高可用大數據計算服務如何持續發布和演進

MaxCompute
大數據計算服務 (MaxCompute) 是一種快速、完全托管的 PB/EB 級數據倉庫服務。具備萬臺服務器擴展能力和跨地域容災能力,是阿里巴巴內部核心大數據計算平臺,支撐每日***作業規模。
MaxCompute 是一種統一的大數據計算平臺, MaxCompute 向用戶提供了完善的數據導入方案以及多種經典的分布式計算模型,比如 SQL 、圖計算、流計算和機器學習等,能夠更快速的解決用戶海量數據計算問題,有效降低企業成本,并保障數據安全。
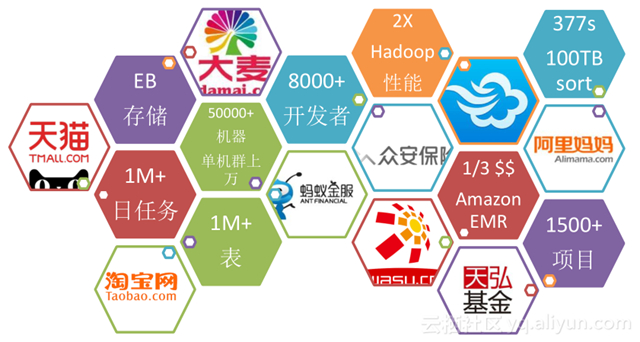
MaxCompute 不只對阿里集團內部用戶開放,也向外部開放。天貓、淘寶、螞蟻金服等都在使用 MaxCompute , MaxCompute 是阿里集團內部最關鍵的大數據平臺,目前, MaxCompute 機器已經有五萬多臺,數據表是***以上,開發者有 8000 多個,性能上是 hadoop2 倍等,從數據上可以感受到 MaxCompute 是名副其實的海量大數據平臺,在業內能處理的數據量以及計算能力也是處于領先地位的。
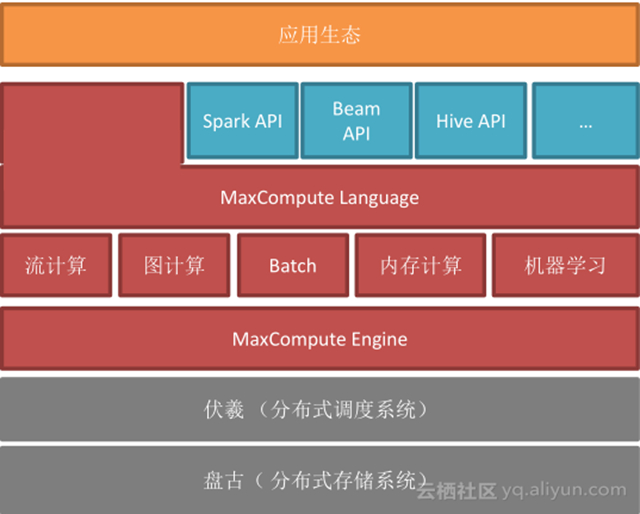
MaxCompute 底層是由阿里自主開發的盤古分布式存儲系統和伏羲分布式調度系統組成,在此基礎上,我們也開發了 MaxCompute 執行引擎, MaxCompute 是統一的大數據計算平臺,既能支持傳統經典的批處理,也支持流計算、圖計算、內存計算以及機器學習等,從這個角度來看,MaxCompute 與 spark 定位非常相似;在此之上, MaxCompute 支持靈活的語言,為了讓用戶能夠無縫接入 MaxCompute ,我們也支持開源系統好多的 API ,包括 spark API 和 Hive API 等。
批處理計算

目前,對于阿里巴巴甚至業界來說, SQL 類型的批處理是最經典最廣泛的應用了, SQL 批處理的流程如下:
用戶提交一條類似 SQL 的腳本到 MaxCompute 后, MaxCompute 會對 SQL 腳本進行編譯并優化,然后用 Runtime 運行。
大數據計算服務
MaxCompute 要做大數據計算的服務,并不像業界開源的 hadoop 、 spark 提供一套解決方案,我們需要提供一個 365 (天) x24 (小時)的高可靠,高可用的共享大數據計算服務。
那么,有什么好處呢?它可以:
– 使用門檻大大降低,用戶不用關心運維升級等
– 共享細粒度使用資源,從而做到低成本,高效率
大數據計算服務強調穩定性,與持續發展之間存在天然的矛盾。在一個穩定運行的大數據計算服務上改進和發布新功能就像“空中換車”,在高速飛行的飛機上替換引擎而同時要保持平穩飛行,其中的挑戰難度可想而知。
持續改進和發布中的挑戰
- MaxCompute 每天都有***作業。如何能夠平穩安全,用戶無感知的發布新的功能?如何保證新版本的穩定性,沒有 bug ,沒有性能的回退?出現問題后如何能夠快速止損等等?
