為什么列存儲能夠大幅度提高數據的查詢性能?
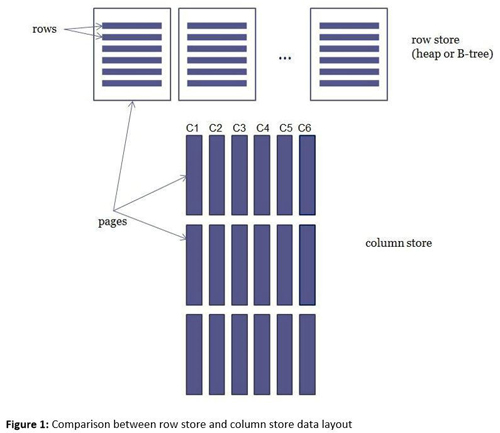
傳統的存儲數據的方式是逐行存儲(Row Store),每一個Page存儲多行數據,而列存儲(Column Store)把數據表中的每一列單獨存儲在Page集合中,這意味著,Page集合中存儲的是某一列的數據,而不是一行的所有列的數據。
為什么列存儲能夠大幅度提高數據的查詢性能呢?要回答這個問題,首先必須明白SQL Server引擎是怎樣讀取數據的。在讀取數據時,SQL Server每次都把所需數據所在的整個Page讀取到內存中,Page是數據讀取的最小單位。如果采用行存儲,每一個Page都存儲所有列的數據,每行的Size決定了單個Page能夠存儲的數據行數量。
我們可以粗略計算一下,如果一個數據行有10列,每列的平均Size是10B,一行的Size是100B,那么單個Page最多存儲80行(8060B/100B);如果采用列存儲模式,那么單個Page可以存儲806行(8060B/10B)。就單個Page存儲的數據行數量而言,列存儲是行存儲的10倍,SQL Server引擎把一個Page讀取到內存中,能夠獲取的數據行數量成10倍增加。
因此,采用列存儲模式時,每一個Page能夠存儲更多的數據行。在加載列存儲數據時,SQL Server只需要消耗少量的IO,就能把某一列的全部數據加載到緩存中。當從列很多的大表中讀取幾個列時,相比傳統的行存儲(Row Store)模式,列存儲(Column Store)能夠成千上萬倍地提高數據的讀取速度和查詢性能。
一,列存儲的物理實現
數據表(堆,B-Tree)以行存儲模式存儲數據,而列存儲索引以列存儲模式存儲數據,行存儲和列存儲的示例圖:
1,列存儲的優點
對于列存儲,列C1…C6 存儲在不同的Page組中,列存儲的有點是:
列存儲是把每一列都單獨存儲在Pages集合中,對于行存儲,哪怕只從數據表中選擇(select)一列,SQL Server引擎都把整個數據行所在的Page讀取到內存中,而使用列存儲索引,僅僅需要把select子句指定的列讀取到內存,不需要的列不會被讀取;因此,如果一個查詢請求只需要從少量的幾個列中獲得數據,列存儲能夠大幅度提高查詢性能;
由于單個數據列的數據冗余度更高,因此同一列的數據更容易被壓縮存儲,單個Page存儲更多的數據;
緩存***率提高,這是因為同一列的數據被高度壓縮,常用的Page被頻繁訪問而變得異常活躍,Buffer Manager把活躍的數據頁緩存到內存中,不常用的Page被換出(Page Out)。
更高級的查詢執行技術,列存儲模式讀取數據使用的是批處理模式(Batch Processing Mode),相對于傳統的行處理技術,查詢性能更高。
2,列存儲模式的物理實現
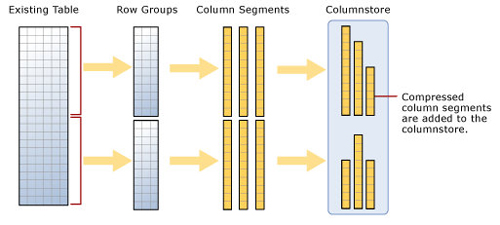
SQL Server引擎分三步實現列存儲:
step1,列存儲索引先把數據表的所有數據行分組,每個分組也稱作行組(Row Groups)。
step2,在每個行組中,每列的所有數據行構成一個列段(Column Segment),簡稱段。
step3,對每個段進行壓縮處理和編碼,每個段都單獨存儲在列存儲索引中。
3,編碼和壓縮
列存儲使用兩種編碼類型:基于字典(dictionary based)和基于值(value based),使用Vertipaq壓縮數據。
字典編碼是把唯一值編入字典,每一個唯一值都匹配一個序號,而序號用于索引字典,通過存儲序號來壓縮數據。如果數據表中存在大量的重復值,那么使用字典編碼壓縮率高。
值編碼用于整數類型,或小數類型,編碼的原理是把Value的范圍按照比例縮小或增大,并使用一個指數(exponent)來表示比例。如果整數(integer) 或小數(decimal)的值分布集中,那么使用基于值(value-based)編碼方法進行壓縮非常高效。
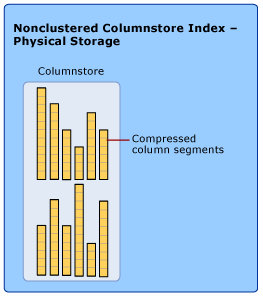
列存儲索引的物理存儲如下圖所示:
二,列存儲索引
SQL Server 2012開始引入列存儲模式,用戶通過創建列存儲索引(Column Store Index)來體驗列存儲模式帶來的性能提升。而列存儲模式非常適用于星型連接(Star- Join)類型的聚合查詢,所謂星型連接(Star-Join)的聚合查詢是指對一個大表(Large Table)和多個小表(Little Table)進行連接,并對Large Table 進行聚合查詢。在數據庫倉庫中,是指事實表和維度表的連接。
在大表上創建列存儲索引,SQL Server 引擎將充分使用批處理模式(Batch processing mode)來執行星型查詢,獲取更高的查詢性能。
