













新加坡政府數據科學部門如何利用大數據協助診斷環線地鐵故障
本文發表于新加坡政府開放數據門戶站的博客,經授權由InfoQ中文站翻譯并分享,本文由InfoQ社區編輯劉志勇翻譯,感謝譯者的辛苦奉獻。
撰文: Daniel Sim | 分析: Lee Shangqian、Daniel Sim、Clarence Ng
編者按:大數據正在滲透各行各業,甚至能跟你考試能力測試、患上某種疾病的機率等非常生活化的場景應用都發生緊密的聯系。今后大數據在我們的生活中就像是水和電一樣,讓社會整個信息質量更好、讓信息利用效率更高效。
世界著名未來學家托夫勒曾說改變這個世界的力量有三種暴力、知識、金錢,而如今我們的世界正在被第四種力量改變,那就是大數據!大數據不管應用在哪個行業它的核心都是通過技術來獲知事情發展的真相,最終利用這個“真相”來更加合理的配置資源。具體來說,要實現大數據的核心價值,還需要前兩個重要的步驟,***步是通過“眾包”的形式收集海量數據,第二步是通過大數據的技術途徑進行“全量數據挖掘”,***利用分析結果進行“資源優化配置”。說白了,大數據最終的落地就是資源優化配置。
本文揭示了新加坡政府是如何利用大數據技術來捕獲引發地鐵被中斷的反常列車,我們得以再一次見識大數據技術的神奇力量。
最近幾個月,新加坡的地鐵環線(MRT Circle Line)遭到了一連串的神秘中斷,對數以千計的乘客造成了很大的混亂和痛苦。
同大多數同事一樣,我每天早晨搭乘環線地鐵到辦公室。因此,在11月5日,當我所在的團隊有調查原因的機會時,我就毫不猶豫地自告奮勇參加了。
根據新加坡地鐵公司(SMRT)和新加坡陸路交通管理局(Land Transport Authority,LTA)的先前調查,我們知道這些事件是由于某種形式的信號干擾造成的,導致了一些列車的信號丟失。信號丟失會觸發那些列車中的制動安全功能,并使它們沿著軌道隨機停止。
但是這起***次發生在八月份的事件——似乎是隨機發生的,使調查小組很難找到確切的原因。
我們獲得了由SMRT編譯的數據集,其中包含以下信息:
- 每個事件的日期和時間
- 事件的位置
- 涉及的列車編號
- 列車的方向
我們開始清理數據,在Jupyter Notebook中進行工作,這是一個流行的編寫和記錄Python代碼的工具。
像往常一樣,***步是導入一些有用的Python庫。
- import math
- import xlrd
- import itertools as it
- import numpy as np
- import pandas as pd
- from datetime import datetime
片段1
然后我們從原始數據中提取有用的部分。
- dfincidents_0 = pd.read_excel('CCL EVAC E-brake occurrences hourly update_mod.xlsx', sheetname='Aug Sep')
