













華為云EI—實時流計算和時空數據庫助力用戶打開IoT無限可能
隨著技術的發展與市場需求的深入,IoT物聯網已進入快速發展期,給ICT行業帶來了廣闊的市場空間。在剛剛過去的2018華為中國生態伙伴大會期間,通過展區展示不難發現,在汽車、水、電、氣、工業設備等等領域,越來越多的終端聯接網絡,源源不斷的產生海量時序和時空數據,這些數據往往具有很強的時效性,隨著時間的推移,其價值也就急速衰減,因此如何應對海量時序/時空數據的高速存儲和查詢、如何對數據進行實時的檢測和監控、如何實時的挖掘出數據背后的價值都是很大的挑戰。那么,華為云EI企業智能又是如何幫助用戶與伙伴應對這些挑戰呢?
車聯網正成為IoT行業應用的先鋒
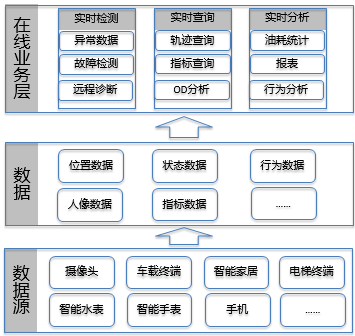
IoT典型場景
根據筆者在IoT領域的一些實踐經驗,將IoT領域的在線應用場景歸納為如下:
物聯網IoT數據源產生的數據大多是時序和時空數據,那么什么是時序數據和時空數據。我們一般認為時序數據是某個時間點發生了某件事情,但是在時序數據這個領域里定義的時序數據全都是跟數值有關的。舉一個簡單例子,一輛汽車在上午9點在某個加油站加油這條記錄,相當于一條日志,本身不能構成一個時序數據,但是如果今天我們每一秒鐘都記錄了該汽車的油箱里具體油量的值,那么今天的86400條油量記錄數據再加上每秒的時間點則構成了一個時序數據。那什么是時空數據呢?簡單來說,如果今天我們每一秒鐘都記錄了該汽車的位置信息(X\Y坐標),這些位置數據則構成了二維空間數據,那么這86400條的坐標記錄數據加上每秒的時間點則構成了一個時空數據。
對于這些時序和時空數據的在線業務可以簡單的分為三大類,實時檢測、實時查詢和實時分析。
實時檢測是期望可以實時的對異常數據、異常行為和故障進行檢測,快速返回給管理系統或者通知相關人員等。比如車隊管理則要求進行電子圍欄的檢測,一旦發現車輛行駛或停止的范圍超出了規定的地理空間范圍,則可以進行告警。或者貨運公司發現某貨運汽車并沒有按照正常的路線行駛,偏離了正常航道,也可以進行告警,從而進行實時糾偏。
實時查詢,主要是對于這些時序數據或者時空數據進行查詢以進行下一步的分析或進行展現,比如查詢早上7點到9點早高峰期間車的軌跡、車輛本周的油量變化曲線、用戶用電曲線等。由于IoT采集數據的頻率非常高,可能還需要繪制低精度的曲線。
實時分析,主要是對于采集到的指標數據進行分析,得到基于某些行業的知識,比如對于駕駛員的行為分析,對于汽車油耗的統計分析等。
IoT數據實時分析方案
在IoT領域,對于IoT數據的實時處理流程包括以下幾個步驟:
- 通過IoT Hub進行數據采集或者通過GPS的接入;
- 對數據進行實時檢測,或者預處理;
- 數據寫入數據庫/文件系統;
- 對數據庫/文件系統中的數據進行查詢、分析。
基于華為云服務來實現上述的處理流程,主要會如下圖所示的幾個服務:

IoT Hub可以對接物聯網終端進行數據采集;DIS(數據接入服務)采用kafka內核將數據接入到華為云,并和CloudStream(實時流計算服務)無縫對接;CloudStream從DIS消費數據進行實時檢測或分析,返回檢測結果給在線應用,或者增加一些分析數據寫入到CloudTable時序/時空數據庫中;CloudTable(表格存儲服務)作為毫秒級NoSQL數據庫可以支持海量的數據存儲,并提供時序/時空數據的查詢和實時分析;對于一些近實時的查詢分析可以通過spark內核的UQuery服務來進行。下面詳細介紹核心服務CloudStream實時流計算和CloudTable時序/時空數據庫能給企業帶來什么價值。
