斯坦福開源Weld:高效實現數據分析的端到端優化
導讀:Weld 是斯坦福大學 DAWN 實驗室的一個開源項目,在 CIDR 2017 論文中描述了它的初始原型。Weld 用于對結合了數據科學庫和函數的現有工作負載進行優化,而無需用戶修改代碼。我們在 VLDB 2018 論文中提出了 Weld 的自適應優化器,并得出了一些可喜的結果:通過在 Weld IR 上自動應用轉換可以實現工作負載數量級的加速。消融研究表明,循環融合等優化具有非常大的影響。本文主要介紹如何使用 Weld 的自適應優化器進行數據分析的端到端優化。
分析應用程序通常會使用多種軟件庫和函數,比如使用 Pandas 操作表,使用 NumPy 處理數字,使用 TensorFlow 進行機器學習。開發人員通過使用這些庫將來自各個領域的先進算法組合成強大的處理管道。
然而,即使每個庫中的函數都經過精心優化,我們仍然發現它們缺少端到端的優化,在組合使用這些庫時會嚴重影響整體性能。例如,多次調用經過優化的 BLAS 函數(使用了 NumPy)要比使用 C 語言實現單次跨函數優化(如管道化)慢 23 倍。
鑒于這種性能差距,我們最近提出了 Weld,一種用于分析工作負載的通用并行運行時。Weld 旨在實現跨多個庫和函數的端到端優化,而無需改變庫的 API。對于庫開發人員來說,Weld 既可以實現庫函數的自動并行化,也可以實現強大的跨函數優化,例如循環融合(loop fusion)。對于用戶而言,Weld 可以在不修改現有管道代碼的情況下帶來數量級的速度提升,也就是說數據分析師可以繼續使用 Pandas 和 NumPy 等流行庫的 API。
Weld 為開發人員提供了三個主要組件,用于與其他庫集成:
- 庫開發人員使用 Weld 的函數中間表示(Intermediate Representation,IR)來表達他們函數(例如映射操作或聚合)中的計算數據并行結構。
- 然后,使用 Weld 的庫使用延遲評估運行時 API 將 Weld IR 片段提交給系統。Weld 將使用 IR 片段來自動跟蹤和調度對其他函數的調用。
- 當用戶想要計算結果(例如將它寫入磁盤或顯示它)時,Weld 將使用優化編譯器對組合程序的 IR 進行優化和 JIT 編譯,這樣可以生成更快的并行機器代碼,然后基于應用程序內存中的數據執行這些代碼。
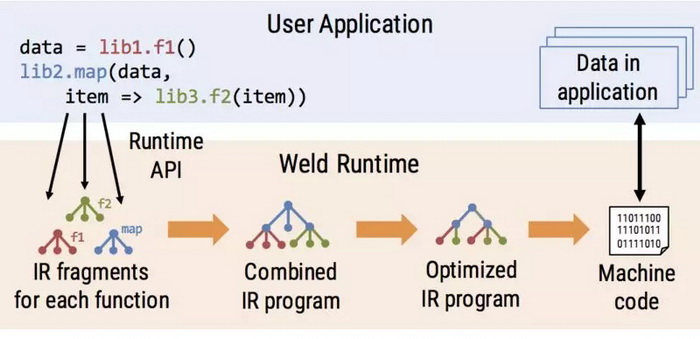
在大多數情況下,用戶可以通過 import 語句切換到啟用了 Weld 的庫。
我們在 CIDR 2017 論文中描述了最初的 Weld 原型。通過在 IR 上應用手動優化,Weld 在合成工作負載上表現出了數量級的速度提升,這些工作負載包含了來自單個庫和多個庫的函數。
VLDB 2018:Weld 的自動優化
這個原型有一個很顯著的限制,IR 的優化是手動進行的,需要預先知道數據的相關屬性,例如聚合基數。簡單地說就是系統缺少自動優化器。為此,我們在 VLDB 2018 上發表的***論文介紹了優化器的設計和實現,這個優化器可自動優化 Weld 程序。
因為 Weld 試圖優化來自不同獨立庫的函數,所以我們發現,與實現傳統的數據庫優化器相比,在設計新的優化器時存在一些獨特的挑戰:
- 計算高度冗余。與人工編寫的 SQL 查詢或程序不同,Weld 程序通常由不同的庫和函數生成。因此,消除由庫組合產生的冗余是至關重要的。例如,可以對中間結果進行管道化或緩存昂貴的公共子表達計算結果,避免多次計算。
- Weld 在進行數據依賴決策時不能依賴預先計算的統計數據。因此,Weld 需要在不依賴目錄或其他輔助信息的情況下優化 ad-hoc 分析。此外,我們發現,在沒有任何統計數據的情況下進行的優化可能會導致速度減慢 3 倍,這說明做出自適應的決策是多么重要。
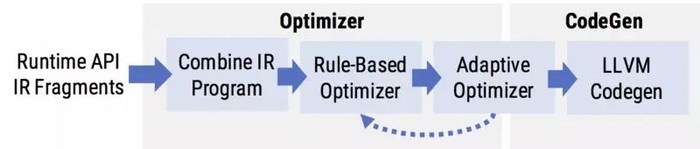