- dfincidents_1 = pd.read_excel('CCL EVAC E-brake occurrences hourly update_mod.xlsx', sheetname='Nov')
- # Incident data for Nov had different format
- dfincidents_1['Time'] = dfincidents_1['Time'].str.strip('hrs').str.strip(' ')
- dfincidents_1['Time'] = pd.to_datetime(dfincidents_1['Time'], format='%H%M').dt.time
- dfincidents = pd.concat([dfincidents_0, dfincidents_1])
- # Reset the index because they were concatenated from two data sources
- dfincidents.reset_index(inplace=True, drop=True)
片段2
我們將日期和時間列合并為一個標準列,以便更容易地將數據可視化:
- def datetime_from_date_and_time(row):
- """
- Combines the date column and time column into a single column
- """
- d = row['Date']
- t = row['Time']
- return datetime(
- d.year, d.month, d.day,
- t.hour, t.minute, t.second
- )
- # Add DateTime to the data for easier visualization
- dfincidents['DateTime'] = dfincidents.apply(datetime_from_date_and_time, axis=1)
片段3
這就產生了如下表格:

截圖1:初始處理的輸出
最初的可視化沒有明確的答案
我們在初步探索性的分析中找不到任何明顯的答案,如下圖所示:
1.事件發生在一天之中,整天的事件數量反映了高峰和非高峰旅行時間。
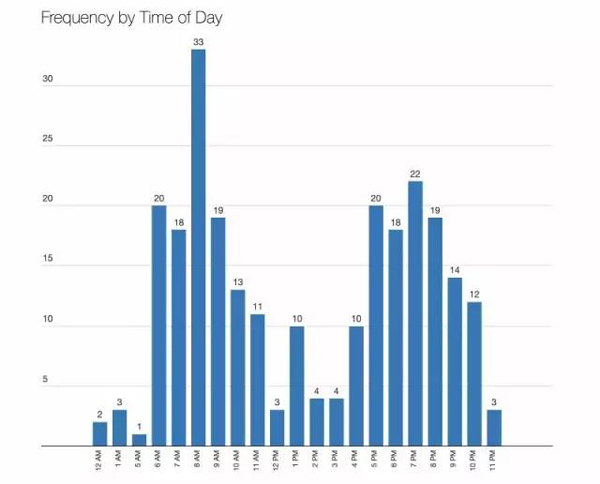
圖1 出現反映高峰和非高峰旅行時間的次數
2.事故發生在環線上的各個地點,西側發生的事件略多一些。
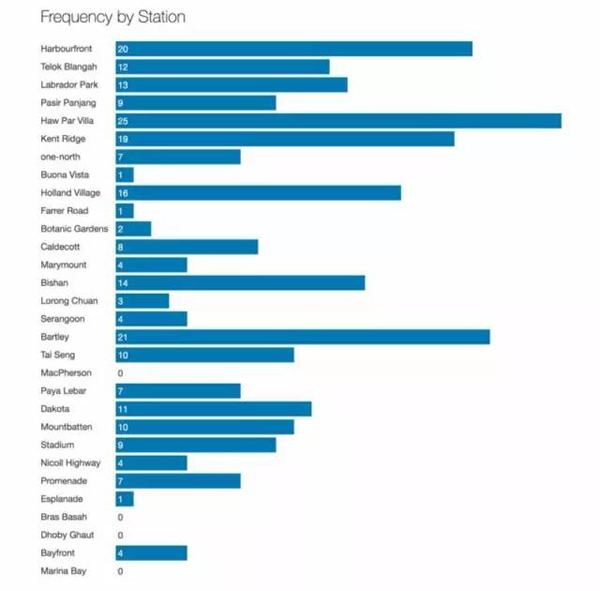
圖2 干擾的原因似乎與位置無關
