如何判斷LSTM模型中的過擬合與欠擬合
在本教程中,你將發現如何診斷 LSTM 模型在序列預測問題上的擬合度。完成教程之后,你將了解:
- 如何收集 LSTM 模型的訓練歷史并為其畫圖。
- 如何判別一個欠擬合、較好擬合和過擬合的模型。
- 如何通過平均多次模型運行來開發更魯棒的診斷方法。
讓我們開始吧。
1. Keras 中的訓練歷史
你可以通過回顧模型的性能隨時間的變化來更多地了解模型行為。
LSTM 模型通過調用 fit() 函數進行訓練。這個函數會返回一個叫作 history 的變量,該變量包含損失函數的軌跡,以及在模型編譯過程中被標記出來的任何一個度量指標。這些得分會在每一個 epoch 的***被記錄下來。
- ...
- history = model.fit ( ... )
例如,如果你的模型被編譯用來優化 log loss(binary_crossentropy),并且要在每一個 epoch 中衡量準確率,那么,log loss 和準確率將會在每一個訓練 epoch 的歷史記錄中被計算出,并記錄下來。
每一個得分都可以通過由調用 fit() 得到的歷史記錄中的一個 key 進行訪問。默認情況下,擬合模型時優化過的損失函數為「loss」,準確率為「acc」。
- model.com pile ( loss='binary_crossentropy', optimizer='adam', metrics= [ 'accuracy' ] )
- history = model.fit ( X, Y, epochs=100 )
- print ( history.history [ 'loss' ] )
- print ( history.history [ 'acc' ] )
Keras 還允許在擬合模型時指定獨立的驗證數據集,該數據集也可以使用同樣的損失函數和度量指標進行評估。
該功能可以通過在 fit() 中設置 validation_split 參數來啟用,以將訓練數據分割出一部分作為驗證數據集。
- history = model.fit ( X, Y, epochs=100, validation_split=0.33 )
該功能也可以通過設置 validation_data 參數,并向其傳遞 X 和 Y 數據集元組來執行。
- history = model.fit ( X, Y, epochs=100, validation_data= ( valX, valY ) )
在驗證數據集上計算得到的度量指標會使用相同的命名,只是會附加一個「val_」前綴。
- ...
- model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
- history =model.fit(X,Y,epochs=100,validation_split=0.33)
- print(history.history['loss'])
- print(history.history['acc'])
- print(history.history['val_loss'])
- print(history.history['val_acc'])
2. 診斷圖
LSTM 模型的訓練歷史可用于診斷模型行為。你可以使用 Matplotlib 庫來進行性能的可視化,你可以將訓練損失和測試損失都畫出來以作比較,如下所示:
- frommatplotlib importpyplot
- ...
- history =model.fit(X,Y,epochs=100,validation_data=(valX,valY))
- pyplot.plot(history.history['loss'])
- pyplot.plot(history.history['val_loss'])
- pyplot.title('model train vs validation loss')
- pyplot.ylabel('loss')
- pyplot.xlabel('epoch')
- pyplot.legend(['train','validation'],loc='upper right')
- pyplot.show()
創建并檢查這些圖有助于啟發你找到新的有可能優化模型性能的配置。
接下來,我們來看一些例子。我們將從損失最小化的角度考慮在訓練集和驗證集上的建模技巧。
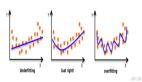
3. 欠擬合實例
欠擬合模型就是在訓練集上表現良好而在測試集上性能較差的模型。
這個可以通過以下情況來診斷:訓練的損失曲線低于驗證的損失曲線,并且驗證集中的損失函數表現出了有可能被優化的趨勢。
下面是一個人為設計的小的欠擬合 LSTM 模型。
- fromkeras.models importSequential
- fromkeras.layers importDense
- fromkeras.layers importLSTM
- frommatplotlib importpyplot
- fromnumpy importarray
- # return training data
- defget_train():
- seq =[[0.0,0.1],[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((len(X),1,1))
- returnX,y
- # return validation data
- defget_val():
- seq =[[0.5,0.6],[0.6,0.7],[0.7,0.8],[0.8,0.9],[0.9,1.0]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((len(X),1,1))
- returnX,y
- # define model
- model.add(LSTM(10,input_shape=(1,1)))
- model.add(Dense(1,activation='linear'))
- # compile model
- model.compile(loss='mse',optimizer='adam')
- # fit model
- X,y =get_train()
- valX,valY =get_val()
- history =model.fit(X,y,epochs=100,validation_data=(valX,valY),shuffle=False)
- # plot train and validation loss
- pyplot.plot(history.history['loss'])
- pyplot.plot(history.history['val_loss'])
- pyplot.title('model train vs validation loss')
- pyplot.ylabel('loss')
- pyplot.xlabel('epoch')
- pyplot.legend(['train','validation'],loc='upper right')
- pyplot.show()
運行這個實例會產生一個訓練損失和驗證損失圖,該圖顯示欠擬合模型特點。在這個案例中,模型性能可能隨著訓練 epoch 的增加而有所改善。

