但是這個(gè)思路是對(duì)的,有沒(méi)有辦法避免系統(tǒng)調(diào)用呢?有,就是多路復(fù)用IO。
在Linux系統(tǒng)上select/epoll這倆系統(tǒng)API支持多路復(fù)用IO,通過(guò)這兩個(gè)API,一個(gè)系統(tǒng)調(diào)用可以監(jiān)控多個(gè)Socket,只要有一個(gè)Socket的讀緩存有數(shù)據(jù)了,方法就立即返回,然后你就可以去讀這個(gè)可讀的Socket了,如果所有的Socket讀緩存都是空的,則會(huì)阻塞,也就是將調(diào)用select/epoll的線程掛起。
所以select/epoll本質(zhì)上也是阻塞式IO,只不過(guò)他們可以同時(shí)監(jiān)控多個(gè)Socket。
1. select和epoll的區(qū)別
為什么多路復(fù)用IO模型有兩個(gè)系統(tǒng)API?我分析原因是,select是POSIX標(biāo)準(zhǔn)中定義的,但是性能不夠好,所以各個(gè)操作系統(tǒng)都推出了性能更好的API,如Linux上的epoll、Windows上的IOCP。
至于select為什么會(huì)慢,大家比較認(rèn)可的原因有兩點(diǎn),一點(diǎn)是select方法返回后,需要遍歷所有監(jiān)控的Socket,而不是發(fā)生變化的Ssocket,還有一點(diǎn)是每次調(diào)用select方法,都需要在用戶態(tài)和內(nèi)核態(tài)拷貝文件描述符的位圖(通過(guò)調(diào)用三次copy_from_user方法拷貝讀、寫、異常三個(gè)位圖)。epoll可以避免上面提到的這兩點(diǎn)。
2. Reactor多線程模型
在Linux操作系統(tǒng)上,性能最為可靠、穩(wěn)定的IO模式就是多路復(fù)用,我們的應(yīng)用如何能夠利用好多路復(fù)用IO呢?經(jīng)過(guò)前人多年實(shí)踐總結(jié),搞了一個(gè)Reactor模式,目前應(yīng)用非常廣泛,著名的Netty、Tomcat NIO就是基于這個(gè)模式。
Reactor的核心是事件分發(fā)器和事件處理器,事件分發(fā)器是連接多路復(fù)用IO和網(wǎng)絡(luò)數(shù)據(jù)處理的中樞,核心就是監(jiān)聽Socket事件(select/epoll_wait),然后將事件分發(fā)給事件處理器,事件分發(fā)器和事件處理器都可以基于線程池來(lái)做。
需要重點(diǎn)提一下的是,在Socket事件中主要有兩大類事件,一個(gè)是連接請(qǐng)求,另一個(gè)是讀寫請(qǐng)求,連接請(qǐng)求成功處理之后會(huì)創(chuàng)建新的Socket,讀寫請(qǐng)求都是基于這個(gè)新創(chuàng)建的Socket。
所以在網(wǎng)絡(luò)處理場(chǎng)景中,實(shí)現(xiàn)Reactor模式會(huì)稍微有點(diǎn)繞,但是原理沒(méi)有變化。具體實(shí)現(xiàn)可以參考Doug Lea的《Scalable IO in Java》(http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf)
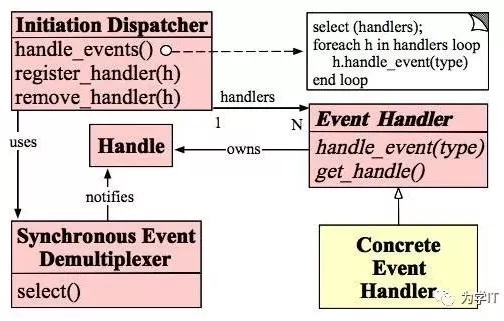
Reactor原理圖
3. Nginx多進(jìn)程模型
Nginx默認(rèn)采用的是多進(jìn)程模型,Nginx分為Master進(jìn)程和Worker進(jìn)程,真正負(fù)責(zé)監(jiān)聽網(wǎng)絡(luò)請(qǐng)求并處理請(qǐng)求的只有Worker進(jìn)程,所有的Worker進(jìn)程都監(jiān)聽默認(rèn)的80端口,但是每個(gè)請(qǐng)求只會(huì)被一個(gè)Worker進(jìn)程處理。
這里面的玄機(jī)是:每個(gè)進(jìn)程在accept請(qǐng)求前必須爭(zhēng)搶一把鎖,得到鎖的進(jìn)程才有權(quán)處理當(dāng)前的網(wǎng)絡(luò)請(qǐng)求。每個(gè)Worker進(jìn)程只有一個(gè)主線程,單線程的好處是無(wú)鎖處理,無(wú)鎖處理并發(fā)請(qǐng)求,這基本上是高并發(fā)場(chǎng)景里面的最高境界了。
(參考http://www.dre.vanderbilt.edu/~schmidt/PDF/reactor-siemens.pdf)
數(shù)據(jù)經(jīng)過(guò)網(wǎng)卡、操作系統(tǒng)、網(wǎng)絡(luò)協(xié)議中間件(Tomcat、Netty等)重重關(guān)卡,終于到了我們應(yīng)用開發(fā)人員手里,我們?nèi)绾翁幚磉@些高并發(fā)的請(qǐng)求呢?我們還是先從提升單機(jī)處理能力的角度來(lái)思考這個(gè)問(wèn)題。
4. 突破木桶理論
據(jù)經(jīng)過(guò)網(wǎng)卡、操作系統(tǒng)、中間件(Tomcat、Netty等)重重關(guān)卡,終于到了我們應(yīng)用開發(fā)人員手里,我們?nèi)绾翁幚磉@些高并發(fā)的請(qǐng)求呢?
