分布式計算之數據質量漫談
一 概述
1 數據質量問題無處不在
基本上每個用數據的同學,都遇到過以下類似的問題。
- 表沒有按時產出,影響下游,嚴重的甚至可能影響線上效果。
- 打點缺失,看了報表才發現數據對不上。
- 數據統計出來,uv大于pv,很尷尬。
- 數據產出暴增,本來1000萬的數據變成了3000萬。
- 字段里面的枚舉值和注釋里面的對不上,沒人能解釋。
- 某些維度缺失,沒法做進一步的數據分析。
- 做了一通分析,發現結果很離譜,一點點向前分析,發現打點有問題。
- ……
以上都是數據質量的問題。本文嘗試找到一種方法,能夠盡可能的發現數據質量問題并解決之。
2 數據標準
談到數據質量,就必須了解評價數據質量的維度。DAMA UK 提出了數據質量的六個核心維度,見圖1。
注:DAMA International (國際數據管理協會)成立于1980年,是一個由技術和業務專業人員組成的國際性數據管理專業協會,作為一個非營利的機構,獨立于任何廠商,旨在世界范圍內推廣并促進數據管理領域的概念和最佳實踐,為數字經濟打下理論和實踐基礎。全球會員近萬人,在世界48個國家成立有分會。
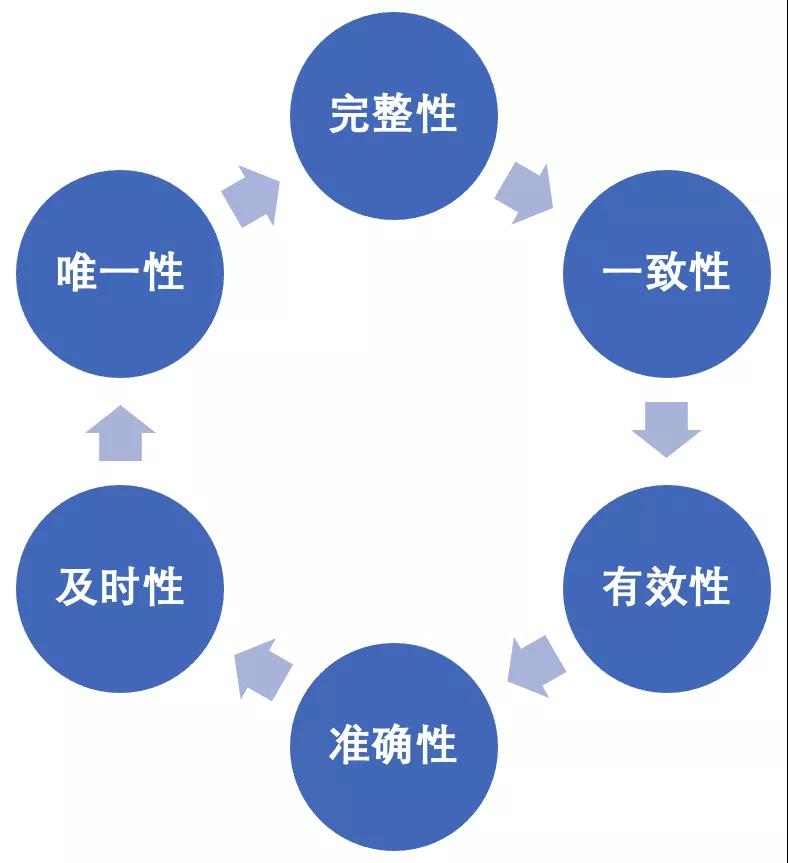
圖1 數據質量維度
- 完整性Completeness:完整性是指數據信息信息是否存在缺失的狀況,常見數據表中行的缺失,字段的缺失,碼值的缺失。比如雖然整體pv是正確的,但在某個維度下,只有部分打點,這就是存在完整性的問題。不完整的數據所能借鑒的價值就會大大降低,也是數據質量問題最為基礎和常見的問題。常見統計sql:count( not null) / count(*)
- 有效性Validity :有效性一般指范圍有效性、日期有效性、形式有效性等主要體現在數據記錄的規范和數據是否符合邏輯。規范指的是,一項數據存在它特定的格式,如:手機號碼一定是11位的數字;邏輯指的是,多項數據間存在著固定的邏輯關系,如:PV一定是大于等于UV的。
- 準確性Accuracy:準確性是指數據記錄的信息是否存在異常或錯誤。最為常見的數據準確性錯誤就如亂碼。其次,異常的大或者小的數據也是不符合條件的數據。準確性可能存在于個別記錄,也可能存在于整個數據集,例如數量級記錄錯誤。這類錯誤則可以使用最大值和最小值的統計量去審核。
- 及時性Timeliness:及時性是指數據從開始處理到可以查看的時間間隔。及時性對于數據分析本身的影響并不大,但如果數據建立的時間過長,就無法及時進行數據分析,可能導致分析得出的結論失去了借鑒意義。比如:實時業務大盤數據,及時反映業務關鍵指標的情況,暴露業務指標的異常波動,機動響應特殊突發情況都需要數據的及時更新和產出。某些情況下,數據并不是單純為了分析用而是線上策略用,數據沒有及時產出會影響線上效果。
- 一致性Consistency:一致性是指相同含義信息在多業務多場景是否具有一致性,一般情況下是指多源數據的數據模型不一致,例如:命名不一致、數據結構不一致、約束規則不一致。數據實體不一致,例如:數據編碼不一致、命名及含義不一致、分類層次不一致、生命周期不一致等。
- 唯一性Uniqueness: 在數據集中數據不重復的程度。唯一數據條數,和總數據條數的百分比。比如 count(distinct business key) / count(*),一般用來驗證主鍵唯一性。