實時流計算,IoT的核心引擎
對于IoT場景的海量時序/時空數據,華為云CloudStream作為實時流式大數據分析服務,微秒級的計算性能為企業挖掘實時數據價值提供了核心能力,具體體現有以下顯著優勢:
1、雙引擎
IoT場景海量的數據實時計算必須需要有高性能的計算引擎支撐,既要滿足低時延高吞吐的性能要求,又要滿足數據一致性要求。另外,IoT場景多種多樣的業務也要求計算引擎能夠運行批量,流式,交互式,圖處理,機器學習等應用。目前業界主流的流計算引擎Flink和Spark Streaming都非常適合IoT場景,兩者以不同的設計思想(前者是原生流式計算,后者是微批處理計算)各領風騷,都有著活躍的開源社區支撐。
CloudStream集成了Flink和Spark Streaming,雙引擎方式很好的連接了開源生態,完全兼容開源版本Flink1.4和Spark2.2,方便業務人員平滑遷移線下業務上云。


2、基于地理位置分析的SQL 擴展
IoT大量業務場景需要對時空數據進行實時的地理位置分析,如電子圍欄、偏航檢測等。CloudStream擴展了Flink SQL,提供了基于地理位置分析的一系列Time GeoSpatial語法,方便業務人員使用SQL快速開發地理位置分析業務,其中DDL for Time GeoSpatial可以快速定義基本元素,例如點、線、多邊形、圓等;SQL Geospatial Scalar Functions 可以對基本元素進行基本操作,例如計算兩點間距離、判斷區域是否覆蓋、判斷點是否在區域內、移動位置計算、分析距離相交包含關系等;SQL Time Geospatial可以在窗口中對基本元素進行基本操作,例如計算多種窗口的平均速度和距離。
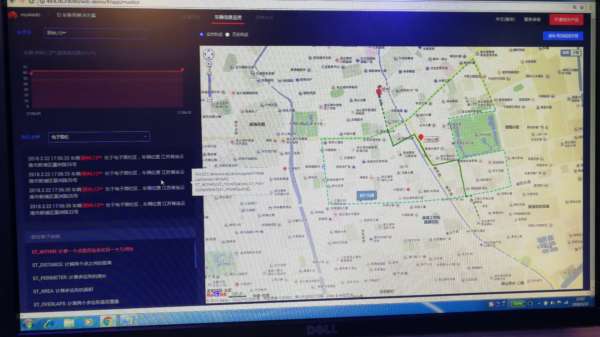
圖示為實時流計算服務的IoT算子輕松實現電子圍欄檢測
3、CEP on SQL
IoT大量業務場景需要實時檢測無盡數據流中的復雜模式,例如車輛異常行為檢測、工業設備異常運行狀態檢測。CloudStream擴展了Flink SQL,提供了非常高效的CEP on SQL的能力,提供了基于Match Recognize的模式匹配檢測,可以幫助業務人員使用SQL實現基于復雜事件規則的異常檢測業務,無需開發Flink PATTERN API自定義業務,只需要一行SQL查詢語句搞定,大大降低此類業務開發難度。

CloudTable時序/時空數據庫,為IoT數據而生
CloudTable是華為云上毫秒級的NoSQL數據庫,提供了HBase、OpenTSDB、GeoMesa接口,其中OpenTSDB和GeoMesa作為時序和時空數據庫為IoT行業而生,為時序和時空數據的高吞吐量的寫入和查詢提供了解決方案。
高性能時序數據庫
基于對分布式架構系統的良好支持和完善的生態,CloudTable選擇了OpenTSDB作為時序數據庫內核,并做了軟硬件的垂直性能優化,可以支持***別的寫入吞吐量和百萬數據點3秒之內的讀取性能,很好的解決物聯網領域海量數據寫入和讀取性能的問題。