3.只有一輛或兩輛列車的話,信號干擾并不會產生影響,但在這條環線上有許多列車。“PV”是“客運車輛”(Passenger Vehicle)的縮寫。
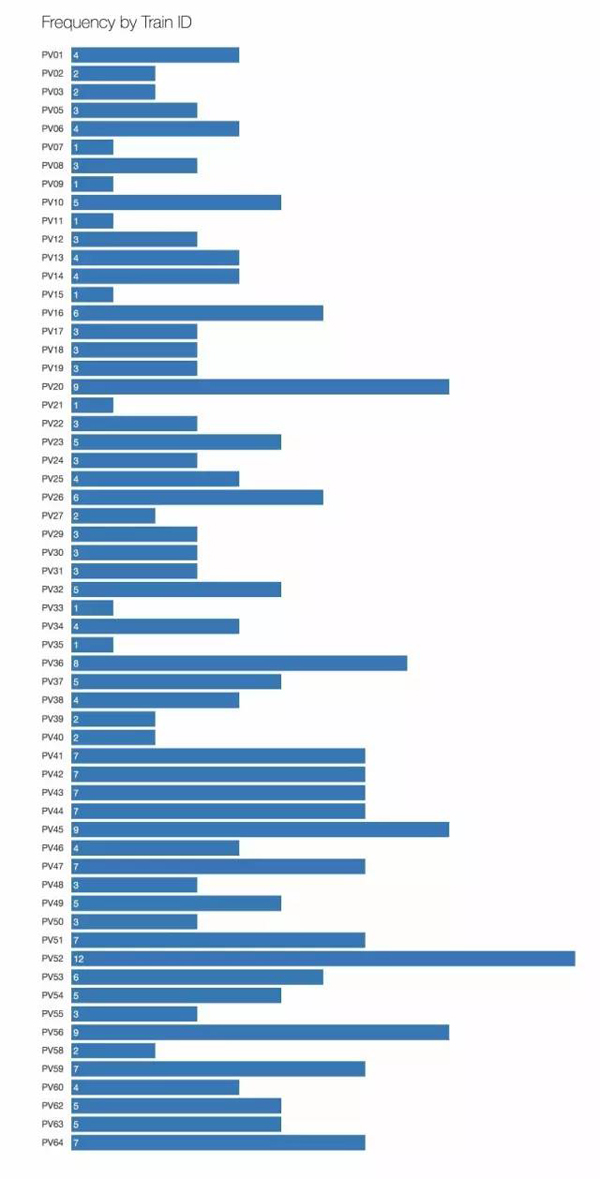
圖3 60輛不同列車受到信號干擾
Marey圖表:顯示時間、位置和方向
我們的下一步是將多維度納入探索性分析。
我們的靈感來自Marey圖表,這是1983年Edward Tufte出版的經典著作《定量信息的視覺顯示》(《The Visual Display of Quantitative Information》)最近,它被Mike Barry和Brian Card應用在波士頓地鐵系統的大規模可視化項目:
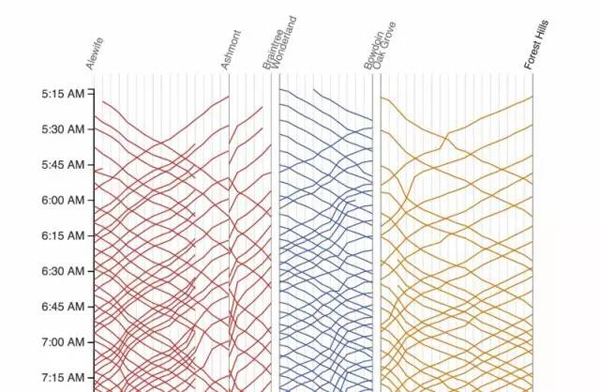
截圖2 摘自http://mbtaviz.github.io/
在該圖表中,垂直軸表示時間——按時間順序從上到下;而水平軸表示沿著列車線路的車站。對角線則表示列車運行。
在我們的Marey圖表中開始繪制軸:
圖4 環線版本的一個空白Marey圖表
在正常情況下,在HarbourFront和Dhoby Ghaut之間運行的列車將在類似與此的線路上移動,每次單程行程只需要一個小時以上:
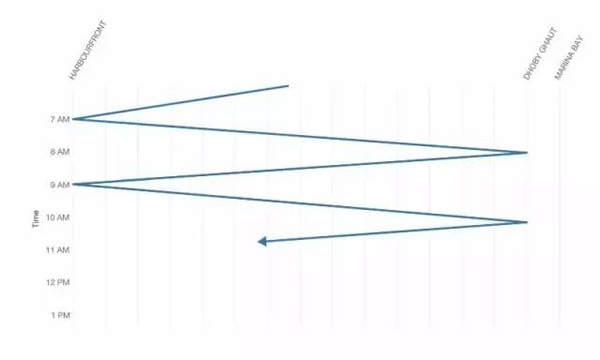
圖5 環線上列車運行的程式化表示
我們的目的是在這個圖表上繪制事件——是點而不是線。
準備可視化數據
首先,我們將站名從三字母代碼轉換為數字:
- Marina Bay到Promenade之前:0到1.5;
- Dhoby Ghaut到HarbourFront:2到29。
如果事故發生在兩個站之間,則將其表示為0.5加上兩個站號中的較小數。例如,如果事件發生在HarbourFront(29)和Telok Blangah(28)之間,則位置將是“28.5”。這樣我們就很容易繪制沿水平軸的點。
- stations=("MRB,BFT,DBG,BBS,EPN,PMN,NCH,SDM,MBT,DKT,PYL,MPS,TSG,BLY,SER,"
- "LRC,BSH,MRM,CDT,BTN,FRR,HLV,BNV,ONH,KRG,HPV,PPJ,LBD,TLB,HBF").split(',')
- def loc_id(station1, station2 = None):
- """
- Translates a 3-letter station code to a number,
- or a pair of 3-letter station codes to a number.
- Single stations are represented as whole numbers.
- Locations between stations are represented with a .5.