3 數據的生命周期
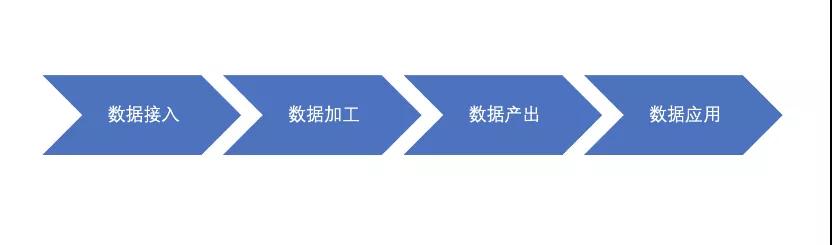
圖2 數據生命周期
- 數據接入:接入上游表輸入或者其它數據源的數據。
- 數據加工:編寫sql生成目標數據表。
- 數據產出:定時調度任務生成數據表。
- 數據應用:下游數據分析、報表等應用數據。
在上面任何一個環節中,都可能出現數據質量的問題,提升數據質量需要從數據接入、數據加工、數據產出、數據應用、效果跟蹤等全流程進行把控,全局觀很重要,不拘一點,才能看的更全面。
二 如何解決數據質量問題
數據質量是數據的生命線,沒有高質量的數據,一切數據分析、數據挖掘、數據應用的效果都會大打折扣,甚至出現完全錯誤的結論,或者導致資損。然而數據質量問題卻是廣泛存在的,且治理的難度很大,因為數據的生產、加工、流轉、應用涉及到業務運營、生產系統、數據系統、數據產品等上下游鏈路幾十個環節,每個環節都可能引入數據質量問題。
集團很多BU都有成體系的解決數據質量的方案,集團也有很多工具來解決數據質量問題。本文不詳細介紹此類工具的使用,主要聚焦在數據開發過程中因為數據研發同學經驗不足而導致的數據質量問題。
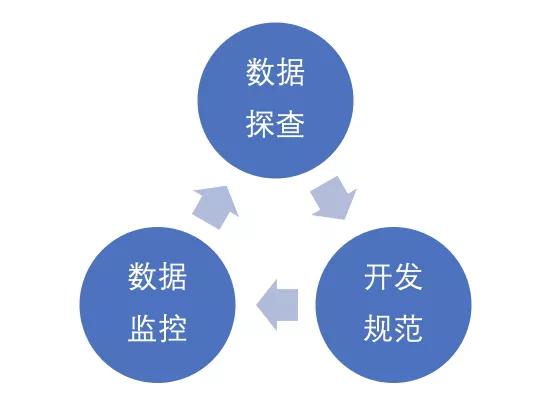
圖3 數據質量解決方法
如圖3所示,我認為有三種方法可以在一定程度上解決數據質量的問題。
- 數據探查
- 發現完整性、一致性、有效性、準確性、關聯性等問題
- 解決的數據接入和數據產出階段的問題
- 開發規范
- 發現數據及時性、數據一致性、數據準確性等問題
- 解決數據產出階段的問題
- 數據監控
- 避免一致性、準確性等問題
- 解決數據生產階段的問題
1 數據探查
數據探查的定義一般為:數據探查是探索源數據的過程,用來理解數據結構、數據內容、數據關系以及為數據工程識別可能存在的問題。
數據探查不止用在數據質量領域,數倉開發、數據遷移等都需要對源數據進行數據探查。數據倉庫的所有數據基礎都是源數據(ODS),在開發數倉之前,需要對源數據進行探查,才能保證產出的數據倉庫的準確性。
題庫業務的數據缺少打點,數據建設主要基于業務架構的一些中間表和結果表,在開發前期,沒有意識到數據探查的重要性,導致數據的準確性有嚴重問題,數據研發出現了大量的返工現象。
dataworks提供了數據探查的功能,可以統計基本信息、數據分布、topN、直方圖等。但我試了幾次一直是探查中,易用性還不是太好。
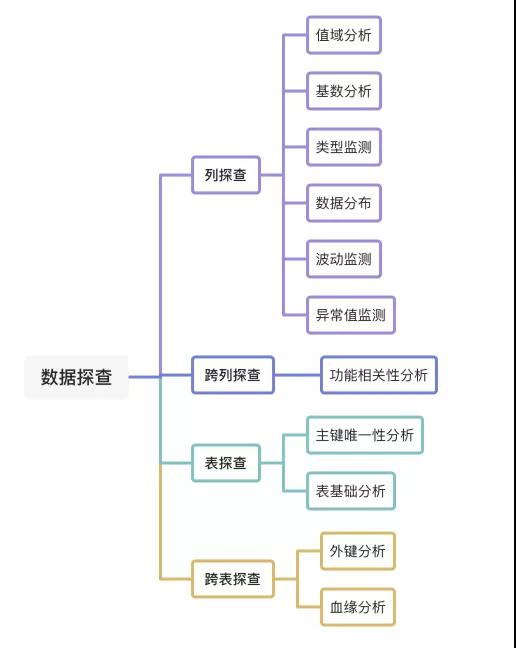
圖4 數據探查基本方法
上圖是數據探查的一些基本功能。
本部分介紹數據探查的一些常見方法,不成體系,只是開發過程中遇到的問題,供參考。
表探查
1)數據總量探查
數據總量探索是對ods的總體數據有初步認知,可以通過數據地圖的分區信息確認,也可以通過寫sql計算。
數據總量探查時要探查每日增量數據總量、全量數據總量(如有需要)。
一般情況下,數據總量探查結果要與業務方或者上游數據提供方確認是否符合預期。
2)數據產出時間和生命周期探查
在做數據探查時,需要探查數據產出時間和生命周期,對后續的任務調度和補數據有一定的幫助。
列探查
1)數據分布探查
數據分布探查是數據探查中最重要的部分,可以探測不同維度下數據的分布情況。一般情況下,有如下寫法。
- SELECT result