為了應對這些挑戰,我們的優化器采用了雙管齊下的設計,結合了靜態的基于規則的優化(旨在消除冗余,以生成高效的 Weld IR)和自適應優化(在運行時確定是啟用還是禁用某些優化)。
使用新優化器的評估結果是很喜人的:在 10 個真實的工作負載上使用常用庫(如 NumPy 和 Pandas),Weld 可在單個線程上實現高達 20 倍的加速,并通過自動并行化實現進一步的加速。在評估 Weld 時,我們還分析了哪些優化對工作負載樣本產生的影響***,我們希望這對該領域的進一步研究有所幫助。
基于規則的優化:從循環融合到向量化
Weld 的自動優化器首先會應用一組靜態的基于規則的優化。基于規則的優化從 Weld IR 輸入中查找特定模式,并用更有效的模式替換這些模式。Weld 基于規則的優化器在其閉合的 IR 上運行,這意味著每個優化的輸入和輸出都是相同的 IR。這種設計可以允許組合不同的規則并以不同的方式重新運行。
優化器包含了很多用于生成高效代碼的規則,從折疊常量到合并并行循環。其他一些***影響力的基于規則的優化:
- 循環融合,通過合并兩個循環來實現值的管道化,其中第二個循環直接消費***個循環的輸入。管道化改進了 CPU 緩存中的數據位置,因為合并循環每次只從輸入中加載一個元素。
- 向量化,它通過修改 IR 來生成顯式的 SIMD 向量化代碼。CPU 中的 SIMD 指令允許 CPU 在單個周期內完成更多工作,從而提高吞吐量。
- 尺寸推斷,它通過分析 IR 來預先分配內存而不是動態增長緩沖區。這個優化避免了昂貴的庫調用,如 malloc。
Weld 應用了其他額外的優化,在這篇論文中有描述 http://www.vldb.org/pvldb/vol11/p1002-palkar.pdf。
自適應優化:從預測到自適應哈希表
在使用基于規則的優化器轉換 IR 之后,Weld 進行了一系列自適應優化。自適應優化器不是直接替換 IR 中的模式,而是將 Weld 程序變成在運行時動態選擇是否應該應用優化。
其中的一個示例是決定是否要預測一個分支。預測會將分支表達式(即 if 語句)轉換為無條件計算 true 和 false 表達式的代碼,然后根據條件選擇正確的選項。盡管預測代碼會做更多的工作(因為同時計算了兩個表達式),但它也可以使用 SIMD 運算符進行向量化,這與分支代碼不同。請看下面的示例:

使用預測優化是否值得取決于兩個因素:運行 foo 的性能成本(例如 CPU 周期)和條件 x 的選擇性。如果 foo 計算很昂貴并且 x 很少是 true,那么無條件地計算 foo(即使使用了向量指令)可能導致比使用默認分支代碼更差的性能。在其他情況下,使用 SIMD 并行化可以大幅提升速度。這里的數據相關因子就是 x 的選擇性:這個參數在編譯時是未知的。
Weld 的自適應優化器為預測生成代碼,用于對 x 進行采樣,以便在運行時獲得選擇性的近似。然后,根據獲得的測量值,將在運行時使用設置了閾值的成本模型來選擇是否進行預測。下面的代碼展示了自適應預測轉換:

Weld 的自適應優化器還提供了一些其他的轉換:例如,在構建哈希表時,它可以選擇是否使用線程本地或原子全局數據結構,具體取決于鍵的分布和預期的內存占用。在我們的論文中有更多相關內容。
Weld 在數據科學工作負載方面的表現
我們基于 10 個真實的數據科學工作負載對優化器進行評估,包括使用 NumPy 計算用于股票定價的 Black Scholes 方程、使用 Pandas 分析嬰兒名稱、使用 NumPy 和 TensorFlow 來增白圖像并基于它們訓練模型、使用 Pandas 和 NumPy 根據犯罪情況對城市進行評分,等等。結果如下:Weld 可以穩定地提升單個線程的性能,并自動并行化本機單線程庫。從下圖可以看出,Weld 的自動優化器可以有效地最小化因組合單個函數調用帶來的效率損失和生成快速的機器代碼。
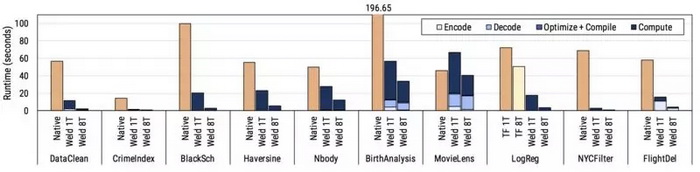
每種優化究竟有多重要?