欠擬合模型的診斷圖
另外,如果模型在訓練集上的性能比驗證集上的性能好,并且模型性能曲線已經平穩了,那么這個模型也可能欠擬合。下面就是一個缺乏足夠的記憶單元的欠擬合模型的例子。
- fromkeras.models importSequential
- fromkeras.layers importDense
- fromkeras.layers importLSTM
- frommatplotlib importpyplot
- fromnumpy importarray
- # return training data
- defget_train():
- seq =[[0.0,0.1],[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((5,1,1))
- returnX,y
- # return validation data
- defget_val():
- seq =[[0.5,0.6],[0.6,0.7],[0.7,0.8],[0.8,0.9],[0.9,1.0]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((len(X),1,1))
- returnX,y
- # define model
- model.add(LSTM(1,input_shape=(1,1)))
- model.add(Dense(1,activation='linear'))
- # compile model
- model.compile(loss='mae',optimizer='sgd')
- # fit model
- X,y =get_train()
- valX,valY =get_val()
- history =model.fit(X,y,epochs=300,validation_data=(valX,valY),shuffle=False)
- # plot train and validation loss
- pyplot.plot(history.history['loss'])
- pyplot.plot(history.history['val_loss'])
- pyplot.title('model train vs validation loss')
- pyplot.ylabel('loss')
- pyplot.xlabel('epoch')
- pyplot.legend(['train','validation'],loc='upper right')
- pyplot.show()
運行這個實例會展示出一個存儲不足的欠擬合模型的特點。
在這個案例中,模型的性能也許會隨著模型的容量增加而得到改善,例如隱藏層中記憶單元的數目或者隱藏層的數目增加。

欠擬合模型的狀態診斷線圖
4. 良好擬合實例
良好擬合的模型就是模型的性能在訓練集和驗證集上都比較好。
這可以通過訓練損失和驗證損失都下降并且穩定在同一個點進行診斷。
下面的小例子描述的就是一個良好擬合的 LSTM 模型。
- fromkeras.models importSequential
- fromkeras.layers importDense
- fromkeras.layers importLSTM
- frommatplotlib importpyplot
- fromnumpy importarray
- # return training data
- defget_train():
- seq =[[0.0,0.1],[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((5,1,1))
- returnX,y
- # return validation data
- defget_val():
- seq =[[0.5,0.6],[0.6,0.7],[0.7,0.8],[0.8,0.9],[0.9,1.0]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((len(X),1,1))
- returnX,y
- # define model
- model.add(LSTM(10,input_shape=(1,1)))
- model.add(Dense(1,activation='linear'))
- # compile model
- model.compile(loss='mse',optimizer='adam')
- # fit model
- X,y =get_train()
- valX,valY =get_val()
- history =model.fit(X,y,epochs=800,validation_data=(valX,valY),shuffle=False)
- # plot train and validation loss
- pyplot.plot(history.history['loss'])
- pyplot.plot(history.history['val_loss'])
- pyplot.title('model train vs validation loss')
- pyplot.ylabel('loss')
- pyplot.xlabel('epoch')
- pyplot.legend(['train','validation'],loc='upper right')
- pyplot.show()
運行這個實例可以創建一個線圖,圖中訓練損失和驗證損失出現重合。
理想情況下,我們都希望模型盡可能是這樣,盡管面對大量數據的挑戰,這似乎不太可能。