我們還是先從提升單機(jī)處理能力的角度來(lái)思考這個(gè)問(wèn)題,在實(shí)際應(yīng)用的場(chǎng)景中,問(wèn)題的焦點(diǎn)是如何提高CPU的利用率(誰(shuí)叫它發(fā)展的最快呢),木桶理論講最短的那根板決定水位,那為啥不是提高短板IO的利用率,而是去提高CPU的利用率呢?
這個(gè)問(wèn)題的答案是在實(shí)際應(yīng)用中,提高了CPU的利用率往往會(huì)同時(shí)提高IO的利用率。當(dāng)然在IO利用率已經(jīng)接近極限的條件下,再提高CPU利用率是沒(méi)有意義的。我們先來(lái)看看如何提高CPU的利用率,后面再看如何提高IO的利用率。
5. 并行與并發(fā)
提升CPU利用率目前主要的方法是利用CPU的多核進(jìn)行并行計(jì)算,并行和并發(fā)是有區(qū)別的,在單核CPU上,我們可以一邊聽MP3,一邊Coding,這個(gè)是并發(fā),但不是并行,因?yàn)樵趩魏薈PU的視野,聽MP3和Coding是不可能同時(shí)進(jìn)行的。
只有在多核時(shí)代,才會(huì)有并行計(jì)算。并行計(jì)算這東西太高級(jí),工業(yè)化應(yīng)用的模型主要有兩種,一種是共享內(nèi)存模型,另外一種是消息傳遞模型。
6. 多線程設(shè)計(jì)模式
對(duì)于共享內(nèi)存模型,其原理基本都來(lái)自大師Dijkstra在半個(gè)世紀(jì)前(1965)的一篇論文《Cooperating sequential processes》,這篇論文提出了大名鼎鼎的概念信號(hào)量,Java里面用于線程同步的wait/notify也是信號(hào)量的一種實(shí)現(xiàn)。
大師的東西看不懂,學(xué)不會(huì)也不用覺(jué)得丟人,畢竟大師的嫡傳子弟也沒(méi)幾個(gè)。東洋有個(gè)叫結(jié)城浩的總結(jié)了一下多線程編程的經(jīng)驗(yàn),寫了本書叫《JAVA多線程設(shè)計(jì)模式》,這個(gè)還是挺接地氣(能看懂)的。下面簡(jiǎn)單介紹一下。
(1) Single Threaded Execution
這個(gè)模式是把多線程變成單線程,多線程在同時(shí)訪問(wèn)一個(gè)變量時(shí),會(huì)發(fā)生各種莫名其妙的問(wèn)題,這個(gè)設(shè)計(jì)模式直接把多線程搞成了單線程,于是安全了,當(dāng)然性能也就下來(lái)了。最簡(jiǎn)單的實(shí)現(xiàn)就是利用synchronized將存在安全隱患的代碼塊(方法)保護(hù)起來(lái)。在并發(fā)領(lǐng)域有個(gè)臨界區(qū)(criticalsections)的概念,我感覺(jué)和這個(gè)模式是一回事。
(2) Immutable Pattern
如果共享變量永遠(yuǎn)不變,那就多個(gè)線程訪問(wèn)就沒(méi)有任何問(wèn)題,永遠(yuǎn)安全。這個(gè)模式雖然簡(jiǎn)單,但是用的好,能解決很多問(wèn)題。
(3) Guarded Suspension Patten
這個(gè)模式其實(shí)就是等待-通知模型,當(dāng)線程執(zhí)行條件不滿足時(shí),掛起當(dāng)前線程(等待),當(dāng)條件滿足時(shí),喚醒所有等待的線程(通知),在Java語(yǔ)言里利用synchronized,wait/notifyAll可以很快實(shí)現(xiàn)一個(gè)等待通知模型。結(jié)城浩將這個(gè)模式總結(jié)為多線程版的If,我覺(jué)得非常貼切。
(4) Balking
