麻省理工學院用深度學習教會計算機預測未來
【AI世代編者按】據外媒報道,通過部分基于人腦模型的算法,麻省理工學院的研究員讓計算機可以通過分析照片去預測下一時刻的未來。
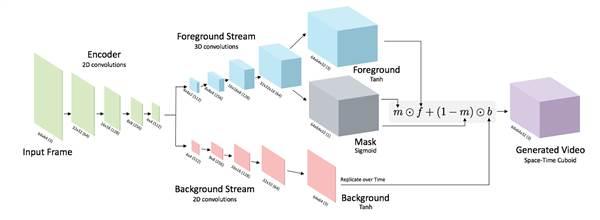
麻省理工學院計算機科學和人工智能實驗室(CSAIL)的一個項目學習了200萬小時的在線視頻,分析了不同畫面之間的承接關系:行人穿過高爾夫球場,海浪沖刷海岸,諸如此類。目前,在觀察一幅靜態畫面時,這一系統能生成約1.5秒鐘長的短視頻,對瞬時的未來做出預測。
CSAIL研究生、論文第一作者卡爾·馮德里克(Carl Vondrick)表示:“這一系統試圖學習,什么樣的視頻是可信的,你可能會看到什么樣的動作。”相關論文將于本月在巴塞羅那的“神經信息處理系統”大會上發表。未來,該團隊希望讓系統基于更復雜的場景生成更長的視頻。
不過馮德里克表示,未來某天,這一系統的能力不僅僅是將照片轉換成計算機生成的GIF動畫。例如,在安全監控畫面中,基于預測正常行為的能力,系統能分析出異常狀況的發生,或是優化無人駕駛汽車的可靠性。他表示,對于無人駕駛汽車,如果系統發現異常狀況,例如道路中出現從未見過的動物類型,那么車輛“可以做出探測,并判斷:‘我從未見過這樣的情況,所以我要停下,讓司機來處理。’”
為了開發這一系統,麻省理工學院的團隊利用了深度學習技術。目前,深度學習正成為人工智能研究的中心。這一方法讓蘋果Siri和亞馬遜Alexa等數字助手理解用戶的意圖,協助了Facebook和谷歌(微博)圖像搜索和面部識別技術的發展。
深度學習基于被稱作神經網絡的數學結構,能從大規模數據集中提取模式。專家表示,通過深度學習技術,計算機可以根據醫學影像做出診斷,監控銀行欺詐,預測用戶訂單模式,以及與人工司機一同駕駛汽車。
舊金山創業公司Skymind CEO克里斯·尼克爾森(Chris Nicholson)表示:“對于許多重要問題,例如圖像識別,深度神經網絡的表現要比人腦更好。如果沒有深度學習,我認為無人駕駛汽車在道路上會非常危險。如果有深度學習,無人駕駛要比人工駕駛更安全。”Skymind開發深度學習軟件,并提供相應的咨詢服務。
神經網絡接受低層次的輸入信息,例如一張圖片中的像素點,或一段音頻中的小片段,并通過一系列虛擬神經層進行處理。通過對輸入信息進行分析,每個數據單元將被分配不同的權重。深度學習中的“深度”意指,這樣的神經層層次很多,通過協作的分析去識別數據中的復雜模式,從而理解從像素到基本圖形再到復雜的圖像,例如道路上的停止標志和紅綠燈。為了訓練神經網絡,研究員需要用大數據集對其進行反復測試,實現權重的自動調整,促使網絡的錯誤率逐步降低。
尼克爾森表示,盡管對神經網絡的研究可以追溯至數十年前,但過去10年業內取得的進展尤為明顯。2006年,知名計算機科學家吉奧夫里·辛頓(Geoffrey Hinton)的一系列論文為深度學習的快速發展奠定了基礎。目前,辛頓同時供職于谷歌和多倫多大學。
2012年,包括辛頓在內的一個團隊首次利用深度學習技術贏得了一項頗具盛名的計算機科學競賽,即ImageNet大規模視覺識別挑戰賽。在圖像分類比賽中,該團隊的軟件以較大的優勢勝過了競爭對手,錯誤率為15.3%,遠低于第二名的26.2%。