- ,COUNT(*)
- FROM xxx.table_name
- WHERE dt = 'xxxxx'
- GROUP BY result ;
2)枚舉值探查
枚舉值探查是上面數據分布探查的一種特例,探查某些維度的枚舉值是否合理。一般情況下sql如下。
- SELECT DISTINCT result
- FROM xxx.table_name
- WHERE dt = 'xxxxx' ;
這種探查,可以探查出很多問題,比如上游生成某枚舉值只有0和1,但探查的時候探查出為空等。
3)唯一值探查
某些情況下,上游生成某些字段唯一(不一定是主鍵),也需要對此類情況探查,不然做join時容易出現數據膨脹問題。探查sql一般如下。
- SELECT COUNT(item_id)
- ,COUNT(DISTINCT item_id)
- FROM xxx.table_name
- WHERE dt = 'xxxxx' ;
4)極值&異常值探查
對于某些數值類的值,必要情況下可以做一下極值探查,比如求最大值、最小值、平均值。這樣可以盡快發現源數據中的臟數據。
對于異常值也要探查一下,比如0、null、空字符串等。
列間探查
1)關聯字段探查
通常情況下,一張表中不同字段直接有關聯關系。比如曝光字段和曝光時長之間有關聯關系,有曝光的一定有曝光時長,或者曝光時長大于0的情況下一定有曝光。
或者uv一定大于pv,這種方法可以對dws表進行驗證。
表間探查
1)join條件探查
此種情況屬于跨表探查。不同的表在做join時,除了探查join條件是否成功,還需要探查join得到的數量是否符合預期。
在題庫業務中,出現過因為系統bug,下游表的join條件中,有3%左右的數據join不上,但因為前期沒有做此方面的數據探查,導致用了很久才發現此問題。
還有一種情況是業務上兩張表必須join上,比如消費表所有的用戶都應該出現在用戶表,或者所有內容都應該出現在內容維表等。
一般sql如下:
- SELECT count(DISTINCT a.itemid)
- FROM xxx.yyy_log a
- LEFT JOIN (
- SELECT itemid
- FROM xxx.zzzz
- WHERE ds = '20210916'
- ) b
- ON a.itemid = b.itemid
- WHERE a.dt = '20210916'
- AND b.itemid IS NULL ;
業務探查
1)過濾條件不對
在某些情況下,需要從海量數據中,通過某些過濾條件撈出所需數據。比如客戶端打點的規范是一致的,不同的端的用戶日志都在一張表中,如果只分析某種數據,需要對數據進行過濾。
此過濾條件一般由業務方同學提供,在數據探查階段要先做條件過濾,與業務方同學溝通過濾之后的數據是否符合預期。
2)業務上數據重復問題
屬于表唯一性探查。此問題與唯一值的現象類似,都是數據有重復。
不同之后在于,某些情況下,雖然數據提供方稱了某些列唯一,但在某些業務場景下,數據就是不唯一的。比如題庫的某業務中,業務方開始說不同線索得到的q_id不一致,然而q_id來自url,在業務上url確實存在重復的情況,所以q_id有重復的情況。
但在另一種數據重復的問題往往不是業務如此,而是系統bug導致的。比如某種業務中,一本書理論上處理完之后不應該再次處理,但系統的bug導致出現一本書被處理多次的情況。