- 面對外部用戶,在測試時如何保證數據安全可靠呢?
針對以上挑戰,我們提出在高可用服務下持續改進和發布了以下技術手段來克服:
– MaxCompute Playback 工具
– MaxCompute Flighting 工具
– MaxCompute 灰度上線,細粒度回滾
編譯器Playback工具
MaxCompute 目前主流的仍然是 SQL 類型應用,其中非常關鍵的模塊就是編譯優化器,我們需要快速提高我們編譯器、優化器的表達能力,以及性能優化水平。
那么,如何能夠保證升級過程中沒有大的 Regression ?
每天有 100 萬 + 個 job ,每天都在變化,如果人工分析的話,每個 script 僅需要 2 分鐘,需要91 人年,這是不現實的,所以,我們開發了編譯器 Playback 工具。
Playback 工具用來解決編譯器和優化器的測試驗證功能,利用大數據計算平臺的運算能力來自我驗證新的編譯優化器。
具體原理如下:
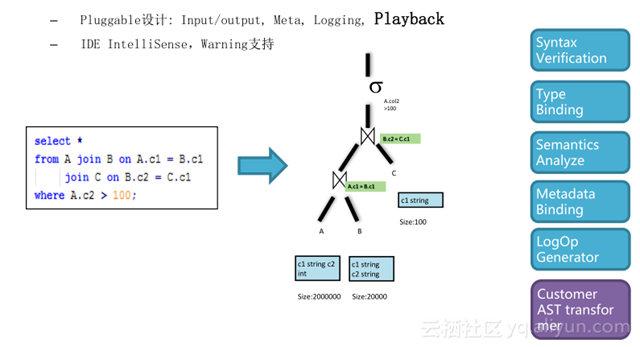
基于 MaxCompute 強大而靈活的編譯擴展能力,編譯器基于 AST 的編譯器模型,使用了經典的 Visitor 模式。 SQL 腳本提交到系統后會將 SQL 腳本轉化成抽象語法樹,正常情況下的語法驗證和分析等實現了標準的 visitor , visitor 對應于 AST 的驗證等擴展性是非常好的,除了標準的 visitor 加入后,還可以加入一些有針對性的檢查驗證抽象語法樹的新 visitor ,將這些 visitor 加到語法樹上,就可以驗證新的編譯器和優化器生成出來的各種各樣的產出是否 OK ,以此來驗證新的編譯器和優化器的能力。
自我驗證
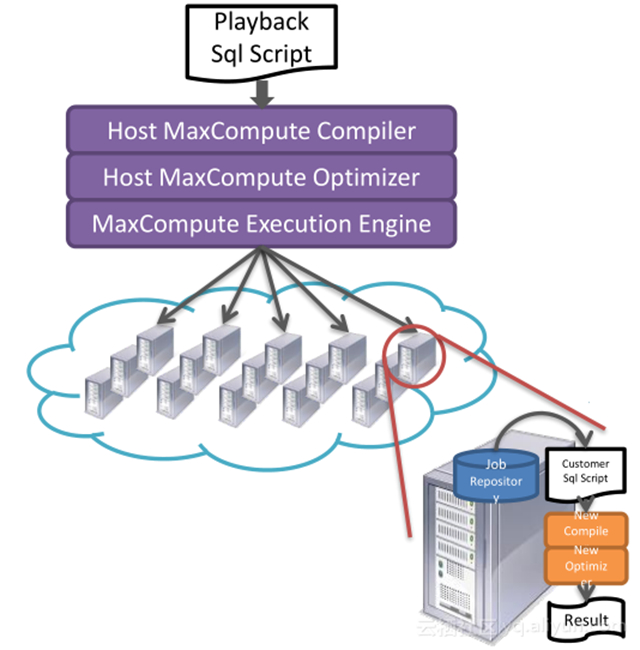
整個驗證過程如下:
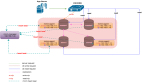
1. 當用戶提交一條 SQL 腳本發給 MaxCompute ,利用 MaxCompute 本身靈活數據處理語言來構造分析任務;
2. 利用 MaxCompute 本身超大規模計算能力來并行分析海量用戶任務,將一段時間用戶作業抽出;
3. 利用 MaxCompute 靈活的 UDF 支持且良好的隔離方案,在 UDF 中拉起待測的編譯器進行編譯,之后再進行詳細的結果分析。
整個過程都在 MaxCompute 完善的安全體系保護下,保障用戶的知識產權。
Playback 工具還有其它很豐富的作用,比如:
- 進行新版本的驗證
- 精確制導找到觸發新的優化規則的 query ,驗證其查詢優化是否符合預期
- 在語義層面對于 query 進行整體數據分析
– 對相應的用戶發 warning 推動用戶下線過時的語法
– 對 query 整體進行分析來確定下一步開發的重點
– 評估新版本在查詢優化在執行計劃上的提高程度
Flighting 工具
除了編譯器和優化器外,另外有一個關鍵模塊就是執行器。那么,如何保證 MaxCompute 運行器是正確執行的?避免在快速迭代中的正確性問題,從而避免重大的事故?同時,如何保證數據的安全性呢?
