京東服務市場高并發下SOA服務化演進架構
京東服務市場是京東商家與第三方獨立軟件提供商(ISV)進行服務類的在線交易平臺。作為京東生態圈重要的一環,伴隨著整個京東的快速增長,也在快速的發展。隨著服務市場訪問、交易量指數級的增長,系統由原來的ALL IN ONE架構,快速的演進成為SOA架構。
木桶的容量由木桶最短的木板決定,高并發環境下,單個服務的性能決定了整個服務市場的性能。 “可用插件列表服務”是服務市場的核心服務之一,優化該服務性能的過程,帶動整個服務市場服務架構的演進。
宏觀的看,大到系統小到模塊都由自身+外部依賴組成,性能優化主要從自身與外部依賴兩個方面來進行。
一、優化自身
單線程到多線程的升級,嘗試通過并行提高服務性能。

根據日志分析,整體調用中“服務詳細信息”占用時間最多,并行雖然壓縮了一些可并行服務的調用時間,但對于無法并行的“服務詳細信息”環節,依然沒有改善。要改善必須找到“商品服務”性能不高的原因。
可見自身優化能起一些作用,但外部依賴起著更決定性的作用。
二、解決外部依賴沖突
“商品服務”性能不高,這是為什么呢?先從“商品服務”的依賴開始分析。單獨調用該服務,或壓測該服務,性能都不差,但為何線上性能卻不佳?
1. 不同服務外部依賴資源沖突
對“商品服務”依賴的資源進行梳理,發現“商品服務”與“類目服務”使用相同數據庫資源,非調用高峰期資源足夠不相互影響,大并發環境下兩個服務開始爭奪資源。
將依賴資源分開,不同的服務使用不同的資源,通過調用不同的數據源解決沖突。

2. 相同服務外部資源依賴沖突
解決了兩個服務對數據庫資源的依賴沖突,性能有所提高,但性能總有很大的波動,排除其他服務外部資源的依賴沖突,看看“商品服務”自身對資源是如何使用的。

“商品服務”所有功能都單一的依賴數據庫資源。服務上線后,自身多個功能開始爭搶數據庫資源。
按使用場景進行外部依賴資源解耦:
- 為保證交易一致性,繼續采用MySQL。MySQL的 INNODB引擎長于 OLTP 在線事務處理,為了保證數據強一致性的場景繼續選擇使用MySQL數據庫。
- 客戶端登錄用戶需要獲得***的數據反饋,且有PIN這個固定的維度。查詢條件簡單,能符合KEY-VALUE方式,Redis很適合這個場景。
- 大前端非登錄狀態下,訪問的用戶無須登錄,有很大的訪問量,更多的是獲取服務的一些介紹。大數據量,可容忍一定程度的延遲,所以采用ES來進行查詢支撐。
- 外部系統希望獲得***服務的變化,推的方式遠強于輪訓拉取的方式。通過MQ訂閱服務的變化情況。
- 有復雜計算,但對實時性要求不高,服務統計分析系統通過大數據平臺獲取數據進行分析。
三、建立統一的內存緩存模型
計算機的世界里沒有魔法,時間換空間、空間換時間是所有方案的基礎。
參考常用的MySQL INNODB引擎,為加快查詢速度會在內存中設置一塊內存作為緩沖區,將查詢結果從硬盤中加載到緩沖區,下次相同的查詢直接使用緩沖區數據。同樣的,如果要提高查詢響應速度,必須把服務數據緩存到內存中。單機內存有限,無法容納所有數據,且服務器重啟時整個內存重建所耗費的時間也是無法接受的,于是選擇用Redis與ES按照不同的使用場景來構造內存緩存。
1. 選擇主動緩存
常規的緩存方案:查詢構建+定期失效。對有大量重復查詢的環境效果很好,但在實際情況下,在某些場景卻無法發揮預想中的作用。

場景特征:
- 每個用戶只會打開一次客戶端,獲取一次插件信息,不會重復頻繁的去拉取列表。
- 訪問集中在8點到9點這個時間段。
- 使用被動緩存的后果:
- 8點前Redis緩存內是空的。
- 8點到9點,所有的列表信息都是***次獲取,查詢全部穿透緩存直接打到數據庫。
- 8點到9點之間獲取插件列表后做了插件的續訂或權限變更,由于緩存定時失效,導致更新無法反饋,用戶不斷刷新插件列表直到緩存失效獲取到更新結果。人為制造流量洪峰,Redis抗住的也是這些無用的人為重復調用量。
- 9點以后緩存逐漸過期,不再被使用。
一個測試性能很好,實際卻沒有用的緩存。
基于以上,緩存層決定通過主動構建的方式建立緩存。在數據修改后,將變化數據主動的加載到Redis緩存中,緩存不再設置過期時間。