這個(gè)模式和上個(gè)模式類似,不同點(diǎn)是當(dāng)線程執(zhí)行條件不滿足時(shí)直接退出,而不是像上個(gè)模式那樣掛起。這個(gè)用法最大的應(yīng)用場(chǎng)景是多線程版的單例模式,當(dāng)對(duì)象已經(jīng)創(chuàng)建了(不滿足創(chuàng)建對(duì)象的條件)就不用再創(chuàng)建對(duì)象(退出)。
(5) Producer-Consumer
生產(chǎn)者-消費(fèi)者模式,全世界人都知道。我接觸的最多的是一個(gè)線程處理IO(如查詢數(shù)據(jù)庫(kù)),一個(gè)(或者多個(gè))線程處理IO數(shù)據(jù),這樣IO和CPU就都能成分利用起來(lái)。如果生產(chǎn)者和消費(fèi)者都是CPU密集型,再搞生產(chǎn)者-消費(fèi)者就是自己給自己找麻煩了。
(6) Read-Write Lock
讀寫鎖解決的讀多寫少場(chǎng)景下的性能問(wèn)題,支持并行讀,但是寫操作只允許一個(gè)線程做。如果寫操作非常非常少,而讀的并發(fā)量非常非常大,這個(gè)時(shí)候可以考慮使用寫時(shí)復(fù)制(copy on write)技術(shù),我個(gè)人覺(jué)得應(yīng)該單獨(dú)把寫時(shí)復(fù)制單獨(dú)作為一個(gè)模式。
(7) Thread-Per-Message
就是我們經(jīng)常提到的一請(qǐng)求一線程。
(8) Worker Thread
一請(qǐng)求一線程的升級(jí)版,利用線程池解決線程的頻繁創(chuàng)建、銷毀導(dǎo)致的性能問(wèn)題。BIO年代Tomcat就是用的這種模式。
(9) Future
當(dāng)你調(diào)用某個(gè)耗時(shí)的同步方法很心煩,想同時(shí)干點(diǎn)別的事情,可以考慮用這個(gè)模式,這個(gè)模式的本質(zhì)是個(gè)同步變異步的轉(zhuǎn)換器。同步之所以能變異步,本質(zhì)上是啟動(dòng)了另外一個(gè)線程,所以這個(gè)模式和一請(qǐng)求一線程還是多少有點(diǎn)關(guān)系的。
(10) Two-Phase Termination
這個(gè)模式能解決優(yōu)雅地終止線程的需求。
(11) Thread-Specific Storage
線程本地存儲(chǔ),避免加鎖、解鎖開銷的利器,C#里面有個(gè)支持并發(fā)的容器ConcurrentBag就是采用了這個(gè)模式,這個(gè)星球上最快的數(shù)據(jù)庫(kù)連接池HikariCP借鑒了ConcurrentBag的實(shí)現(xiàn),搞了個(gè)Java版的,有興趣的同學(xué)可以參考。
(12) Active Object(這個(gè)不講也罷)
這個(gè)模式相當(dāng)于降龍十八掌的最后一掌,綜合了前面的設(shè)計(jì)模式,有點(diǎn)復(fù)雜,個(gè)人覺(jué)得借鑒的意義大于參考實(shí)現(xiàn)。
最近國(guó)人也出過(guò)幾本相關(guān)的書,但總體還是結(jié)城浩這本更能經(jīng)得住推敲。基于共享內(nèi)存模型解決并發(fā)問(wèn)題,主要問(wèn)題就是用好鎖,但是用好鎖,還是有難度的,所以后來(lái)又有人搞了消息傳遞模型,這個(gè)后面再聊。
基于共享內(nèi)存模型解決并發(fā)問(wèn)題,主要問(wèn)題就是用好鎖,但是用好鎖,還是有難度的,所以后來(lái)又有人搞了消息傳遞模型。
十一、消息傳遞模型
共享內(nèi)存模型難度還是挺大的,而且你沒(méi)有辦法從理論上證明寫的程序是正確的,我們總一不小心就會(huì)寫出來(lái)個(gè)死鎖的程序來(lái),每當(dāng)有了問(wèn)題,總會(huì)有大師出來(lái),于是消息傳遞(Message-Passing)模型橫空出世(發(fā)生在上個(gè)世紀(jì)70年代),消息傳遞模型有兩個(gè)重要的分支,一個(gè)是Actor模型,一個(gè)是CSP模型。
