用Python端對端數據分析識別機器人“僵尸粉”
導讀:不僅微博,在twitter中也存在大批的“僵尸粉”。Twitter中的“僵尸粉”不僅能夠在無人干預下撰寫和和發布推文的程序,并且所產生的推文相當復雜。如何識別這批“僵尸粉”或者說“機器人粉絲”?下面我們將通過Python的Pandas庫、自然語言處理學習NLTK和scikit-learn創建分類器對Twitter機器人進行識別。
在本文中,我想要討論一個互聯網現象:機器人,特別是Twitter機器人。
我之所以一直關注Twitter機器人主要是因為它們有趣又好玩,另外也因為Twitter提供了豐富而全面的API,讓用戶可以訪問到Twitter平臺信息并了解它們是如何運作的。簡而言之,這讓Python強大的數據分析能力得到了充分地展示,但也暴露了它相對薄弱的環節。
對于那些不熟悉Twitter的人, 我們先簡單介紹一下。Twitter是一個社交媒體平臺,在該平臺上用戶可以發布140字以內的惡搞笑話,稱之為“推文”。Twitter根本上區別于其它的社交媒體是因為推文默認是公開的,并且在Twitter上互相關注的人實際上不一定彼此認識。你可以認為Twitter不單單是個人信息流,更像是一個想法交易市場,流通的貨幣則是粉絲和推文轉發。
Twitter另外一個顯著的特點是它自身內容的“嵌入式能力”(見上圖的搞笑例子)。如今,將推文作為新媒體的一部分是稀疏平常的一件事。主要是因為Twitter開放式的API,這些API能讓開發者通過程序來發推文并且將時間軸視圖化。但是,開放式的API讓Twitter在互聯網廣泛傳播,也對一些不受歡迎的用戶開放了門戶,例如:機器人。
Twitter機器人是能夠在無人干預下撰寫和和發布推文的程序,并且所產生的推文相當復雜。其中一些機器人相對不活躍,只是用來增加粉絲和收藏推文的。而另一些會借助復雜的算法來創建具有說服力的推文。所有的Twitter機器人都可能變得讓人討厭,因為它們的出現破壞了Twitter分析的可信度和商業價值,最終甚至會觸及底線。
那么Twitter能對這些機器人做些什么呢?首先,要做的是去識別它們,以下是我的方法。
創建標簽
核心目標是創建一個分類器來識別哪些賬號是屬于Twitter機器人的,我是通過監督學習來實現的。“監督”意味著我們需要已有標注的樣本數據。例如,在最開始的時候,我們需要知道哪些賬號屬于機器人,哪些賬號屬于人類。在過去的研究中,這個費力不討好的任務已經被研究生的使用(和濫用)完成了。例如:Jajodia 等人通過手動檢測賬號,并且運用Twitter版本的圖靈檢測來判斷一個賬號是否屬于機器人,判斷推文是否由機器人發布的。問題是我已經不再是個研究生了并且時間寶貴(開玩笑)。我解決了這個問題多虧我的朋友兼同事Jim Vallandingham 提出的絕妙建議,他向我推薦了fiverr,一個花5美元就能獲取各類奇特服務的網站。
花了5美元,等待24小時之后,我有了5500個新粉絲。因為我知道在機器人關注之前,我的粉絲都有哪些,所以我可以有效地識別哪些是人類,哪些是一夜激增的機器人粉絲。
創建特征
由于Twitter有豐富的REST API(REST指一組架構約束條件和原則,滿足約束條件和原則的應用程序設計——譯者注),創建特征集是幾乎不違反服務條約的行為。我使用Python-twitter模型去查詢兩個終端指標:GET users/lookup(獲取用戶信息)和 GET statuses/user_timeline(獲取用戶狀態、時間軸信息)。獲取用戶信息的終端會返回JSON文本,這些文本中包含了你所希望得到的用戶賬號信息。例如:用戶是否使用了默認的模板配置,關注者/被關注者的數量,發布推文的數量。從獲取的用戶時間軸信息中,我抓取了數據集中每個用戶***的200條推文。
問題是,Twitter官方不允許你直接大量地收集你所想要的數據。Twitter限制了API的調用頻率,這樣意味著你只能在需求范圍內獲取少量的樣本數據進行分析,因此,我使用了以下美妙的方法(blow_chunks)來獲取數據:
#不要超出API的限制

