TensorFlow分布式計算機制解讀:以數據并行為重
Tensorflow 是一個為數值計算(最常見的是訓練神經網絡)設計的流行開源庫。在這個框架中,計算流程通過數據流程圖(data flow graph)設計,這為更改操作結構與安置提供了很大靈活性。TensorFlow 允許多個 worker 并行計算,這對必須通過處理的大量訓練數據訓練的神經網絡是有益的。此外,如果模型足夠大,這種并行化有時可能是必須的。在本文中,我們將探討 TensorFlow 的分布式計算機制。

TensorFlow 計算圖示例
數據并行 VS. 模型并行
當在多個計算節點間分配神經網絡訓練時,通常采用兩種策略:數據并行和模型并行。在前者中,在每個節點上單***建模型的實例,并饋送不同的訓練樣本;這種架構允許更高的訓練吞吐量。相反,在模型并行中,模型的單一實例在多個節點間分配,這種架構允許訓練更大的模型(可能不一定適合單節點的存儲器)。如果需要,也可以組合這兩種策略,使給定模型擁有多個實例,每個實例跨越多個節點。在本文中,我們將重點關注數據并行。

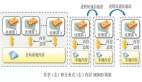
數據并行與模型并行的不同形式。左:數據并行;中:模型并行;右:數據并行與模型并行
TensorFlow 中的數據并行
當使用 TensorFlow 時,數據并行主要表現為兩種形式:圖內復制(in-graph replication)和圖間復制(between-graph replication)。兩種策略之間最顯著的區別在于流程圖的結構與其結果。
1. 圖內復制
圖內復制通常被認為是兩種方法中更簡單和更直接(但更不可擴展的)的方法。當采用這種策略時,需要在分布式的主機上創建一個包含所有 worker 設備中副本的流程圖。可以想象,隨著 worker 數量的增長,這樣的流程圖可能會大幅擴展,這可能會對模型性能產生不利影響。然而,對于小系統(例如,雙 GPU 臺式計算機),由于其簡單性,圖內復制可能是***的。
以下是使用單個 GPU 的基線 TensorFlow 方法與應用圖內復制方法的代碼片段的對比。考慮到圖內復制方法與擴展(scaling)相關的問題,我們將僅考慮單機、多 GPU 配置的情況。這兩個代碼片段之間的差異非常小,它們的差異僅存在于:對輸入數據的分塊,使得數據在各 worker 間均勻分配,遍歷每個含有 worker 流程圖的設備,并將來自不同 worker 的結果連接起來。通過少量代碼更改,我們可以利用多個設備,這種方法使可擴展性不再成為大障礙,從而在簡單配置下更受歡迎。
- # single GPU (baseline) 單個 GPU(基線)
- import tensorflow as tf
- # place the initial data on the cpu
- with tf.device('/cpu:0'):
- input_data = tf.Variable([[1., 2., 3.],[4., 5., 6.],[7., 8., 9.],[10., 11., 12.]])
- b = tf.Variable([[1.], [1.], [2.]])# compute the result on the 0th gpuwith tf.device('/gpu:0'):
- output = tf.matmul(input_data, b)# create a session and runwith tf.Session() as sess:
- sess.run(tf.global_variables_initializer())print sess.run(output)
- # in-graph replication 圖內復制
- import tensorflow as tf
- num_gpus = 2
- # place the initial data on the cpu
- with tf.device('/cpu:0'):
- input_data = tf.Variable([[1., 2., 3.],[4., 5., 6.],[7., 8., 9.],[10., 11., 12.]])
- b = tf.Variable([[1.], [1.], [2.]])# split the data into chunks for each gpu
- inputs = tf.split(input_data, num_gpus)
- outputs = []# loop over available gpus and pass input datafor i in range(num_gpus):with tf.device('/gpu:'+str(i)):
- outputs.append(tf.matmul(inputs[i], b))# merge the results of the deviceswith tf.device('/cpu:0'):
- output = tf.concat(outputs, axis=0)# create a session and runwith tf.Session() as sess:
- sess.run(tf.global_variables_initializer())print sess.run(output)
這些更改也可以通過檢查下面的 TensorFlow 流程圖來可視化。增加的 GPU 模塊說明了原始方法的擴展方式。

圖內復制的可視化。左:原始圖。右:圖內復制的結果圖。
2. 圖間復制
認識到圖內復制在擴展上的局限性,圖間復制的優勢在于運用大量節點時保證模型性能。這是通過在每個 worker 上創建計算圖的副本來實現的,并且不需要主機保存每個 worker 的圖副本。通過一些 TensorFlow 技巧來協調這些 worker 的圖——如果兩個單獨的節點在同一個 TensorFlow 設備上分配一個具有相同名稱的變量,則這些分配將被合并,變量將共享相同的后端存儲,從而這兩個 worker 將合并在一起。
但是,必須確保設備的正確配置。如果兩個 worker 在不同的設備上分配變量,則不會發生合并。對此,TensorFlow 提供了 replica_device_setter 函數。只要每個 worker 以相同的順序創建計算圖,replica_device_setter 為變量分配提供了確定的方法,確保變量在同一設備上。這將在下面的代碼中演示。
由于圖間復制在很大程度上重復了原始圖,因此多數相關的修改實際上都在集群中節點的配置上。因此,下面的代碼段將只針對這一點進行改動。重要的是要注意,這個腳本通常會在集群中的每臺機器上執行,但具體的命令行參數不同。下面來逐行研究代碼。
- import sysimport tensorflow as tf
- # specify the cluster's architecture
- cluster = tf.train.ClusterSpec({'ps': ['192.168.1.1:1111'],'worker': ['192.168.1.2:1111','192.168.1.3:1111']})# parse command-line to specify machine
- job_type = sys.argv[1] # job type: "worker" or "ps"
- task_idx = sys.argv[2] # index job in the worker or ps list# as defined in the ClusterSpec# create TensorFlow Server. This is how the machines communicate.
- server = tf.train.Server(cluster, job_name=job_type, task_index=task_idx)# parameter server is updated by remote clients.# will not proceed beyond this if statement.if job_type == 'ps':
- server.join()else:# workers onlywith tf.device(tf.train.replica_device_setter(
- worker_device='/job:worker/task:'+task_idx,
- clustercluster=cluster)):# build your model here as if you only were using a single machinewith tf.Session(server.target):# train your model here
運行分布式 TensorFlow 的***步是使用 tf.train.ClusterSpec 來指定集群的架構。節點通常分為兩個角色(或「job」):含有變量的參數服務器(「ps」)和執行大量計算的「worker」。下面提供每個節點的 IP 地址和端口。接下來,腳本必須確定其 job 類型和在網絡中的索引;這通常是通過將命令行參數傳遞給腳本并解析來實現的。job_type 指定節點是運行 ps 還是 worker 任務,而 task_idx 指定節點在 ps 或 worker 列表中的索引。使用以上變量創建 TensorFlow 服務器,用于連接各設備。
接下來,如果節點是參數服務器,它只連接它們的線程并等待它們終止。雖然似乎沒有特定的 ps 代碼,但圖元素實際上是由 worker 推送到 ps 的。
相反,如果設備是 worker,則使用 replica_device_setter 構建我們的模型,以便在前面討論的這些 ps 服務器上連續分配參數。這些副本將在很大程度上與單機的流程圖相同。***,我們創建一個 tf.Session 并訓練我們的模型。
總結
希望本文清楚地闡述了與分布式 TensorFlow 相關的一些術語和技術。在以后的文章中,我們將詳細探討與此相關及其它的主題。
原文:https://clindatsci.com/blog/2017/5/31/distributed-tensorflow
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】