十二、Actor模型
Actor模型因?yàn)镋rlang聲名鵲起,后來(lái)又出現(xiàn)了Akka。在Actor模型里面,沒(méi)有操作系統(tǒng)里所謂進(jìn)程、線程的概念,一切都是Actor,我們可以把Actor想象成一個(gè)更全能、更好用的線程。
在Actor內(nèi)部是線性處理(單線程)的,Actor之間以消息方式交互,也就是不允許Actor之間共享數(shù)據(jù),沒(méi)有共享,就無(wú)需用鎖,這就避免了鎖帶來(lái)的各種副作用。
Actor的創(chuàng)建和new一個(gè)對(duì)象沒(méi)有啥區(qū)別,很快、很小,不像線程的創(chuàng)建又慢又耗資源;Actor的調(diào)度也不像線程會(huì)導(dǎo)致操作系統(tǒng)上下文切換(主要是各種寄存器的保存、恢復(fù)),所以調(diào)度的消耗也很小。
Actor還有一個(gè)有點(diǎn)爭(zhēng)議的優(yōu)點(diǎn),Actor模型更接近現(xiàn)實(shí)世界,現(xiàn)實(shí)世界也是分布式的、異步的、基于消息的、尤其Actor對(duì)于異常(失敗)的處理、自愈、監(jiān)控等都更符合現(xiàn)實(shí)世界的邏輯。
但是這個(gè)優(yōu)點(diǎn)改變了編程的思維習(xí)慣,我們目前大部分編程思維習(xí)慣其實(shí)是和現(xiàn)實(shí)世界有很多差異的(這個(gè)回頭再細(xì)說(shuō)),一般來(lái)講,改變我們思維習(xí)慣的事情,阻力總是超乎我們的想象。
十三、CSP模型
Golang在語(yǔ)言層面支持CSP模型,CSP模型和Actor模型的一個(gè)感官上的區(qū)別是在CSP模型里面,生產(chǎn)者(消息發(fā)送方)和消費(fèi)者(消息接收方)是完全松耦合的,生產(chǎn)者完全不知道消費(fèi)者的存在,但是在Actor模型里面,生產(chǎn)者必須知道消費(fèi)者,否則沒(méi)辦法發(fā)送消息。
CSP模型類似于我們?cè)诙嗑€程里面提到的生產(chǎn)者-消費(fèi)者模型,核心的區(qū)別我覺(jué)得在于CSP模型里面有類似綠色線程(green thread)的東西,綠色線程在Golang里面叫做協(xié)程,協(xié)程同樣是個(gè)非常輕量級(jí)的調(diào)度單元,可以快速創(chuàng)建而且資源占用很低。
Actor在某種程度上需要改變我們的思維方式,而CSP模型貌似沒(méi)有那么大動(dòng)靜,更容易被現(xiàn)在的開發(fā)人員接受,都說(shuō)Golang是工程化的語(yǔ)言,在Actor和CSP的選擇上,也可以看到這種體現(xiàn)。
十四、多樣世界
除了消息傳遞模型,還有事件驅(qū)動(dòng)模型、函數(shù)式模型。事件驅(qū)動(dòng)模型類似于觀察者模式,在Actor模型里面,消息的生產(chǎn)者必須知道消費(fèi)者才能發(fā)送消息,而在事件驅(qū)動(dòng)模型里面,事件的消費(fèi)者必須知道消息的生產(chǎn)者才能注冊(cè)事件處理邏輯。
Akka里消費(fèi)者可以跨網(wǎng)絡(luò),事件驅(qū)動(dòng)模型的具體實(shí)現(xiàn)如Vertx里,消費(fèi)者也可以訂閱跨網(wǎng)絡(luò)的事件,從這個(gè)角度看,大家都在取長(zhǎng)補(bǔ)短。
【本文來(lái)自51CTO專欄作者張開濤的微信公眾號(hào)(開濤的博客),公眾號(hào)id: kaitao-1234567】