今年,谷歌設計的深度學習系統擊敗了全球頂尖的圍棋高手。許多專家此前認為,人工智能成為圍棋大師還要數十年時間。這一名為AlphaGo的系統通過自己與自己的對弈逐漸掌握了圍棋技巧。盡管計算機在很久之前就擊敗了人類的象棋大師,但許多專家認為,讓計算機掌握圍棋的難度更大,因為圍棋存在的可能性要更多。
今年11月,牛津大學的一個小組公布了基于深度學習的唇語閱讀系統,其準確性勝過人類專家。本周,包括谷歌研究員在內的一支團隊在《美國醫學協會期刊》上發表論文稱,深度學習可以識別糖尿病視網膜病變,診斷準確率與受過訓練的眼科醫師相仿。許多糖尿病人都會罹患這樣的疾病,進而引起視力的喪失。
谷歌產品經理、論文第一作者莉莉·彭(Lily Peng)表示:“許多無法得到醫生診斷的患者可以通過這種方式接受診斷,尤其是對醫療條件不佳的人群而言。這一人群中的糖尿病發病率正在上升,而眼科醫師的數量則沒有變化。”
與深度學習取得的許多成功案例類似,對視網膜病變的研究也基于通過大數據的訓練。這一大數據集中包含約12.8萬張已被眼科醫師分類的圖片。深度學習是屬于互聯網時代的一項技術。就在幾年前,這樣大規模的數據集看起來還過于龐大,甚至無法被存入一塊硬盤中。
馮德里克表示:“如果沒有足夠多的數據,那么深度學習就不太有用。如果很難獲得數據,那么深度學習就無法帶來有意義的進展。”
在學會同樣技能的過程中,計算機需要比人類更多的樣本數據。隨著算法越來越復雜,用于學習的數據量越來越多,近期的ImageNet挑戰賽也加入了更復雜的對象識別和場景分析比賽。谷歌開發者利用大量的搜索結果和用戶點擊數據去進行訓練,而開發無人駕駛汽車的公司則通過有人駕駛汽車積累了海量的傳感器數據。
加州灣區自動駕駛汽車創業公司Drive.ai CEO薩米普·坦頓(Sameep Tandon)表示:“獲得類型準確的數據是最關鍵的一點。例如,在加州5號高速公路上勻速行駛100小時無法給你在山景城El Camino的駕駛帶來任何幫助。”
在所有數據收集完畢之后,神經網絡仍需要接受訓練。業內專家表示,神經網絡中的數學計算并不會比高中生水平復雜很多。這通常包括用矩陣乘法給數據點加權,以及通過微積分以更有效的方式去優化權重信息。但這些計算都需要消耗計算資源。
加州大學伯克利分校研究生、深度學習開源工具包Caffe首席開發者埃文·謝爾哈姆(Evan Shelhamer)表示:“如果你擁有大規模數據集,但計算機性能跟不上,那么模型的訓練時間會非常長。”
只有借助現代化計算機,以及連接至互聯網、相互分享工具和數據的研究社區,深度學習才成為可能。不過研究人員表示,深度學習并不是在所有情況下都適用。其局限之一在于,神經網絡對數據的表達很難理解。因此,如果將深度學習算法應用于某些敏感任務,例如汽車駕駛、判斷醫療影像,以及計算信用分,那么監管部門可能會對此持審慎態度。
尼克爾森表示:“目前,深度學習還不具備足夠的解釋能力。系統并不總能告訴你,為何做出某一決策,即使這種決策方式帶來了更好的準確性。”
此外,利用初始的訓練和測試數據,系統可能會存在某些盲點。這將導致在異常情況下無法預期的錯誤。對人類來說幸運的是,當前的深度學習系統還沒有智能到足以自主學會新技能,甚至無法學習相似的技能,除非使用另外的數據再去訓練。
謝爾哈姆表示:“能識別珊瑚的神經網絡并不清楚如何識別道路旁的草地。而擅長圍棋的神經網絡也無法成為國際跳棋的大師。”(編譯/陳樺)