對于第一種情況,我們在建模時要考慮業務復雜性;而第二種情況,我們要做的是找到有效的數據,去掉臟數據。
3)數據漏斗問題
數據鏈路中數據漏斗是很關鍵的數據,在做初步數據探查時,也需要關注數據漏斗。每一層數據丟棄的數量(比例)都要和業務方確認。
比如某一個入庫流的處理數據數量和入庫數量對比,或者入庫數量和入索引數量等,如果比例出現了很大的問題,需要找上游業務方修正。
4)業務上數據分布不合理
“刷子用戶”的發現就是一種常見的數據分布不合理,比如某個user的一天的pv在5000以上,我們大概率懷疑是刷子用戶,要把這些用戶從統計中剔除,并要找到數據上游過濾掉類似用戶。
一般sql如下:
- SELECT userid
- ,count(*) AS cnt
- FROM xxx.yyyy_log
- WHERE dt = '20210913'
- GROUP BY userid
- HAVING cnt > 5000 ;
2 數據開發規范
上面描述了很多數據探查問題,如果認真的做了數據探查,可以避免很多數據質量問題。本部分描述在數據開發環節中開發同學因為經驗等原因導致的數據質量問題。
SQL編寫問題
1)笛卡爾積導致數據膨脹
此問題往往發生在沒有對join條件進行唯一性檢查的情況下。因為右邊數據不唯一,發生笛卡爾積,導致數據膨脹。如果是某些超大表,除了數據結果不對之外,會產生計算和存儲的浪費。
還有一種情況,在單一分區中數據是唯一的,但join時沒有寫分區條件,導致多個分區同時計算,出現數據爆炸。
這個問題很多同學在開發中遇到了多次,一定要注意。
2)join on where順序導致結果錯誤
此問題也是常見問題,因為寫錯了on和where的順序,導致結果不符合預期。錯誤case如下。
- SELECT COUNT(*)
- FROM xxx a
- LEFT JOIN yyy b
- ON a.id = b.item_id
- WHERE a.dt = '${bizdate}'
- AND b.dt = '${bizdate}' ;
在上面的sql中,因為b.dt在where條件中,那么沒有join上的數據會被過濾掉。
3)inner join和outer join用錯問題
此問題偶發,往往是開發同學沒有理解業務或者typo,導致結果不符合預期。
寫完sql一定要檢查,如果有可能請別的同學review sql。
4)時間分區加引號
一般情況下,分區都是string數據類型,但在寫sql時,分區不寫引號也可以查詢出正確的數據,導致有些同學不習慣在分區上加引號。
但某些情況下,如果沒有加引號,查詢的數據是錯誤的。所以一定要在時間分區上加引號。
5)表循環依賴問題
在開發時,偶爾會出現三個表相互依賴的問題,這種情況比較少見,而且在數據開發階段不容易發現,只有再提交任務之后才會發現。
要避免這種情況,需要明確一些開發規范。比如維表和明細表都要從ods表中查得,不能維表和明細表直接互相依賴。對于某些復雜的邏輯,可以通過中間表的形式實現重用。
6)枚舉值問題
在做etl時,需要把某些枚舉值轉化成字符串,比如1轉成是、0轉成否等。
常見的寫法是在sql中寫case when。
但對于某種一直增長的枚舉值,這種方法不合適,否則增加一種編碼就要改一次sql,而且容易出現sql膨脹的問題。