為了研究每個優化對工作負載有多大的影響,我們還進行了一項消融研究,我們逐個關閉每種優化,并測量對性能的影響。下面的圖表總結了我們分別在一個和八個線程上測試得到的結果。每個框中的數字表示禁用優化后的減速,因此數字越大意味著優化會產生更大的影響。實線下方的數字顯示了帶有合成參數(例如高選擇性與低選擇性)的工作負載,用以說明自適應優化的影響。***,“CLO”列顯示了跨庫優化或跨庫函數優化的影響。
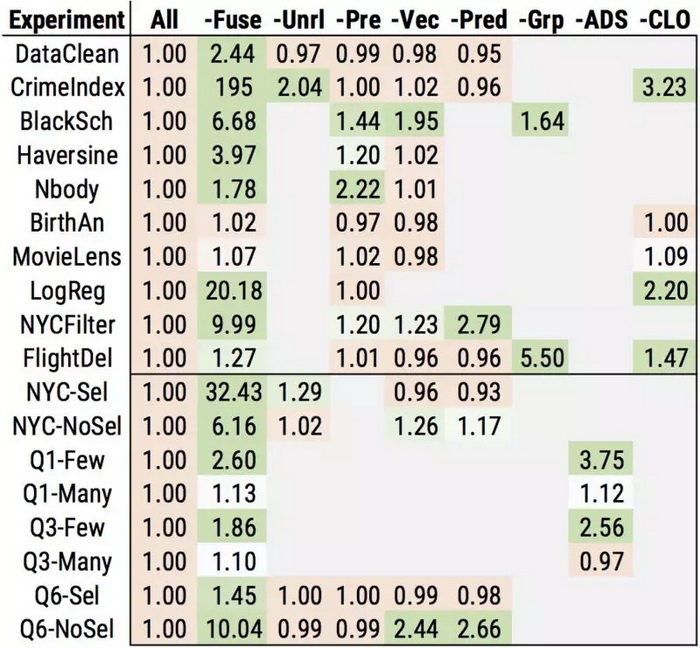
總的
來說,我們發現許多優化至少對一個工作負載具有中等以上的影響。此外,跨庫優化具有相當大的影響,即使在 Weld 對庫應用了優化之后,仍然可以將性能提高 3 倍之多。我們的研究還表明,一些優化非常重要:比如,循環融合和向量化對很多工作負載具有很大的影響。
總結Weld 是一種新的方法,用于對結合了數據科學庫和函數的現有工作負載進行優化,而無需用戶修改代碼。我們的自動優化器得出了一些可喜的結果:我們可以通過在 Weld IR 上自動應用轉換來實現工作負載數量級的加速。我們的消融研究表明,循環融合等優化具有非常大的影響。
Weld 是開源的,由 Stanford DAWN 負責開發,我們在評估中使用的代碼(weld-numpy 和 Grizzly,是 Pandas-on-Weld 的一部分)也是開源的,可在 PyPi 上獲得。這些包可以使用 pip 安裝:

重要鏈接:
- Weld 官網:https://www.weld.rs/
- 評估代碼 weld-numpy:https://www.weld.rs/weldnumpy
- 評估代碼 Grizzly:https://www.weld.rs/grizzly
- CIDR 2017 論文:https://cs.stanford.edu/~matei/papers/2017/cidr_weld.pdf
- VLDB 2018 論文:http://www.vldb.org/pvldb/vol11/p1002-palkar.pdf