華為OCR技術讓人工智能應用擁有一雙“慧眼”
隨著深度學習在大規模圖像分類數據集上獲得巨大成功,越來越多的公司將業務聚焦在圖像處理的計算機視覺領域,其中一個關鍵技術就是圖像OCR(optical character recognition,光學字符識別)。
什么是OCR呢?
OCR是指光學設備(掃描儀、數碼相機等)檢查紙上打印的字符,通過檢測暗、亮的模式確定其形狀,然后用字符識別方法將形狀翻譯成計算機文字的過程,其本質就是利用光學設備去捕獲圖像并識別文字,將人眼的能力延伸到機器上。
OCR在物流、醫療、金融、保險、傳統制造業等領域都有著廣泛的應用。如此多的領域朝著智能化和物流數字化方向發展,都要求具有高效穩健的OCR技術,通過機器自動識別圖片文字的智能化應用前景十分可觀。但是圖片(包括掃描件和手機照片)往往存在噪聲、傾斜、變形、背景復雜、文字多樣等各種問題,文字定位和識別的難度很大。華為大數據&AI團隊通過強力投入,研發出華為自己的OCR拳頭產品。重點應用場景之一是表格單據的識別,通過結構化輸出表格單據中的文字信息,在業務審核中給公司節省大量的人力。
華為OCR依托于華為云強大的計算和處理能力,將陸續推出單據類、證件類和通用文本的文字檢測和識別服務。
價值在哪?
華為公司在全球每年有幾百萬份銷售訂單,使得每年需要處理上百萬份單據。現在的單據處理方式還停留在通過人工方式將單據內容手動錄入到系統中,人工錄入的方式除了效率低以外,還存在員工疏忽或者疲勞導致的誤操作。如何快速、準確的處理如此數量龐大的單據成為了一大訴求。通過該OCR技術自動采集關鍵數據,建立數據資產,并進行大數據分析,可以有效降低華為的運營成本,提升業務效率。通過智能化服務,可幫助華為在全球節省大量人力;分析海關估價等關鍵信息,控制每年千萬美金級的風險敞口,業務流程自動化比例大幅提升。
不僅限于華為內部,華為OCR有效利用華為云計算的優勢,基于松耦合、高復用性和易于維護的原則,建設了OCR公有云服務,以統一的網絡訪問接口方式,對外部應用系統提供滿足不同需求的OCR識別服務,可以為醫療、海關、物流、金融、傳統制造業等領域的企業提供高效、低成本的數據采集方案,大大節省了人工數據采集、構建信息系統和維護升級的成本,讓企業更智能。目前,在金融領域,華為為某知名保險公司提供保單識別、醫療單據識別,幫助保險公司提高工作效率,加快理賠的速度;在傳統制造業領域,華為幫助某公司識別藥品說明書,幫助公司快速構建藥品說明書的信息庫。
有什么難點和挑戰?
華為的OCR場景包括對掃描的表格單據、手機拍攝的照片進行文字信息提取和識別,考慮到客戶和應用場景的多樣性,主要面臨以下挑戰:
- 掃描的單據往往存在虛線干擾、版面缺失、傾斜、暗光、扭曲、噪聲等情況,定位難度大。
- 文字千變萬化,例如字體、字號、顏色、筆畫寬度等不固定,方向任意;小數點、近似英文數字、特殊符號、連接詞、藝術字等,容易被漏檢或誤識別。
- 語言種類繁多,經常是中英文混合,多種語言混合等場景,識別難度加大。
- 表格單據經常存在蓋章(印章覆蓋文字)、錯行(文字溢出表格單元,與表格線交叉)的情況,也造成文字識別干擾,極大影響識別準確率。
- 拍照上傳的圖片存在噪聲、模糊、光線變化、形變、復雜背景干擾等問題,對文字定位和識別的準確度是巨大挑戰。
華為有什么關鍵技術?
對于上述挑戰,華為OCR的總體技術方案包括圖像預處理、業界領先的深度學習文字定位和文字識別引擎以及后處理糾錯模塊3部分,并對各個模塊進行技術突破,取得了明顯的效果:
- 圖像預處理技術:針對蓋章和錯行的問題,通過對Autoencoder自編碼器模型的大幅改進,直接分離文字、表格線與蓋章3種目標,消除了表格線和蓋章對文字的干擾,同時消除噪聲,極大簡化了后續的文字識別和版面分析過程,提高了準確度。該模型采用FCN(Fully Convolutional Network,全卷積網絡)網絡結構,并將原始圖片輸入層與后面多層直接相連,減少信息損失和文字變形。該模型能適應各種尺寸的圖片輸入,訓練和預測速度都很快。
- 文字定位技術:
- 表單文字定位:在處理表單類文本識別場景,采用傾斜矯正算法、最大輪廓提取算法、表格線去干擾算法和文字框定位算法等多種技術手段相互融合。
- 證件文字定位:為支持各種復雜場景下的證件OCR,采用基于深度學習和全卷積網絡的關鍵點定位技術將證件從各種復雜背景中提取出來,并進行方向和透視角度的矯正;然后將文字定位轉換成對物體檢測問題,改進SSD物體檢測框架,以適應文字長寬比極大的特點;采用多尺度輸入的方法,進一步提高文字定位的精度。
- 基于視覺注意力的深度學習文字識別技術:采用視覺注意力模型(CNN+LSTM+Attention技術),該模型首先在圖像上采用滑動窗口CNN(Convolutional Neural Network,卷積神經網絡)的方法進行圖像特征提取;然后在CNN的頂部堆疊一個LSTM(Long Short-Term Memory networks,長短期記憶網絡)進行序列特征提取;最后,使用注意力模型作為解碼器輸出最終的文字序列。
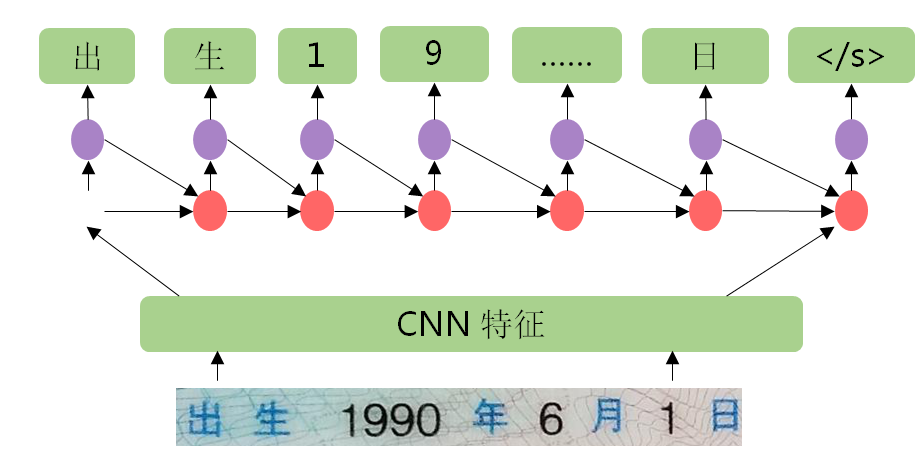
圖1基于視覺注意力的深度學習文字識別技術
- 多策略后驗糾錯技術:對于固定模板的表單或證件,采用詞庫+編輯距離+集成學習的策略,對常見詞進行詞典庫數據收集,采用編輯距離進行更正。對關鍵數字部分,采取多個圖像預處理手段進行集成學習給出最終結果置信度,并進行可能出錯的報警;對于通用的文字識別,特別是中文長句識別,對OCR識別出的Top N結果,采用語言模型+Viterbi算法,計算最短路徑,輸出概率最高的結果。

圖2表格單據OCR解決方案
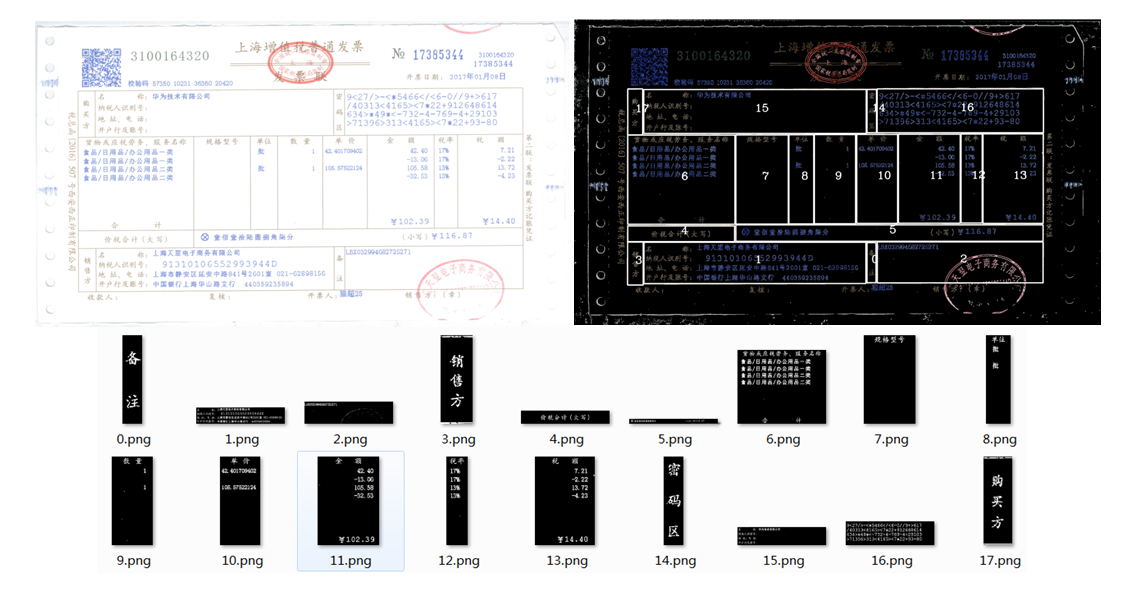
圖3發票的定位效果
服務優勢
- 識別精度高:采用業界先進的深度學習模型以及遷移學習模型優化技術,萬億級海量訓練樣本,識別率和召回率達到業界領先水平。
- 魯棒性好:產品采用黑邊處理、自動糾偏、去噪、圖像自動旋轉、多種二值化等方法處理圖像,能適應任意版面/旋轉/扭曲/復雜背景/光照/模糊場景下的文字檢測識別。
- 支持多類單據識別:支持多種類型的表格、發票等單據識別,結構化輸出,幫助客戶快速便捷的完成紙質單據的電子化;也可為客戶定制各種個性化的OCR服務,滿足不同客戶的需求。
- 服務穩定高效:采用最新的大數據集群技術,后臺服務器穩定可靠,系統毫秒級響應。
- 云服務,標準API支持:服務使用簡單便捷,兼容性強。
我們下一步將有什么?
目前華為還在布局各類證件、通用文字識別等相關的OCR產品,將會陸續提供更豐富的OCR服務和基于OCR的解決方案,支持更多應用場景,滿足更多客戶的需求。例如,通過拍照掃描等方式,提供身份信息的快速自動錄入體驗,以提高邊檢/酒店/旅游/公共安全以及電商等行業領域的工作效率;自然場景OCR可以捕獲現實中多種場景下的文字,可有效支持虛擬現實、人機交互、圖像檢索、無人駕駛、車牌識別、工業自動化等領域中廣泛的應用。