推薦通過與碼表join的方法解決此問題。
性能問題
1)join on where順序的性能問題
上面提到過join的on和where執行順序的問題,這也關系到join的性能問題。因為是先on后where,建議先把數據量縮小再做join,這也可以提升性能。
(1) 如果是對左表(a)字段過濾數據,則可以直接寫在where后面,此時執行的順序是:先對a表的where條件過濾數據然后再join b 表;
(2) 如果是對右表(b)字段過濾數據,則應該寫在on 條件后面或者單獨寫個子查詢嵌套進去,這樣才能實現先過濾b表數據再進行join 操作;
如果直接把b表過濾條件放在where后面,執行順序是:先對a表數據過濾,然后和b表全部數據關聯之后,在reduce 階段才會對b表過濾條件進行過濾數據,此時如果b表數據量很大的話,效率就會很低。因此對于應該在map 階段盡可能對右表進行數據過濾。
我一般對右表做一個子查詢。
2)小維表 map join
在Hive中
若所有表中只有一張小表,那可在最大的表通過Mapper的時候將小表完全放到內存中,Hive可以在map端執行連接過程,稱為map-side join,這是因為Hive可以和內存的小表逐一匹配,從而省略掉常規連接所需的reduce過程。即使對于很小的數據集,這個優化也明顯地要快于常規的連接操作。其不僅減少了reduce過程,而且有時還可以同時減少Map過程的執行步驟。參考文末鏈接一。
在MaxCompute中
mapjoin在Map階段執行表連接,而非等到Reduce階段才執行表連接,可以縮短大量數據傳輸時間,提升系統資源利用率,從而起到優化作業的作用。
在對大表和一個或多個小表執行join操作時,mapjoin會將您指定的小表全部加載到執行join操作的程序的內存中,在Map階段完成表連接從而加快join的執行速度。
文檔中給的例子如下:
- select /*+ mapjoin(a) */
- a.shop_name,
- a.total_price,
- b.total_price
- from sale_detail_sj a join sale_detail b
- on a.total_price < b.total_price or a.total_price + b.total_price < 500;
參考文末鏈接二。
3)超大維表 hash clustering
在互聯網大數據場景中,一致性維表的數據量都比較大,有的甚至到幾億甚至十億的量級,在這個數據量級下做join,會這種任務往往耗時非常長,有些任務甚至需要耗費一天的時間才能產出。
在這種情況下,為了縮短執行時間,通常可以調大join階段的instance數目,增加join階段的內存減少spill等,但是instance的數目不能無限增長,否則會由于shuffle規模太大造成集群壓力過大,另外內存的資源也是有限的,所以調整參數也只是犧牲資源換取時間,治標不治本。
Hash clustering,簡而言之,就是將數據提前進行shuffle和排序,在使用數據的過程中,讀取數據后直接參與計算。這種模式非常適合產出后后續節點多次按照相同key進行join或者聚合的場景。
Hash clustering是內置在MaxCompute中,不用顯示的指定,很方便。
參考文末鏈接三。