傳統方式驗證運行器,最經典的是用測試集群來驗證,該方式驗證的缺點如下:
– 調度或者 scalability 等方面的改進往往需要建立一個相同規模的測試集群
- 沒有相應的任務負載,無法構造對應場景
- 數據安全問題,使得我們需要脫敏的方式從生產集群拖數據
– 容易人為疏忽,造成數據泄露風險
– 脫敏數據可能造成用戶程序 crash ,并且往往不能反映用戶運行場景
– 整個測試過程冗長,不能達到測試的目的
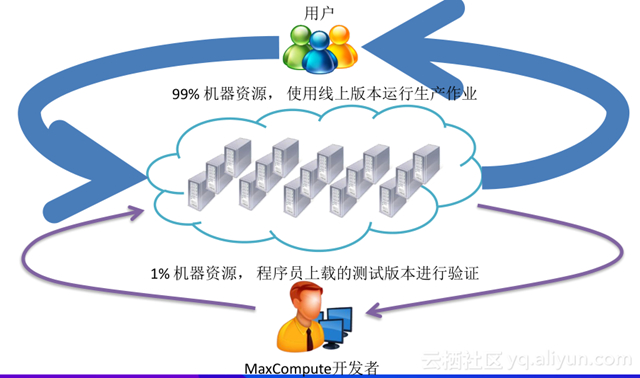
所以我們引入了 flighting 工具來做測試和驗證,將 99% 機器資源使用線上版本運行生產作業,1% 機器資源用來為程序員上載的測試版本進行驗證。
資源隔離
那么,怎么保證測試驗證的作業不去影響線上生產的作業呢?這就需要我們完善資源隔離,具體包括:
- CPU/Memory: 增強 cgroup ,任務優先級
- Disk :統一的存儲管理,存儲的優先級
- Network : Scalable Traffic Control
- Quota 管理
所以我們能夠在保障線上核心業務需求情況下進行 flighting 的測試。
數據安全
從數據安全角度來說,我們的測試不需要人工干預進行數據脫敏; Flighting 的任務的結果不落盤,而是直接對接分析任務產生測試報告:
– 結果正確性: MD5 計算,浮點等不確定性類型的處理
– 執行性能的分析: straggler , data-skew , schedule quality
灰度上線
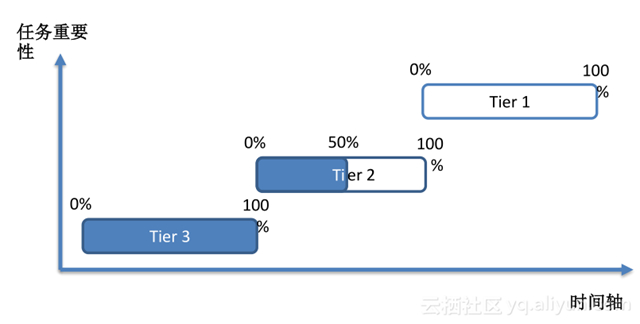
SQL 的關鍵模塊如編譯優化和執行都可以得到有效測試和驗證,接下來就可以上線了,上線時也會有很大風險,因此,我們實行灰度上線。按照任務的重要性進行分級,支持細粒度發布,并且支持瞬時回滾,控制風險到最小。
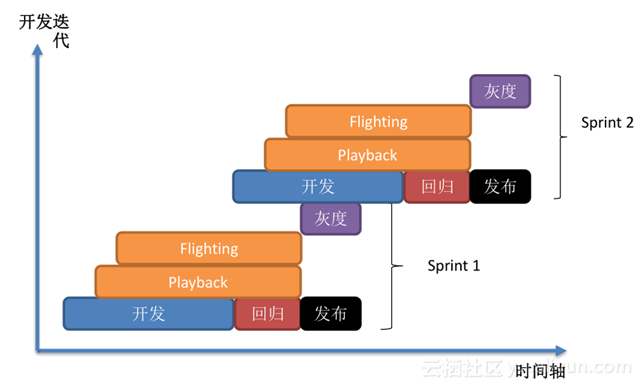
開發新功能后做回歸,回歸后發布,開始時往往有新功能后,就進行驗證,如果新功能是針對編譯器、優化器,就用 playback 驗證,針對 Runtime 就用 flighting 驗證,所有測試驗證結束后,就到灰度發布階段,直到所有任務***發布上線后,我們就認為這一次開發迭代是成功的,以此類推,不停的向前演進,既能保證服務可靠穩定運行的同時,將我們的性能提升,以滿足用戶的各種需求。