有的服務每次獲取結果都要通過非常繁瑣的計算,如果這些繁瑣的計算集中在同一時間點,對于后端資源(數據庫)是非常大的負擔。
錯峰使用資源,把構建緩存的過程分散在離散的調用中,集中使用時直接調用緩存獲取最終結果。
上面提到過“類目服務”獲取類目層級列表需要多次查詢數據庫,這對數據庫是很大的負擔。
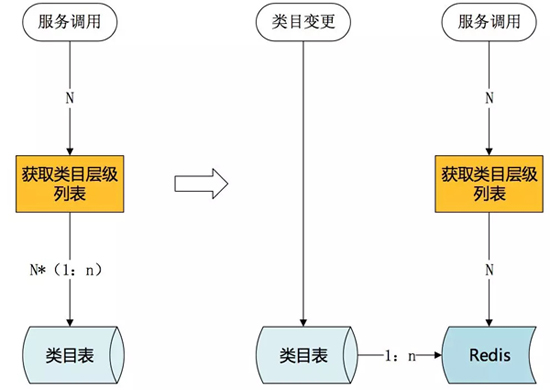
提前構建,在類目創建或類目變更時就重新構建類目層級列表,將結果存入緩存,高峰期使用時直接獲取已構建完成的類目層級列表。
2. 緩存碎片化
系統使用一段時間后,由于業務系統對服務數據需求的不一致,服務開發人員開始為每個外部系統提供一塊主動緩存。這些緩存完全不具備通用性但又數量眾多。每次服務模型修改,研發人員都要花大量時間去維護這些不通用的緩存。占用的緩存越來越多,但緩存的使用率并不高。
為去除冗余,降低維護工作量,最初按照數據表的維度將每一個表作為一個緩存。作為ES緩存可以采用這個方案,但是對于Redis緩存,這種緩存方式卻帶來了很大的麻煩。
數據庫表設計為保證強一致性,建表的時候嚴格依照范式,數據中很少有冗余,表也切的很小,查詢時通過聯合查詢來獲取整體數據。但Redis沒有聯合查詢的功能,因此不得不多次調用不同的緩存,多次調用大大降低了性能。對于查詢而言,數據庫會進行一些反范式操作。既然Reids緩存能夠支撐查詢,那么也可以做一定的冗余把這些關聯數據作為一個整體對象緩存起來。

對于服務開發人員而言,主要職責是根據環境變化,不斷的進化服務模型。服務開發人員維護一套***、最完整的服務模型并將模型開放出來;服務調用者,特別是只獲取服務數據的調用者完全可以通過對服務完整模型的自定義裁剪獲取自己所需要的數據,各開發人員只關注自己需要關注的地方,大大提高了工作效率。

3. 緩存構建方案
面臨問題:
- 服務緩存構建與變更屬于非核心流程,所以只能異步執行,通過MQ的方式與主流程解耦。
- 服務屬性修改入口眾多,通過MQ會出現操作重排序問題。
- 服務屬性修改入口眾多,每次修改或添加入口都必須跟著修改,業務侵入性強。
- 發送MQ的時機,事務中影響事務性能,當事務回滾時還需要發送補償;事務后又無法保證一定能發送。
解決方案:
- 采用binlake的方式進行異步緩存構建,與主流程解耦。 Binlake是京東一款通過解析MySQL的binlog日志,并通過MQ隊列進行解析受數據變更事件傳遞的數據異構產品。
- 數據庫是功能修改后唯一進行數據持久化的地方,僅需監控數據庫修改,就可獲知所有的服務屬性修改,不再需要跟著業務走,也不用擔心操作重排序。
- 事務提交才能產生binlog日志,binlog的產生標志數據修改出于確定狀態,不會出現回滾,解決MQ發送時機的問題。
- Binlog事件通過MQ發送,發送不成功不修改日志偏移量,下次繼續發送。接收隊列為回執確認式隊列,消費完成回執確認前會不斷進行重試,解決發送丟失或接收后丟失問題。

初期采取直接解析binlog報文,按照消息內容更新數據。為保證消費順序性,必須只有一個隊列進行消息傳遞,大大降低了效率,并埋下了單點的隱患。
解決方法是,MQ不作為數據變化的承載者,而是作為一個通知者。當緩存構造者接受到MQ的時候,從數據庫獲取***的服務屬性,更新到緩存中。通過拉式獲取完整的服務屬性數據,保證了數據的完整性、一致性。而主動拉取數據,不限制于消息本身,也不需要保證消息順序性,***解決效率與單點問題。在屬性被多次修改時,更能在其他修改消息未接收到時,就已經拉取到***數據更新了緩存數據,進一步提高了實時性。

***,單向事件觸發有很小的概率還是會發生數據不一致。解決辦法是,采用定時比對的方式,每個小時(可調整)通過時間戳比對當日數據與緩存數據差異,進行最終補償。

四、后記
解決了不同服務對相同資源的調用沖突,服務內不同的場景使用不同的資源支撐,創建了統一緩存層擺脫對數據庫的依賴。使用不同的方法解決了當統一緩存建立以后,如何使查詢擺脫了對數據庫的強依賴,服務性能得到了非常大的提升。
改造前支撐調用量:
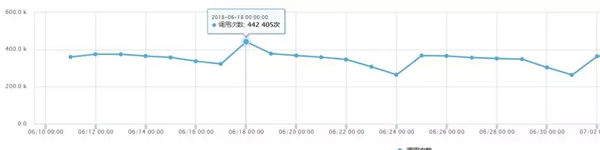
改造后支撐調用量:

通過以上演進,“可用插件列表服務”并發性能有了很大的提升。 2018年11.11零點調用量10分鐘內陡增6倍,平穩度過。
作者簡介:張俊卿,研發老兵,熱愛技術,喜歡挑戰。熟悉各種開源框架,對大型分布式系統有豐富的架構、設計經驗。性能卓越、設計優雅是其一生的追求。
【本文來自51CTO專欄作者張開濤的微信公眾號(開濤的博客),公眾號id: kaitao-1234567】