- Example:
- loc_id('MRB') # 0 (Marina Bay)
- loc_id('MRB', 'BFT') # 0.5 (Between Marina Bay and Bayfront)
- loc_id('DBG') # 2 (Dhoby Ghaut)
- loc_id('HBF') # 29
- loc_id('HBF', 'TLB') # 28.5 (Between Harbourfront and Telok Blangah)
- loc_id('HBF', 'DBG') # throws and error, because these stations are not adjacent
- """
- if station2 == None or station2 == 'nan' or (type(station2) is float and math.isnan(station2)):
- # Single stations
- return stations.index(station1)
- else: # Pairs of stations -- take the average to get the 0.5
- stn1_index = stations.index(station1)
- stn2_index = stations.index(station2)
- # Handle the branch at Promenade
- if (set(['PMN', 'EPN']) == set([station1, station2])):
- return float(stations.index('EPN')) + 0.5
- elif set(['PMN', 'BFT']) == set([station1, station2]):
- return float(stations.index('BFT')) + 0.5
- else:
- # Require station pairs to be adjacent stations
- assert(math.fabs(stn1_index - stn2_index) == 1)
- return float(stn1_index + stn2_index) / 2
片段 4
然后我們計算位置ID的數字……
- def loc_id_from_stations(row):
- try:
- # This handles entries with both "Station from" and "Station to"
- # and entries with only "Station from"
- return loc_id(row['Station from'], str(row['Station to']))
- except ValueError:
- # Some entries only have "Station to" but no
- # "Station from"
- return loc_id(row['Station to'])
片段 5
并添加到數據集:
- # Select only some columns that we are interested in
