“采樣”對于云智慧“端到端”應(yīng)用性能管理的意義和實現(xiàn)
云智慧全棧應(yīng)用性能管理解決方案是一套面向企業(yè)實際業(yè)務(wù)的端到端整體解決方案,其中IT數(shù)據(jù)的端到端采集和展現(xiàn)是云智慧領(lǐng)先于國內(nèi)其他APM產(chǎn)品的重要特性之一,那么我們是如何進行數(shù)據(jù)采樣的,又是如何在“端到端”應(yīng)用性能管理中滿足用戶對業(yè)務(wù)數(shù)據(jù)性能衡量呢?本文將為您一一道來。
首先理解一下我們對“端到端”的定義,“端到端”就是很多年前業(yè)內(nèi)就在提的End2End,現(xiàn)在業(yè)內(nèi)幾個APM廠商在云智慧提出端到端概念之后,也在這么吆喝。端到端有很多種理解,我們的理解是:從終端用戶出發(fā),將從Request到Response整個鏈路中涉及到的所有數(shù)據(jù),有效地串接起來,這樣的數(shù)據(jù)才是真正的端到端,而不是將數(shù)據(jù)按照時間序列進行簡單地羅列展現(xiàn)。
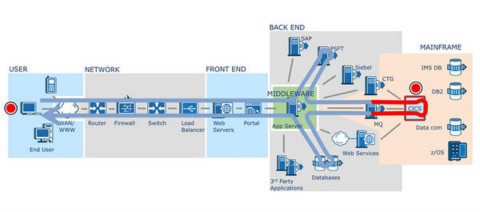
我們從上面的軟硬件模型中可以看到,一個用戶請求從前到后,經(jīng)過了N多的節(jié)點才最終返回數(shù)據(jù)并展現(xiàn)在用戶面前,相信很多有經(jīng)驗的開發(fā)和運維都曾經(jīng)想,怎樣有效地將從用戶請求開始,將請求鏈路中的數(shù)據(jù)都采集到,并且有效地關(guān)聯(lián)起來。
下面就為您剖析一下“采樣”對于“端到端”應(yīng)用性能管理的意義和實現(xiàn)。
為什么要采樣?
采樣這個事說起來是最有意思的,有數(shù)學(xué)基礎(chǔ)或做過計算機研發(fā)的都會非常熟悉。基本上,所有有關(guān)數(shù)據(jù)統(tǒng)計或分析的場景,都離開采樣。
采樣最直接的目的有兩個:減少計算量和降低描述難度。
采樣方法有非常多種,最簡單的,無論哪一種語言,肯定有一個random函數(shù),對其施以隨機種子,然后綜合時間 / CPU即時頻率 / 內(nèi)存地址等等信息,那么出來的即是一個采樣值。像一些profile工具,開始執(zhí)行的開關(guān)就是用這種方式,比如facebook開源的xhprof就非常典型。
采樣還可以人為指定樣本,這也是一種常見的做法。比如,直接指定某一個特定標(biāo)識,如時間,ip,或進程id,等有非常明確特指意義的屬性。如程序猿們在開發(fā)過程中,對一次具體請求的debug過程,非常典型。
在APM廠商中,普遍采用這樣一種采樣算法來計算Apdex。(注:云智慧并未采用這個采樣算法,后文會解釋原因。)先看看什么是Apdex,它是Application Performance Index 應(yīng)用性能指數(shù)的縮寫,這個指數(shù)被其他的APM廠商奉為衡量應(yīng)用性能的核心指標(biāo)。它為用戶對應(yīng)用性能滿意度進行量化,提供了一個測量標(biāo)準(zhǔn)。

以后提到Apdex,大家用這個圖來解釋:Apdex值是0 - 1的區(qū)間值,每個區(qū)間對應(yīng)一個評價:1~0.94是優(yōu)秀,0.94~0.85是良好,0.85~0.70是尚可,0.70~0.50是差評,低于0.50的Apdex值是用戶無法接受的。
這個值,怎么計算呢?