良好擬合模型的診斷線圖
5. 過擬合實例
過擬合模型即在訓練集上性能良好且在某一點后持續增長,而在驗證集上的性能到達某一點然后開始下降的模型。
這可以通過線圖來診斷,圖中訓練損失持續下降,驗證損失下降到拐點開始上升。
下面這個實例就是一個過擬合 LSTM 模型。
- fromkeras.models importSequential
- fromkeras.layers importDense
- fromkeras.layers importLSTM
- frommatplotlib importpyplot
- fromnumpy importarray
- # return training data
- defget_train():
- seq =[[0.0,0.1],[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((5,1,1))
- returnX,y
- # return validation data
- defget_val():
- seq =[[0.5,0.6],[0.6,0.7],[0.7,0.8],[0.8,0.9],[0.9,1.0]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((len(X),1,1))
- returnX,y
- # define model
- model.add(LSTM(10,input_shape=(1,1)))
- model.add(Dense(1,activation='linear'))
- # compile model
- model.compile(loss='mse',optimizer='adam')
- # fit model
- X,y =get_train()
- valX,valY =get_val()
- history =model.fit(X,y,epochs=1200,validation_data=(valX,valY),shuffle=False)
- # plot train and validation loss
- pyplot.plot(history.history['loss'][500:])
- pyplot.plot(history.history['val_loss'][500:])
- pyplot.title('model train vs validation loss')
- pyplot.ylabel('loss')
- pyplot.xlabel('epoch')
- pyplot.legend(['train','validation'],loc='upper right')
- pyplot.show()
運行這個實例會創建一個展示過擬合模型在驗證集中出現拐點的曲線圖。
這也許是進行太多訓練 epoch 的信號。
在這個案例中,模型會在拐點處停止訓練。另外,訓練樣本的數目可能會增加。

過擬合模型的診斷線圖
6. 多次運行實例
LSTM 是隨機的,這意味著每次運行時都會得到一個不同的診斷圖。
多次重復診斷運行很有用(如 5、10、30)。每次運行的訓練軌跡和驗證軌跡都可以被繪制出來,以更魯棒的方式記錄模型隨著時間的行為軌跡。
以下實例多次運行同樣的實驗,然后繪制每次運行的訓練損失和驗證損失軌跡。
- fromkeras.models importSequential
- fromkeras.layers importDense
- fromkeras.layers importLSTM
- frommatplotlib importpyplot
- fromnumpy importarray
- frompandas importDataFrame
- # return training data
- defget_train():
- seq =[[0.0,0.1],[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((5,1,1))
- returnX,y
- # return validation data
- defget_val():
- seq =[[0.5,0.6],[0.6,0.7],[0.7,0.8],[0.8,0.9],[0.9,1.0]]
- seq =array(seq)
- X,y =seq[:,0],seq[:,1]
- XX =X.reshape((len(X),1,1))
- returnX,y
- # collect data across multiple repeats
- train =DataFrame()
- val =DataFrame()
- fori inrange(5):
- # define model
- model.add(LSTM(10,input_shape=(1,1)))
- model.add(Dense(1,activation='linear'))
- # compile model
- model.compile(loss='mse',optimizer='adam')
- X,y =get_train()
- valX,valY =get_val()
- # fit model
- history =model.fit(X,y,epochs=300,validation_data=(valX,valY),shuffle=False)
- # story history
- train[str(i)]=history.history['loss']
- val[str(i)]=history.history['val_loss']
- # plot train and validation loss across multiple runs
- pyplot.plot(train,color='blue',label='train')
- pyplot.plot(val,color='orange',label='validation')
- pyplot.title('model train vs validation loss')
- pyplot.ylabel('loss')
- pyplot.xlabel('epoch')
- pyplot.show()
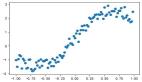
從下圖中,我們可以在 5 次運行中看到欠擬合模型的通常趨勢,該案例強有力地證明增加訓練 epoch 次數的有效性。

模型多次運行的診斷線圖
擴展閱讀
如果你想更深入地了解這方面的內容,這一部分提供了更豐富的資源。
- Keras 的歷史回調 API(History Callback Keras API,https://keras.io/callbacks/#history)
- 維基百科中關于機器學習的學習曲線(Learning Curve in Machine Learning on Wikipedia,https://en.wikipedia.org/wiki/Learning_curve#In_machine_learning)
- 維基百科上關于過擬合的描述(Overfitting on Wikipedia,https://en.wikipedia.org/wiki/Overfitting)
原文:https://machinelearningmastery.com/diagnose-overfitting-underfitting-lstm-models/
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】