- sel_dfincidents = dfincidents[['DateTime', 'PV', 'Bound', 'Station from', 'Station to', 'Event', 'Remarks']]
- # Add the location ID into the dataset
- sel_dfincidents['LocID'] = sel_dfincidents.apply(loc_id_from_stations, axis=1)
片段6
然后我們得到如下表格:
截圖3 添加位置ID后的輸出表
通過數據處理,我們能夠創建所有緊急制動事件的散點圖。這里的每個點代表一個事件。我們還是無法發現任何明顯的事故模式。
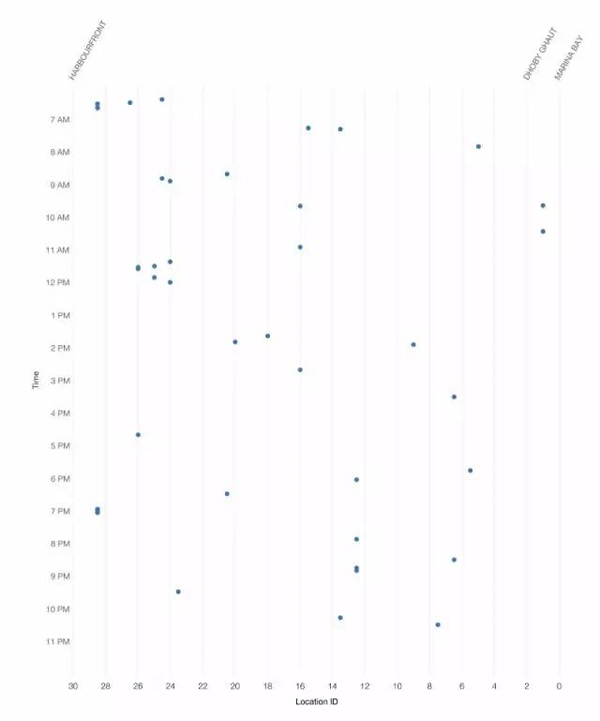
圖6 信號干擾事件表示為散點圖
接下來,我們通過將每個事件表示為指向左側或右側的三角形,而不是點,將列車方向添加到圖表中:
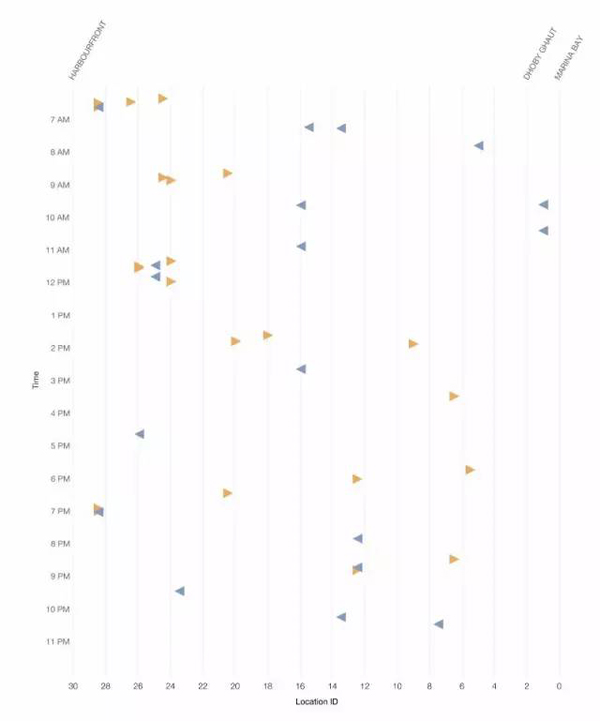
圖7 方向由箭頭和顏色表示。
它看起來相當隨機,但當我們放大到如下的圖表,一個模式似乎似乎浮出了水面:
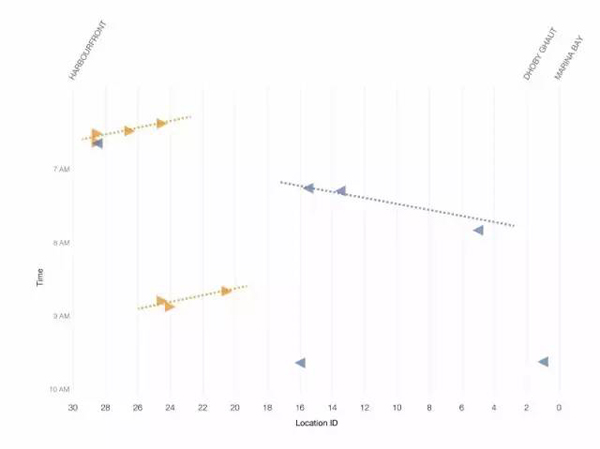
圖8 上午6點到10點之間的事件
如果你仔細閱讀圖表,你會注意到,故障似乎按順序發生。當一趟列車受到干擾時,另一趟在同一方向行駛的列車很快就會受到波及。
信號如何互相干擾?
在這一點上依然不明,一趟列車是罪魁禍首。
我們已經證實的是,似乎有一個隨時間和位置相關的模式:事件一個接一個地發生,與上一個事件的方向相反。似乎有一條“破壞的痕跡”,它會不會是導致數據集中那些事件的誘因?
事實上,連接事件的假想線看上去與截圖2的Marey圖表可疑地類似。干擾的原因會不會是對面軌道的列車?
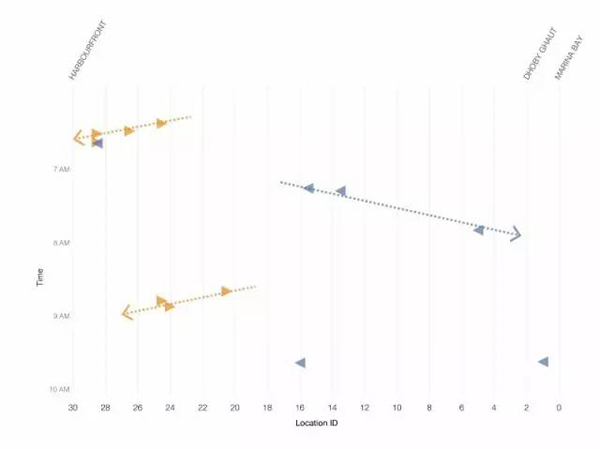
圖9 它會是一趟相反方向行駛的列車嗎?
我們決定檢驗這個“反常列車”的假說。
我們已經知道,沿著環線的車站之間的行駛時間在兩到四分鐘之間。這意味著如果發生4分鐘的間隔,我們可以將所有緊急制動事件分組在一起。
- def same_cascade(i, j):
- """
- Given a pair of incidents (i,j), returns true if:
- t <= d * 4 mins
- where t is the time difference between occurrences
- and d is the distance (measured by difference in location ID).
- Moreover, we consider the track direction, and only consider
- incidents that are "moving backwards".
- """
- # If trains are not travelling in the same direction
- # they cannot be due to the same "backward moving" interference
- # source.
- # (Note: This was the hypothesis when this code was written.