典型的Star- Join的聚合查詢類似于下面的示例腳本:
- select lt.Grouping_Columns,
- AggregationFunction(bt.Columns)
- from dbo.LittleTable lt with(nolock)
- inner join dbo.BitTable bt with(nolock)
- on lt.Int_Col1=bt.Int_col1
- where ....
- group by lt.Grouping_Columns
在SQL Server 2012中,只能創建非聚集的列存儲索引,由于列存儲索引的每一列都有獨立的存儲空間(Page Set),因此,列存儲索引會包含數據表的所有列,這樣,每一個數據列都會被索引到。但是,并不是每一列都能獲得的相同的性能提升,這是因為,列存儲使用的壓縮算法對于具有大量重復值的字符或數值的數據,壓縮效率更高。對于列存儲索引而言,查詢性能的提升很大程度上依賴列數據的高度壓縮,這會大幅減少存儲該列數據所占用的數據頁(Data Page),進而大幅減少把數據加載到內存所耗費的內存和時間。
- CREATE [ NONCLUSTERED ] COLUMNSTORE INDEX index_name
- ON schema_name . table_name ( column [ ,...n ] )
- [ WITH ( DROP_EXISTING = { ON | OFF } | MAXDOP = max_degree_of_parallelism ) ]
- [ ON partition_scheme_name ( column_name ) | filegroup_name ]
一旦表上創建了非聚集的列存儲索引,基礎表就變成只讀的(read-only),不能對基礎表做任何更新(insert,update,delete 或merge)操作,如果需要修改數據,那么,首先要禁用列存儲索引,然后更新數據,***重建列存儲索引:
- ALTER INDEX mycolumnstoreindex ON mytable DISABLE;
- -- update mytable --
- ALTER INDEX mycolumnstoreindex on mytable REBUILD
由于創建或重建列存儲索引是IO密集型資源,十分耗費內存資源,因此必須在系統空閑的情況下,更新數據。
三,列存儲索引的存儲空間
列存儲索引首先把數據分組,然后每個行組中的每個列構成一個段(Segment),每段都是單獨存儲的,列存儲索引占用的存儲空間的大小是由所有段占用的硬盤空間的加和。
系統視圖:sys.column_store_segments 提供每個段的數據信息,每個段都是每個行組中的一列的數據的集合,例如,如果一個列存儲索引分為10個行組,每個行組有15個數據列,那么,該視圖將返回150個段。
View Code
可以看出,列存儲索引中每個段占用的硬盤空間是很少的,加載到內存所需要耗費的時間,IO次數和內存資源也是很少的,再配上性能更高的批處理模式,所以,列存儲能夠大幅度提高數據的查詢性能,特別是對星型聚合的查詢。
- select i.object_id
- ,object_name(i.object_id) as object_name
- ,i.name as index_name
- ,i.type_desc as index_type
- ,col_name(i.object_id,ic.column_id) as index_column_name
- ,sum(s.row_count) as row_count
- ,sum(s.on_disk_size)/1024/1024 as on_disk_size_mb
- from sys.column_store_segments s
- inner join sys.partitions p
- on s.partition_id=p.partition_id
- inner join sys.indexes i
- on p.object_id=i.object_id
- and p.index_id=i.index_id
- inner join sys.index_columns ic
- on i.object_id=ic.object_id
- and i.index_id=ic.index_id
- and s.column_id=ic.index_column_id
- group by i.object_id
- ,i.index_id
- ,i.name
- ,i.type_desc
- ,ic.column_id
- order by i.object_id
- ,i.name
- ,index_column_name