同時,時序數據庫還提供了三種常用計算:插值、降精度和聚合。
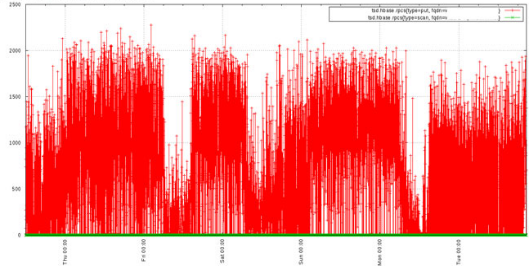
對于每秒都上報的數據,其中某一秒的數據因為某些原因丟失了,則可以通過插值進行補齊。如下圖紅色框內的點(圖a),對綠色線條和紅色線條的值進行求和聚合計算,如果沒有插值,則會出現結果突變的情況,如果進行了插值則是比較好的效果(圖b)
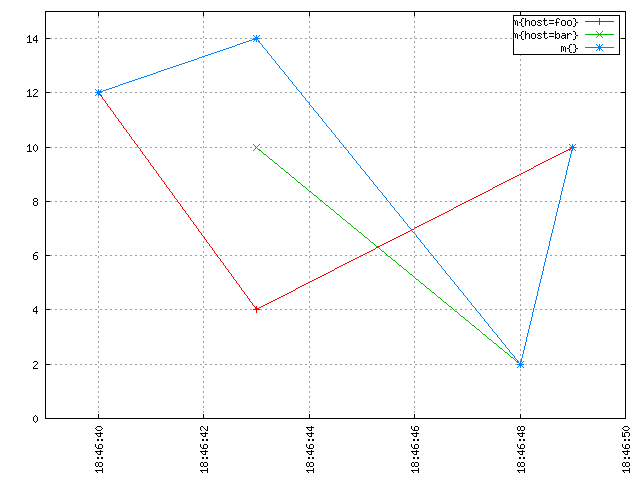
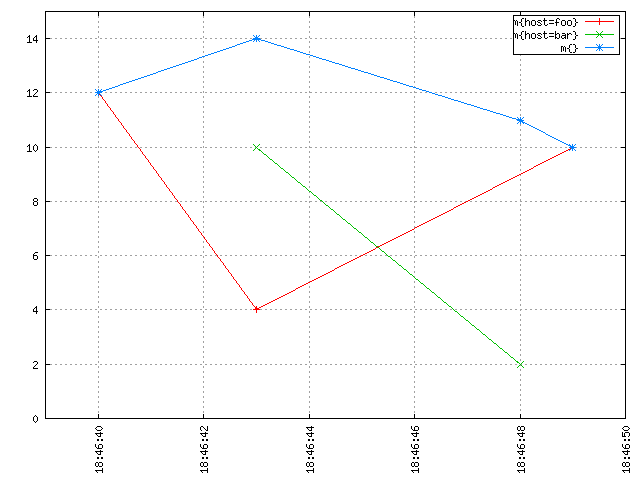
圖a 無插值求和結果 圖b 插值求和結果
降精度有助于提升查詢效率,同時可以提供更加清晰的曲線信息給在線應用。
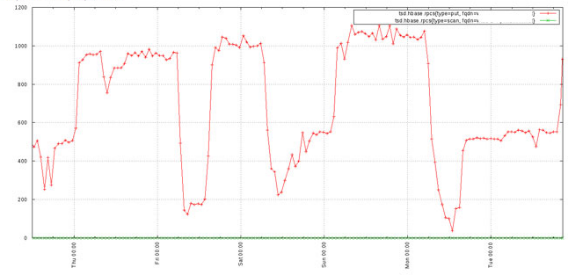
圖a 原始時序數據 圖b 降精度之后數據
時序數據庫中的聚合和傳統數據庫的聚合還有一些差異。時序數據庫中聚合是將多個獨立的時間線聚合成一個數據時間序列,類似于SQL里面的group by,但是此處的aggregation是按照每個時間戳和分組進行聚合。降精度計算中也可以使用不同的聚合函數進行降精度,而每個聚合函數中不僅會包含聚合的函數,也會包含插值的函數,對于缺失的數據,可以采用插值后的數據進行聚合。
時空數據庫
華為云CloudTable引入了地理大數據處理套件GeoMesa,可以幫助物聯網存儲和分析海量時空(spatio-temporal)數據,提供軌跡查詢、區域分布統計、區域查詢、密度分析、聚合、OD分析等功能。
GeoMesa基于Geohash編碼以及空間填充曲線的理論基礎,做到了將二維經緯度轉換成一維字符串,將三維時空(經緯度和時間)轉換成一維字符串,為高性能查詢打下了基礎。
通過CloudTable中GeoMesa,對于物聯網中時空維度的查詢簡單有效,舉個例子,比如
- 早上7點-9點,有哪些人/車出現在深圳市龍崗區坂田?
- 早上7點-9點,從深圳市南山區到深圳市龍崗區坂田的人/車的軌跡是怎么樣的?
- 晚上5:30-7:30,深圳市龍崗區坂田的人/車的軌跡是怎么樣的?
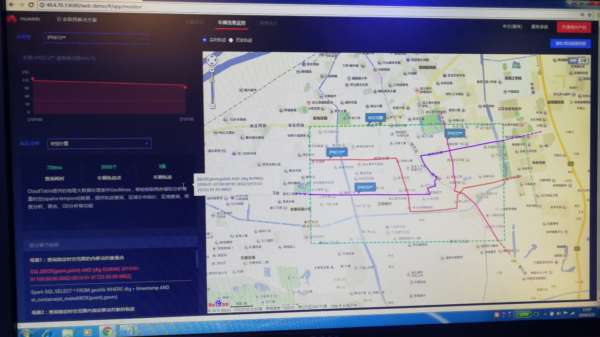
圖示為基于時空數據庫服務用CQL實現區域分析
通過以上的一些查詢,可以分析出行人/車的出行規律,進而進行附近的健身房、餐館、娛樂設施的推薦;分析出住宅區、工作區的聚集地;分析出同行的人的數量,抽象出公共巴士的路線,優化公共交通路線等等。通過時空數據的查詢和分析可以進一步挖掘出時空數據背后的價值。
Cloud2.0時代,越來越多的企業關注如何提升應用上云效率的同時,也在聚焦新技術給現行業務帶來的創新與改變。華為云實時流計算和時空數據庫幫助行業伙伴與客戶輕松實現IoT場景下時空時序數據的實時計算、存儲和查詢,為IoT海量數據和業務應用之間架起一道橋梁。除此之外,IoT場景還有很多即有趣又豐富的業務,華為云EI企業智能提供了豐富的大數據和AI服務,比如機器學習服務、圖引擎服務、深度學習服務等,將攜手與行業伙伴共同擴展更多能力,豐富更多算法和模型,從而打開IoT***可能。
點擊了解華為云EI: https://www.huaweicloud.com/ei


