- # It turned out that the rogue train could affect all
- # trains in the vicinity, not just in the opposite track)
- if i["Bound"] != j["Bound"] or \
- i["Bound"] not in ['IT', 'OT']:
- return False
- # time difference in minutes
- time_difference = (i["DateTime"] - j["DateTime"]) / np.timedelta64(1, 'm')
- location_difference = i["LocID"] - j["LocID"]
- if location_difference == 0:
- return False
- ratio = time_difference / location_difference
- if i["Bound"] == 'OT':
- return ratio > 0 and ratio < 4
- elif i["Bound"] == 'IT':
- return ratio < 0 and ratio > -4
片段 7
我們發現了滿足這個條件的所有事件對:
- incidents = sel_dfincidents.to_records()
- # (a, b, c, d, ...) --> ((a,b), (a,c), (a,d), ..., (b,c), (b,d), ..., (c,d), ...)
- incident_pairs = list(it.combinations(incidents, 2))
- related_pairs = [ip for ip in incident_pairs if same_cascade(*ip)]
- related_pairs = [(i[0], j[0]) for i,j in related_pairs]
片段 8
然后,我們使用并查集的數據結構將所有相關的事件對分組成更大的集合。這使我們可以將可能關聯到同一“反常列車”的事件分組。
- def pairs_to_clusters(pairs):
- """
- A quick-and-dirty disjoint-set data structure. But this works fast enough for 200+ records
- Could be better.
- Example input:
- (1,2), (2,3), (4,5)
- Output:
- 1: {1,2,3}
- 2: {1,2,3}
- 3: {1,2,3}
- 4: {4,5}
- 5: {4,5}
- """
- the_clusters = dict()
- for i,j in pairs:
- if i not in the_clusters:
- if j in the_clusters:
- the_clusters[j].add(i)
- the_clusters[i] = the_clusters[j]
- else:
- the_clusters[i] = set(list([i, j]))
- the_clusters[j] = the_clusters[i]
- else:
- if j in the_clusters:
- if the_clusters[i] is not the_clusters[j]: # union the two sets
- for k in the_clusters[j]:
- the_clusters[i].add(k)
- the_clusters[k] = the_clusters[i]
- else: # they are already in the same set
- pass
- else:
- the_clusters[i].add(j)
- the_clusters[j] = the_clusters[i]
- return the_clusters
片段9
然后將我們的算法應用于數據:
- clusters = pairs_to_clusters(related_pairs)
- # Show each set only once
- clusters = [v for k,v in clusters.items() if min(v) == k]
- clusters[0:10]
片段10
這些是我們確定的一些集群:
[{0, 1},
{2, 4},
{5, 6, 7},
{8, 9},
{18, 19, 20},
{21, 22, 24, 26, 27},
{28, 29, 30, 31, 32, 33, 34},
{42, 44, 45},
{47, 48},
{51, 52, 53, 56}]
接下來,我們計算了可以通過我們的聚類算法解釋的事件的百分比。
- # count % of incidents occurring in a cluster
- all_clustered_incidents = set()
- for i,clust in enumerate(clusters):
- all_clustered_incidents |= clust
- (len(all_clustered_incidents),
- len(incidents),
- float(len(all_clustered_incidents)) / len(incidents))
片段11
結果是:
- (189, 259, 0.7297297297297297)
它表達的意思是:在數據集中的259個緊急制動事件中,189個案例(其中73個)可以通過“反常列車”假說來解釋。我們覺得我們真的走對了路。
我們基于聚類結果對事件圖進行了著色。具有相同顏色的三角形在同一個集群中。

圖10 通過我們的算法聚類的事件
有多少反常列車?
