列存儲:為什么你要掌握列存儲技術
一. 為什么要掌握列存儲技術
列存儲太流行了!!!
在大數(shù)據(jù)技術如火如荼的今天,掌握列存儲技術不論對于求職面試,技術選型,還是增加自己的知識廣度都是非常有幫助的。列存儲技術目前應用領域有:
- hadoop生態(tài)系統(tǒng):幾乎所有的Sql-On-Hadoop引擎都支持列存儲技術,比如SparkSql,Impala。parquet幾乎成為了交互式分析的標準存儲。
- NoSql數(shù)據(jù)庫:HBase,cassandra等數(shù)據(jù)庫。
- 傳統(tǒng)關系數(shù)據(jù)庫:Vertica,Infobright等傳統(tǒng)意義上面向列的關系數(shù)據(jù)庫,甚至oracle,sql-server都開始支持列存儲了。
二. 文章大綱
盡管列存儲技術已經(jīng)非常的火了,但是列存儲技術的中文資料還是太少了,在百度中搜索列存儲幾乎搜不到任何有價值的東西,列存儲技術的學習難度非常高。
作者對列存儲領域核心論文,開源技術做了一個整理,在接下來的系列文章中,分別對列存儲技術進行一一介紹。本系列文章大綱如下:
列存儲1:***個列存儲模型DSM
列存儲2:列存儲沒有取代行存儲背后的原因
列存儲3:列存儲的崛起
列存儲4:現(xiàn)代列存儲關系數(shù)據(jù)庫
列存儲5:元組物化策略
列存儲6:列存儲壓縮
列存儲7:向量化執(zhí)行引擎
列存儲8:列存儲在hadoop中的應用
列存儲9:數(shù)據(jù)庫存儲模型的發(fā)展趨勢
三.初識列存儲
數(shù)據(jù)庫領域中有兩種存儲方式:行存儲和列存儲。二者之間唯一的區(qū)別就是一個按行存儲,一個按照列存儲,如圖1。
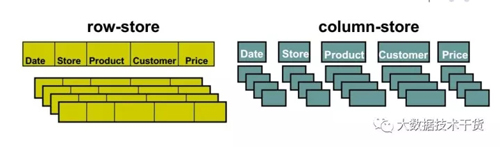
圖1行存儲和列存儲
我們再舉一個具體的例子,假設我們有一個employ關系表,employ表含有uuid,name,age三列,表總大小大約在3G左右。

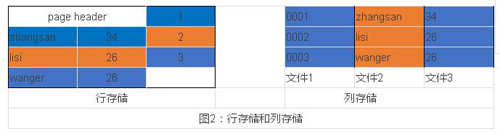
在行存儲中(圖2,左),表”水平”存儲,既按行連續(xù)存儲,首先***行,然后第二行。當執(zhí)行SELECT uuid FROM sales,需要遍歷表的所有數(shù)據(jù)(3G)來返回uuid列。
在列存儲中(圖2,右),表是”垂直”存儲的,每一列獨立的存儲為一個文件,sales表中的每一個列都有一個對應的文件存儲。當用戶執(zhí)行SELECT uuid FROM sales時,只需查詢uuid對應的文件即可(30M),而不必查詢其他列所對應的文件,從而極大的減少了磁盤訪問,提高查詢速度。
我們看到了列存儲的優(yōu)勢:列存儲查詢可以剔除無關的列,當查詢只有少量列時,可以極大的減少查詢的數(shù)據(jù)量,提高查詢速度。
此外,列存儲還具有很多行存儲所不具有的優(yōu)點:因為按列存儲,每一個列種內(nèi)存相似的概率比較大,例如age列,34,26,26.因此列存儲壓縮率要比行存儲高很多。此外,我們可以將列數(shù)據(jù)放到CPU cache中,然后使用SIMD指令執(zhí)行計算,從而提高計算速度。
列存儲概括起來具有如下優(yōu)點[文獻2],我們在接下來的系列文章中將分別詳細的介紹:
- 輕量級壓縮算法(Leight-Weight Compression)
- 延遲壓縮(Late Compression)
- 延遲物化(Late Materialization)
- 直接操作壓縮數(shù)據(jù)(Operating Directly on Compressed Data)
- 向量化執(zhí)行引擎(vectorized processing)
四.列存儲簡史
列存儲技術從誕生之日起,至今已有40多年時間了,列存儲技術的廣泛應用也不過是最近十年左右的事情。我們不由得好奇,既然列存儲技術出現(xiàn)已經(jīng)有40年了,為什么最近十年才開始流行,本文主要對列存儲的發(fā)展歷史做一個全局的綜述,后面系列文章將對列存儲做更細致的介紹。
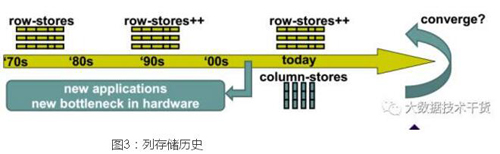