Apdex算法起源于對一個傳統(tǒng)數(shù)據(jù)方法的質(zhì)疑,這個傳統(tǒng)方法就是正態(tài)分布,也叫高斯分布。正態(tài)分布的定義:

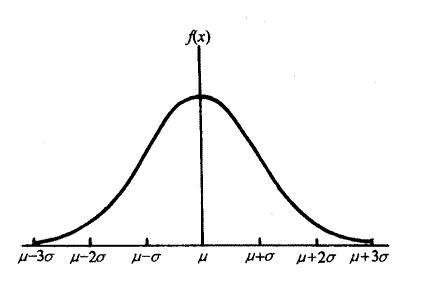
正態(tài)分布應(yīng)用非常廣泛,比如用來對比班級之間的成績,或用來對比某兩組數(shù)據(jù)的屬性差異時,會用它來作為衡量標(biāo)準(zhǔn)。正態(tài)分布非常的標(biāo)準(zhǔn)和簡單,但它有三個明顯的問題:
l 衡量時,使用的是平均值,因此,它假定了 “占主導(dǎo)地位的值是最重要的”。
l 計算時,進一步取向平均的值是不重要的,因為,它假定了那些值 “偏離了規(guī)范”。
l 計算時,它過分夸大了曲線兩端的極限值,因為,它假定了 “分布在兩端的數(shù)據(jù)會被平均,而影響其他值”。
這三個問題是正態(tài)分布在數(shù)據(jù)統(tǒng)計時存在的明顯缺陷。而Apdex的算法針對以上三個問題,作了一個演進。Apdex的計算首先定義一個標(biāo)準(zhǔn)量T,進而將待計算的樣本以T為標(biāo)準(zhǔn)量劃為三個區(qū)間。分別是:
l 小于等于 1T, 為 Satisfactory (滿意)
l 大于1T,小于4T,為 Tolerating ( 容忍 )
l 大于等于4T,為 Frustrated ( 失望 )
此時,Apdex = ( 1 x 滿意 + 0.5 x 容忍 + 0 x 失望 ) / 樣本數(shù)
有沒有注意到一點,失望樣本被忽略了。而滿意樣本,即鐘曲線最左側(cè)的極限值,也未被絕對平均。從計算公式中我們可以看到,Apdex假定你的樣本就是屬于標(biāo)準(zhǔn)正態(tài)分布的,并且減輕曲線兩端對衡量值的影響。
首先聲明標(biāo)量T = 2s
假定樣本為:
l 小于2s的請求次數(shù)為10次,滿意;
l 大于2s,小于8s的請求次數(shù)為20次,容忍;
l 大于等于8s的請求次數(shù)為10次,失望。
那么得到 Apdex = ( 1 x 10 + 0.5 x 20 + 0 x 10 ) / 40 = 0.5
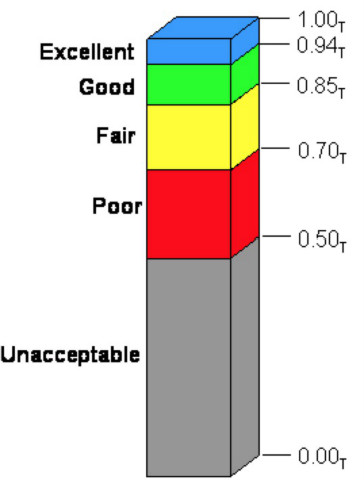
拿這個標(biāo)尺看一下0.5在哪里,已經(jīng)接近“無法接受”了。所以,如果用Apdex來衡量剛才這組樣本,則認為,這個應(yīng)用已經(jīng)要掛了。
這個被廣大APM廠商奉為金典的標(biāo)準(zhǔn),合理嗎?