如圖5所示,在環線上的每個端到端行程需要大約1小時。我們通過事件圖和與圖5密切匹配的線繪制***線。這強烈暗示只有一個“反常列車”。
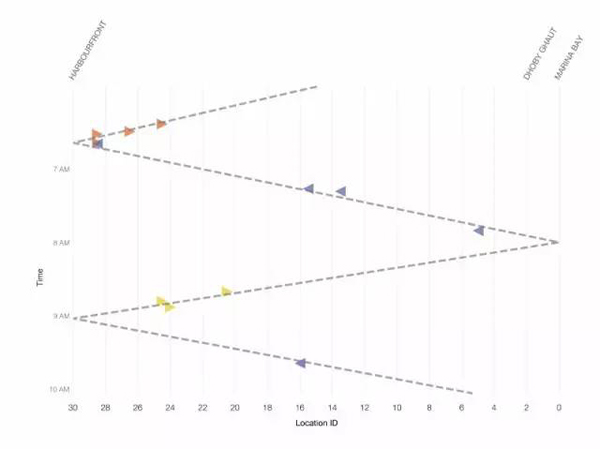
圖11 事件集群的時間強烈暗示干擾能夠關聯到單趟列車
我們還觀察到,不明的“反常列車”本身似乎沒有遇到任何信號問題,因為它沒有出現在我們的散點圖。
我們相信我們有一個很好的例子,決定進一步調查。
捕獲反常列車
日落之后,我們去了Kim Chuan站以確定“反常列車”。我們不能檢查詳細的列車日志,因為SMRT需要更多的時間來提取數據。因此,我們決定用傳統方式通過查看在事件發生時到達和離開每個車站的列車的視頻記錄來識別列車。
上午3點,車隊出現了頭號嫌犯:PV46,一輛自2015年起投入使用的列車。
檢驗假說
11月6日(星期日),LTA和SMRT測試,如果PV46是通過運行列車在非高峰時間問題的來源,那我們就對了——PV46確實導致了附近列車之間的通信丟失,并觸發那些列車上的緊急制動器。在PV46未投入使用的那天之前,并沒有這樣的事件發生。
在11月7日(星期一),我們的團隊處理了PV46的歷史位置數據,并得出結論,從8月到11月的所有事件中,超過95%可以用我們的假說來解釋。其余的事件,可能是由于偶發在正常情況下的信號丟失。
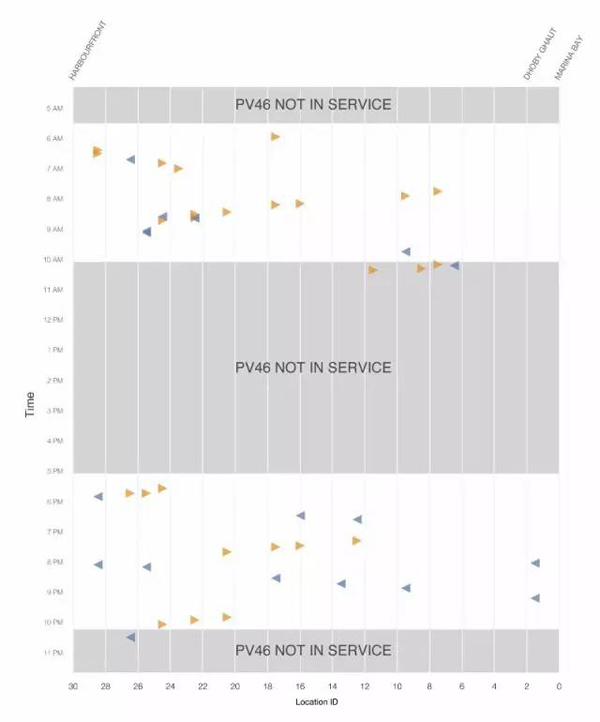
在某些日子,如9月1日,這種模式特別明顯。你可以很容易地看到,當PV46投入運行時 ,在其運行期間或者前后,常常發生發生干擾事件。
LTA和SMRT最終于11月11日發布了一份聯合新聞稿,與公眾分享調查結果。
小結
當我們開始時,我們曾經希望能夠找到跨機構調查組可能感興趣的模式,其中包括LTA、SMRT和DSTA的許多官員。SMRT和LTA提供的整潔的事件日志幫助我們開了一個好頭,因為在導入和分析數據之前需要盡可能少的清理。我們還對LTA和DSTA的有效跟蹤調查表示滿意,因為他們證實了PV46存在硬件問題。
從數據科學的角度來看,我們很幸運,事件發生得如此接近。這使我們能夠在如此短的時間內識別問題和罪魁禍首。如果事件更加孤立,則Z字形模式將不那么明顯,并且它將讓我們耗費更多的時間和數據來解決這個謎。
當然,令人***興的是,現在所有人可以坐環線地鐵再次充滿信心地工作。
注意:本文提到的代碼是在2016年11月5日編寫的——我們處理SMRT數據以確定環線地鐵事件原因的實際日期。我們承認可能存在不足之處。您可以在這里下載我們的Jupyter Notebook的副本(源碼)。