如果查詢的長度大于所允許的***值,那么將查詢分塊。調用生成器.next()方式來抓取***個塊并將此需求發往API。然后暫停獲取數據,兩個數據請求需要間隔16分鐘。如果所有的塊都發出了,那么生成器將會停止工作并且終止循環。
機器人是怪物
通過快速地清理和整理數據,你會很快發現不正常的數據。通常情況下,機器人的關注量是1400,而人類的關注量是500。機器人的粉絲分布具有很大的差異性,而人類的粉絲分布差異性較小。有些人的人氣很高,有一些卻沒那么高,大多數人是介于兩者之間。相反,這些機器人的人氣非常低,平均只有28個粉絲。
將推文變成數據
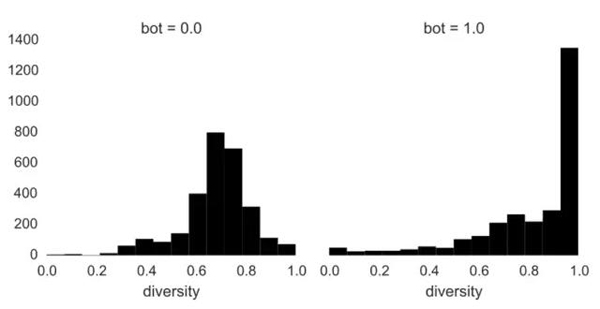
當然,這些機器人在賬號信息層面上看起來很奇怪,但是也有很多人的人氣很低,而且賬號中幾乎空蕩蕩的,只有一張頭像。那么他們發布的推文是怎樣的呢?為了將推文數據加入到分類器中,一個賬號的推文信息需要被匯總成一行數據。有一種摘要度量方式建立在詞匯多樣性之上,就是每個特定詞匯數量占文檔總詞匯數量的比例。詞匯多樣性的范圍是從0到1,其中0代表這個文檔中沒有任何詞匯,1代表該文檔中所有詞都只出現過一次。可以將詞匯多樣性作為詞匯復雜性的度量方法。
我用Pandas 來快速優雅地運用歸納函數,例如詞匯多樣性,對推文進行處理。首先,我把每個用戶的所有推文放進一個文檔,并進行標記,這樣我會得到一個詞匯列表。然后,我再利用NLTK(自然語言處理技術)移除所有標點符合和間隔詞。
通過Pandas在數據集上使用自定義函數是極其方便的。利用groupby,我通過賬戶名將推文分組,并且在這些分組推文中應用詞匯多樣性函數。我鐘愛這個語法的簡潔和靈活,可以將任何類別的數據分組并且適用于自定義的歸納函數。舉個例子,我可以根據地理位置或者性別分類,并且僅僅根據分組的變量,計算所有組的詞匯多樣性。

同樣的,這些機器人看上去很怪異。人類用戶有著一個美得像教科書一般的正態分布,其中大部分的詞匯多樣性比例集中在0.7。而機器人的卻很極端化,詞匯多樣性接近于1。語義差異性為1,這意味著每個詞在文檔中都是獨特的,也就是說機器人要么幾乎不發推文,要么只是發隨機文字。
建模
我利用stickit-learn,Python中最重要的機器學習模塊,進行建模和校驗。我的分析計劃差不多是這樣的,因為我主要關注預測精準度,為什么不試試一些分類方法來看看哪個更好呢?Scikit-learn的一個強項是簡潔,同時在構建模型與管道時與API兼容,這樣易于測試一些模型。
我試了3個分類器,分別是樸素貝葉斯、邏輯回歸和隨機森林分類器。可以看到這三種分類方法的語法是一樣的。在***行中,我擬合分類器,提供從訓練集和標簽為y的數據中得到的特征。然后,簡單地通過將來自測試集的特征傳入模型來預測,并且從分類報告查看精確度。

毫無疑問,隨機森林表現得***,整體精度為0.9,而樸素貝葉斯的是0.84,邏輯回歸的是0.87。令人驚訝的是,利用現有的分類器,我們識別機器人的準確率可以達到90%,但是我們是否可以做得更好?答案是:可以。事實上,利用GridSearchCV可以非常容易地調試分類器。GridSearchCV采用了一種分類方法和一系列的參數設置進行測試。其中,這一系列參數是一個鍵入了該模型配置參數的字典。GridSearchCV***的一點是可以像對待剛才我們看到的分類方法一樣地對待它。也就是說,我們可以使用.fit()和.predict()函數。