4) 數據傾斜問題
Hive/MaxCompute在執行MapReduce任務時經常會碰到數據傾斜的問題,表現為一個或者幾個reduce節點運行很慢,延長了整個任務完成的時間,這是由于某些key的條數比其他key多很多,這些Key所在的reduce節點所處理的數據量比其他節點就大很多,從而導致某幾個節點遲遲運行不完。
常見的情況比如join的分布不均勻,group by的時候不均勻等。
具體的解決方法可以參考文末鏈接四。
3 數據監控
提交數據任務后,如何能正確及時的監控任務也是非常重要的。在數據監控方面,集團提供了很多強大的產品來解決問題,簡單介紹如下。
數據及時性監控(摩薩德)
摩薩德監控是對任務運行狀態的監控,包括任務運行出錯、未按規定時間運行。摩薩德是對任務的監控,因此特別適合監控數據產出的實時性。比如某些表需要在幾點產出,如果沒有產出則報警等。當前摩薩德只能在Dataworks使用。
數據產出監控(DQC)
不同于摩薩德對任務的監控,DQC監控是對表和字段的監控,是任務運行后觸發監控條件從而觸發報警。
數據質量中心(DQC,Data Quality Center)是集團推出的數據質量解決方案,它可以提供整個數據的生命周期內的全鏈路數據質量保障服務。通過DQC,我們能夠在數據生產加工鏈路上監控業務數據的異常性,如有問題第一時間發現,并自動阻斷異常數據對下游的影響,保障數據的準確性。
DQC可以做以下監控
- 數據產出行數波動監控
- 業務主鍵唯一性監控
- 關鍵字段空值監控
- 匯總數據合理性監控
DQC的流程如下:
- 用戶進行規則配置
- 通過定時的調度任務觸發檢查任務執行
- 基于任務配置,獲取樣本數據
- 基于計算返回檢驗結果
- 調度根據檢驗結果,決定是否阻斷干預(強依賴、弱依賴)
不過DQC雖然很強大,但其配置還是很繁瑣的,而且要設置波動規則,需要較長時間觀測,表和字段多的時候配置工作特別大。有團隊研究了Auto-DQC,可以自動化監控DQC配置。
其它數據質量監控平臺
其它值得關注的數據質量監控平臺包括
- Apache Griffin(Ebay開源數據質量監控平臺)
- Deequ(Amazon開源數據質量監控平臺)
- DataMan(美團點評數據質量監控平臺)
三 后記
解決數據質量問題沒有銀彈,數據質量管理不單純是一個概念,也不單純是一項技術、也不單純是一個系統,更不單純是一套管理流程,數據質量管理是一個集方法論、技術、業務和管理為一體的解決方案。本文簡單總結了我們當前遇到的數據質量問題和處理方法,也希望與對數據質量敢興趣的同學多多交流。
文中部分技術和解決已經在uc和夸克業務上踐行,大幅提升了業務的數據質量,拿到較好結果。
鏈接一:https://developer.aliyun.com/article/67300
鏈接二:https://help.aliyun.com/document_detail/73785.html
鏈接三:
https://developer.aliyun.com/article/665154
https://developer.aliyun.com/article/665246
鏈接四:https://developer.aliyun.com/article/60908
【本文為51CTO專欄作者“阿里巴巴官方技術”原創稿件,轉載請聯系原作者】