













程序員必看:性能大幅度提升的Twitter新系統架構
2013年8月3日《天空之城》在日本的熱播創下每秒新增143119條推文的Twitter峰值記錄,是Twitter平均每秒發推數(TPS)5700條的25倍。
值得注意的是,在這次毫無征兆的“洪峰”到來時,Twitter全新的系統平臺并沒有被潮水般涌來的推文堵塞而產生任何延遲甚至宕機。
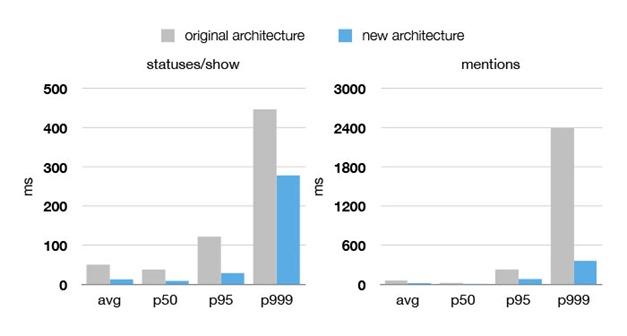
Twitter舊架構與新架構的性能對比
僅僅三年前,在2010年世界杯上,一個點球和一張紅牌產生的“推文風暴”都可能導致Twitter服務暫時失去響應,號稱地球脈搏的Twitter 經常“心肌梗塞”。過去三年Twitter的工程師們夜以繼日的工作,試圖用“縫縫補補”的方式完善Twitter系統,但最終隨著Twitter的快速 發展,這些方法的收效轉瞬即逝。
最終,Twitter痛下決心重新架構為人詬病的IT系統,新平臺上線運行后在性能和可靠性上都取得的翻天覆地的進步。無論是《天空之城》熱播還是超 級碗決賽都沒能卡住Twitter,而且新的架構也為Twitter推出多媒體推文卡片,跨設備消息同步等新功能的推出提供了有力的支撐。
最近,Twitter平臺工程副總裁Raffi Krikorian(@raffi)在Twitter官方博客 撰文分享了Twitter新架構的方法和經驗,摘要如下:
重新架構的緣由與問題癥結
2010年世界杯多次卡殼后,我們重新審視了系統,有以下幾點發現:
我們運行著全球最大的Ruby on Rails應用,200名工程師負責開發運維這個系統,但隨著用戶規模和服務數量的快速增長,系統所有的數據庫管理、Memcache鏈接以及公共API 的代碼屬于同一個代碼庫。這給工程師的學習、管理和并行開發都帶來巨大困難。
我們的MySQL存儲系統已經遇到性能瓶頸。整個數據庫中到處都是讀寫熱點。
通過添置硬件已經無法解決根本的系統問題——我們的前端Ruby服務器每秒處理交易的數量大大低于我們的預期,也與其硬件性能不成比例。
從軟件的角度看,我們陷入了“優化的陷阱”。我們是在犧牲代碼庫的可讀性和靈活性來換取性能和效率。
重新檢視系統,并設定三大目標/挑戰
一、新架構必須在性能、效率和可靠性上表現優異,減少延遲大幅提升客戶體驗;同時將服務器數量減少到原來的十分之一;新系統能夠隔離硬件問題防止其演變為大規模宕機。
二、解決單一代碼庫的種種弊端,嘗試松耦合的面向服務模型。我們的目標是鼓勵封裝與模塊化的最佳實踐,但這次是在系統層面,而不是類庫、模塊和數據包的層面。
三、最重要的是能夠支持新功能的快速發布。我們希望能夠由一些充分授權的小團隊能做出自主決策,并獨立發布一些用戶功能。
我們在動手前部分開發了一些概念驗證模型,最終我們確定了重建的原則、工具和架構。
系統重建的關鍵措施
一、前端服務:用JVM取代Ruby VM。通過重寫代碼庫將Ruby VM服務移植到JVM,性能提高了10倍,如今性能達到 10-20k請求/秒/主機。
二、編程模型:按服務類型對系統進行結構,建立一個統一的客戶端服務器庫并與負載均衡、故障轉移策略等綁定,從而讓工程師們能更加專注于應用和服務界面。
三、采用SOA面向服務架構,使并行開發成為可能。
四、推文的分布式存儲。即使將整塊單一應用分解成不同的“服務”,存儲依然是個巨大的瓶頸。過去Twitter采用的單一MySQL主數據庫只能線性 寫入推文,Twitter決定在推文的存儲上采用全新的分區策略,用Gizzard框架創建容錯的分片分布式數據庫存儲推文,但這樣一來就沒有辦法使用 MySQL的唯一ID生成功能。Twitter用 Snowflake解決了這個問題。
五、監測與統計。將單一應用轉化為復雜的SOA應用后,需要購買匹配的工具才能夠駕馭。Twitter的服務推出速度很快,同時還需要實現數據化的決策支持,Twitter的Runtime系統團隊為工程師開發了兩個工具Viz和 Zipkin。

