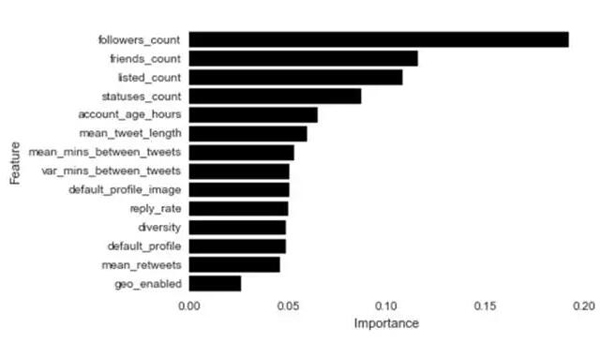
啊哈,更加精確了!簡單的調試步驟產生了一個新格局,預測的準確率提高了2%。為調試過的隨機森林檢查變量重要性策略產生了一些驚喜。朋友數量和粉絲數量是機器人識別中最重要的變量。
但是,我們需要更好的工具來開發迭代模型
Scikit-learn還有很大的提升空間,特別是生成模型診斷和模型比較應用上的功能性。一個說明我的意思的例子是,我想帶你走進另一個世界,那里不用Python,而是R語言。那里也沒有scikit-learn,只有caret(Classification and Regression Training,是為了解決分類和回歸問題的數據訓練而創建的一個綜合工具包——譯者注)。讓我告訴你一些caret的,在scikit-learn里可以被復制的強項。
以下是confusionMatrix函數的輸出結果,與scikit-learn分類報告的概念等價。你會注意到有關comfusionMatrix函數輸出的準確度報告的深度。有混淆矩陣(confusion matrix)和大量將混淆矩陣作為輸入的準確度測量維度。大多數時候,你也許只會使用到一個或者兩個測量維度,但是如果它們都可用是***的,這樣,可以在你所處的環境下使用效果***的,而無需增加額外代碼。

Caret***的一個優勢是提取推理模型診斷的能力,而這在scikit-learn中是看似不可能完成的。以擬合一個回歸方法為例:你自然想看看回歸系數,樣本滿意度,P值和擬合優度。即使你僅僅對預測準確性感興趣,理解模型的原理和知道模型是否滿足假設條件也是有用的。為了在Python中復制這樣的輸出,需要在與statsmodels類似的地方改裝模型,這樣會造成建模過程的浪費和繁瑣。

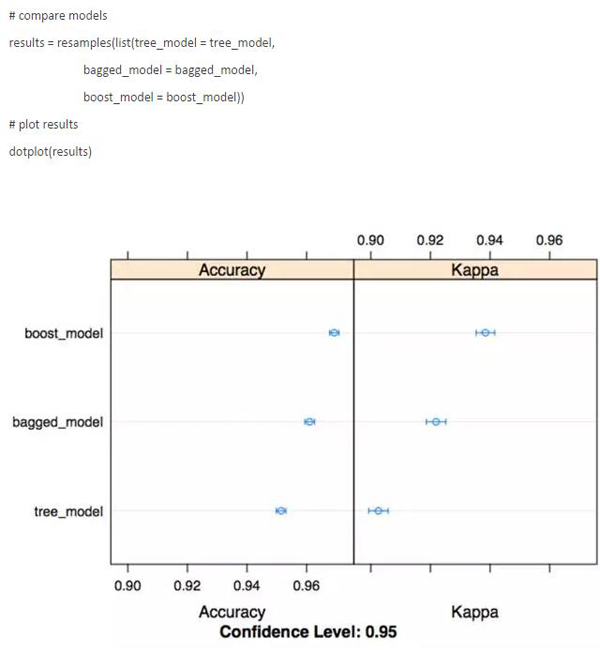
但是,我認為R語言中caret包***的特點是能夠容易地比較不同的模型。使用 resamples 函數,可以很快地生成可視化效果來比較我選擇的指標模型的性能。這種類型的效用函數在建模過程中是超級有用的,也讓你在不想花費大量時間來制作圖的終稿的時候可以就早期的結果進行交流。
對于我而言,這些功能產生了所有的差異,這也是R語言仍然是我建模***語言的主要原因。