我再舉一個例子以說明是否合理。假如上面計算的不是響應(yīng)時間,而是一群人的血壓。如果樣本數(shù)據(jù)是一樣的,即:血壓滿意的為10, 血壓可容忍的為20, 血壓超高令人失望的為10。那么得出的這個0.5的結(jié)果,則意味著:這群人已經(jīng)接近了“無法接受”狀態(tài),快掛了,需要集體用藥。
是的,這個值只能說明一個概況,而并不能反映真實的現(xiàn)狀。因為它做到了簡單的整體衡量,而忽略了病患。不能說Apdex不合理,只是在具象的衡量上,標(biāo)準(zhǔn)并不能代表真實狀態(tài)。
接下來看看云智慧APM產(chǎn)品透視寶對數(shù)據(jù)采樣的方案,大家對比一下其優(yōu)劣。
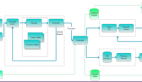
首先可以確定的是,云智慧的數(shù)據(jù)采樣算法并非統(tǒng)計方法。這個方法的設(shè)計思路是:充分覆蓋所有的URI請求的前提下,關(guān)注超出響應(yīng)閾值的請求。 步驟一、全部或部分請求通過hash算法,取得當(dāng)前URI的hash key;
步驟二、判斷請求是否為***訪問,若是否,則執(zhí)行步驟三,若否是,則執(zhí)行步驟四;
步驟三、開始追蹤本次請求,采集本次請求的哈希值,并將此次采集的哈希值記錄在散列圖中;
步驟四、判斷是否允許追蹤,若否,則執(zhí)行步驟五,若是,則執(zhí)行步驟六;
步驟五、不追蹤,并于本次請求結(jié)束后,判斷是否將本次請求采集的哈希值記錄在Trace隊列中;
步驟六、判斷是否已經(jīng)實施過追蹤,若是,則不追蹤,若否,則執(zhí)行步驟七;
步驟七、啟動追蹤,并將被追蹤的次數(shù)記錄于Trace隊列中。
這樣做的優(yōu)勢是什么呢?
首先,我們沒有漏掉任何一個請求,無論快或慢,在出現(xiàn)問題的一剎那,馬上開始關(guān)注這組請求,當(dāng)它再次發(fā)生,則立刻進行全棧的追蹤。
其次,天然地將數(shù)據(jù)請求進行分組,不依據(jù)時間分組,而是依據(jù)請求事務(wù)進行分組;
***,在不影響全棧追蹤的前提下,很好地解決了性能問題。
這個算法默認是關(guān)閉的,在用戶需要的時候,做細微的參數(shù)配置,就可以打開這個算法。也就是說,默認我們連這個算法都沒有開啟。
為什么不采樣呢?
因為我們信奉的金典是,基于業(yè)務(wù)的端到端。只要想做到端到端的業(yè)務(wù)追蹤,任何形式的采樣,都可能直接導(dǎo)致某一個關(guān)鍵請求的缺失。或者換句話說,我們也在采樣,只不過樣本覆蓋率是100%。這其實直接給我們帶來了兩個極大的挑戰(zhàn):
1. 如何保持性能,包括數(shù)據(jù)采集性能,和數(shù)據(jù)處理性能
我們確實為性能付諸了極大的努力,比如數(shù)據(jù)格式,數(shù)據(jù)結(jié)構(gòu),傳輸協(xié)議,數(shù)據(jù)壓縮,等等,自豪地告訴大家,我們基本可以保證對用戶低于5%的性能損耗。如果打開了上面所述的算法開關(guān),則可以將性能損耗有效降低到1%以下。
2. 取得了大量的數(shù)據(jù),如何對這海量數(shù)據(jù)進行分析
請求的事務(wù)數(shù)據(jù):一個應(yīng)用中的事務(wù)基本是不可枚舉的,因為有各種參數(shù)的存在;那么在各種參數(shù)存在的前提上,怎么對響應(yīng)時間進行分析?這方面各廠商的做法是對這段時間內(nèi)請求時間最慢的事務(wù)進行排序,列出***0,這是相當(dāng)不負責(zé)任的做法。
為什么不負責(zé)任,客戶的原話是這樣的:我知道這就是我的***0,然后呢?天天說這個***0,周周說,月月說,這并不能反映我的應(yīng)用健康狀態(tài)。我們需要關(guān)注的是,某段時間內(nèi),請求次數(shù)又多,響應(yīng)時間又相對較慢的這些事務(wù)。
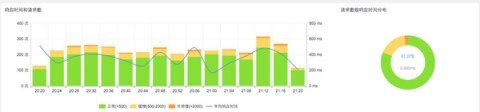
于是我們提出了三個維度的交叉:單位時間,請求次數(shù),響應(yīng)時間。首先構(gòu)思這樣一幅矩陣圖,X軸是時間,左Y軸是請求次數(shù),右Y軸是平均響應(yīng)時間。這些事務(wù)以向量散落在這個象限內(nèi),那么我們可以得出,距離XY的左原點,距離最遠的,即是我們所關(guān)注的。
演化之后,我們得到了這個柱狀的散點圖。