圖3:列存儲歷史
列存儲技術的發(fā)展主要經(jīng)歷了3個階段:
- 1970-1990:列存儲思想開始出現(xiàn)。在70s年代,列存儲技術最早應用在倒排文件中。76以后關系數(shù)據(jù)庫管理系統(tǒng)開始出現(xiàn),關系數(shù)據(jù)庫從出現(xiàn)開始就使用行存儲作為其標準存儲,到了1985年,Copeland在其A decomposition storage model論文中***提出了DSM存儲,作者對DSM和NSM做了比較全面的對比,這篇論文闡述了兩個最重要的觀點:首先,DSM可以取代NSM作為關系數(shù)據(jù)庫的存儲,其次,當查詢只有一個列或者少數(shù)幾個列時,DSM可以顯著的減少磁盤讀取次數(shù),從而提高查詢性能。
- 1990-2005:列存儲技術被應用在內(nèi)存數(shù)據(jù)庫中。到了90年代,CPU和內(nèi)存之間的速度差異越來越大,當CPU指令訪問內(nèi)存數(shù)據(jù)時,需要花費上百個周期來等待內(nèi)存返回結(jié)果,導致CPU大部分時間都浪費在等待內(nèi)存上,CPU訪問內(nèi)存開始成為新的瓶頸。在數(shù)據(jù)庫領域,最早注意到這一點的是Boncz.
- 1999年,Boncz在[3]中指出內(nèi)存訪問將成為數(shù)據(jù)庫系統(tǒng)新的瓶頸,這個觀點是非常令人興奮的,因為人們一直認為磁盤是數(shù)據(jù)庫系統(tǒng)最主要的瓶頸,而忽略了內(nèi)存延遲。受boncz論文的啟發(fā),在數(shù)據(jù)庫領域,逐漸出現(xiàn)了PAX等針對CPU cache優(yōu)化的存儲模型。因boncz在那個年代超前的觀點,VLDB在2009將其論文評為十年內(nèi)***論文。
- 2005-至今:讀優(yōu)化數(shù)據(jù)庫。2005年以后,互聯(lián)網(wǎng)應用越來越流行,企業(yè)存儲的數(shù)據(jù)體量也越來越大,人們不再滿足于簡單的存儲數(shù)據(jù),而是開始想著怎么從現(xiàn)有的數(shù)據(jù)中挖掘出價值。于是,TB,PB級數(shù)據(jù)倉庫開始出現(xiàn)。數(shù)據(jù)庫倉庫是典型的分析型應用,所謂的分析,就是海量數(shù)據(jù)基礎上(至少***)執(zhí)行復雜查詢(join,group by,filter)。此時,傳統(tǒng)的OLTP數(shù)據(jù)庫很難處理這種分析應用,于是新的面向分析的數(shù)據(jù)庫系統(tǒng)誕生了:面向列的關系數(shù)據(jù)。
C-store是***個現(xiàn)代的列存儲關系數(shù)據(jù)庫,其原型Michael Stonebraker(2014年圖靈獎得主,后文會介紹)等大牛開發(fā)的,后來慢慢演變成vertica,我們現(xiàn)在的很多列存儲技術用的都是c-store中的那一套,比如面向列的壓縮。
面向列的關系數(shù)據(jù)庫是典型的讀優(yōu)化數(shù)據(jù)庫,所謂的讀優(yōu)化數(shù)據(jù)庫,是指他們具有良好的復雜查詢性能,但是不支持單行插入,在線更新等操作。該類系統(tǒng)通常只支持批量加載,比如每天凌晨設置一個定時任務將數(shù)據(jù)加載到數(shù)據(jù)庫中。
五. 總結(jié)
列存儲就是每一個列或者多個列獨立的存儲為一個文件,這是所有列存儲系統(tǒng)的特點
列存儲查詢時可以”剔除”無關的列,從而極大的減少所查詢的數(shù)據(jù)量,提高查詢速度。
列存儲發(fā)展歷史經(jīng)歷了三個時期,1970-1990年,列存儲思想開始萌芽,DSM是***個列存儲模型。1990-2005年,人們主要關注列存儲數(shù)據(jù)庫在主內(nèi)存中的應用,monet,pax是該時期的代表。2005以后,面向分析的讀優(yōu)化數(shù)據(jù)庫開始流行。
列存儲相關技術:輕量級壓縮算法,延遲物化,直接操作壓縮數(shù)據(jù),向量化執(zhí)行引擎。