Meta-Think ≠ 記套路,多智能體強化學習解鎖大模型元思考泛化
本文第一作者為上海交通大學計算機科學四年級博士生萬梓煜,主要研究方向為強化學習、基礎模型的復雜推理,通訊作者為上海交通大學人工智能學院溫穎副教授和上海人工智能實驗室胡舒悅老師。團隊其他成員包括來自英屬哥倫比亞大學的共同第一作者李云想、Mark Schmidt 教授,倫敦大學學院的宋研、楊林易和汪軍教授,上海交通大學的溫瀟雨,王翰竟和張偉楠教授。
引言
最近,關于大模型推理的測試時間擴展(Test time scaling law )的探索不斷涌現出新的范式,包括① 結構化搜索結(如 MCTS),② 過程獎勵模型(Process Reward Model )+ PPO,③ 可驗證獎勵 (Verifiable Reward)+ GRPO(DeepSeek?R1)。然而,大模型何時產生 “頓悟(Aha?Moment)” 的機理仍未明晰。近期多項研究提出推理模式(reasoning pattern)對于推理能力的重要作用。類似的,本研究認為
大模型復雜推理的能力強弱本質在于元思維能力的強弱。
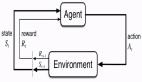
所謂 “元思維” (meta-thinking),即監控、評估和控制自身的推理過程,以實現更具適應性和有效性的問題解決,是智能體完成長時間復雜任務的必要手段。大語言模型(LLM)雖展現出強大推理能力,但如何實現類似人類更深層次、更有條理的 "元思維" 仍是關鍵挑戰。

上圖通過兩臺機器人求三角形高線的截距的解決樣例,直觀展示了元思維與推理的分工:推理機器人執行計算,元思維機器人則在關鍵節點介入進行規劃、拆解或糾錯。基于這個動機,本研究提出從多智能體的角度建模并解決這個問題并引入強化元思維智能體(Reinforced Meta-thinking Agents, 簡稱 ReMA)框架,利用多智能體間的交互來建模大模型推理時的元思維和推理步驟,并通過強化學習鼓勵整個系統協同思考如何思考,以兼顧探索效率與分布外泛化能力。

- 論文題目:ReMA: Learning to Meta-think for LLMs withMulti-agent Reinforcement Learning
- 論文鏈接:https://arxiv.org/abs/2503.09501
- Github 代碼鏈接: https://github.com/ziyuwan/ReMA-public
當前,提升大模型推理能力的研究主要分為兩種思路:
一是構造式的方法:通過在結構化的元思維模板上采樣與搜索構造數據進行監督微調,但這類方法往往只是讓模型記住了這種回答范式,而沒有利用模型內在的推理能力進行靈活探索以發現模型本身最適合的元思維模式,因此難以泛化到分布外的問題集上;
二是 Deepseek R1 式的單智能體強化學習(SARL)方法:通過引入高質量退火數據獲得具備一定的混合思維能力的基礎模型后,直接使用規則獎勵函數進行強化學習微調,習得混合元思維和詳細推理步驟。但這類方法通常依賴強大的基礎模型,對于能力欠缺的基礎模型來說在過大的動作空間內無法進行高效探索,且不用說可能導致的可讀性差等問題。

圖一:ReMA框架與現有大模型復雜推理訓練框架對比
針對這些挑戰,ReMA 框架采取了一套全新的解決思路,將復雜的推理過程解耦為兩個層級化的智能體:
1. 元思維智能體 (Meta-thinking agent) : 負責產生戰略性的監督和計劃,進行宏觀的思考和指導,并在必要的時刻對當前的推理結果進行反思和修正。
: 負責產生戰略性的監督和計劃,進行宏觀的思考和指導,并在必要的時刻對當前的推理結果進行反思和修正。
2. 推理智能體 (Reasoning agent)  : 負責根據元思維智能體的指導,執行詳細的子任務,如單步推理和具體計算等。
: 負責根據元思維智能體的指導,執行詳細的子任務,如單步推理和具體計算等。
這兩個智能體通過具有一致目標的迭代強化學習過程進行探索和協作學習。這種多智能體系統(MAS)的設計,將單智能體強化學習的探索空間分散到多個智能體中,使得每個智能體都能在訓練中更結構化、更有效地進行探索。ReMA 通過這種方式來平衡了泛化能力和探索效率之間的權衡。
方法
ReMA 的生成建模
本研究首先給出單輪多智能體元思維推理過程(Multi-Agent Meta-thinking reasoning process,MAMRP)的定義。
在單輪交互場景下,當給定一個任務問題時,元思維智能體會對問題進行宏觀分析和必要拆解,產生求解計劃,而推理智能體會根據元思維的逐步指令完成任務內容。具體來說,給定問題,元思維智能體首先給出元思維,接著推理智能體給出問題求解,該過程如下所示:

而在多輪交互場景中,元思維智能體給出的元思維可以以一種更加均勻的方式加入到整個思考過程中,元思維智能體可以顯式地對求解的過程進行計劃、拆解、反思、回溯和修正,其交互歷史會不斷疊加直至結束。類似的,本研究可以給出多輪 MAMRP 的定義,該過程如下所示:

整個系統的求解過程可以用以下有向圖來直觀理解:


圖二:不同算法框架的訓練方式對比
單輪 ReMA 的訓練
單輪場景下,考慮兩個智能體和 ,團隊通過迭代優化的方式最大化兩個智能體各自的獎勵,從而更新智能體們各自的權重:

其中每個智能體的獎勵函數分別考慮了總體回答正確性與各自的格式正確性。對于策略梯度的更新算法,本研究使用目前主流的 GRPO 和 REINFORCE++ 來節省顯存和加速訓練。
多輪 ReMA 的訓練
在擴展到多輪場景下時,為了提升計算效率和系統可擴展性,團隊做了如下改變:
(1)首先是通過共享參數的方式降低維護兩份模型參數的部署開銷,同時簡化調度兩份模型參數的依賴關系,提高效率。具體來說,本研究使用不同的角色的系統提示詞來表示不同智能體的策略


,在優化時同時使用兩個智能體的采樣數據進行訓練,更新一份參數。
(2)其次是針對多輪交互場景的強化學習,不同于本研究將每一輪的完整輸出定義為一個動作,通過引入輪次級比率(turn-level ratio)來進行 loss 歸一化與剪切, 具體優化目標如下所示:

其中:

通過這樣的方式,在多輪訓練的過程中,能夠消除 token-level loss 對于長度的 bias,另外通過考慮單輪所有 token 的整體裁切,可以一定程度上穩定訓練過程。
實驗結果
單輪 ReMA 的實驗
首先團隊在單輪設定上對比了一般 CoT 的 Vanila Reasoning Process (VRP),以及其 RL 訓練后的結果 VRP_RL, MRP_RL。團隊在多個數學推理基準(如 MATH, GSM8K, AIME24, AMC23 等)和 LLM-as-a-Judge 基準(如 RewardBench, JudgeBench)上對 ReMA 進行了領域內外泛化的廣泛評估。在數學問題上,團隊使用了 MATH 的訓練集(7.5k)進行訓練,在 LLM-as-a-Judge 任務上則將 RewardBench 按子類比例劃分為了 5k 訓練樣本和 970 個測試樣本進行訓練和領域內測試。

表一:單輪ReMA的實驗對比
結果顯示,在多種骨干預訓練模型(如 Llama-3-8B-Instruct, Llama-3.1-8B-Instruct, Qwen2.5-7B-Instruct)上,ReMA 在平均性能上一致優于所有基線方法。特別是在分布外數據集上,ReMA 在大多數基準測試中都取得了最佳性能,充分證明了其元思索機制帶來的卓越泛化能力。例如,在使用 Llama3-8B-Instruct 模型時,ReMA 在 AMC23 數據集上的性能提升高達 20%。
消融實驗
為了證明 ReMA 中多智能體系統的引入對于推理能力的訓練有益,團隊在單輪設定下分別對二者的強化學習訓練機制進行了消融實驗。
問題一:元思維是否可以幫助推理智能體進行強化學習訓練?

團隊分別對比了三種強化學習訓練策略,RL from base 采用了基礎模型直接進行 RL 訓練;RL from SFT 在 RL 訓練開始前先用 GPT-4o 的專家數據進行 SFT 作為初始化;RL under Meta-thinking 則在 RL 訓練時使用從 GPT-4o 生成的元思維數據 SFT 過后的元思維智能體提供高層指導。
圖三展示了訓練過程中三種不同難度的測試集上的準確率變化趨勢,實驗結果證明了元思維對于推理模型的強化學習具有促進作用,尤其是在更困難的任務上具有更好的泛化性。
問題二:LLM 是否能夠通過強化學習演化出多樣的元思維?

圖四:不同規模的元思維智能體的強化學習訓練演化過程
接著團隊探索了不同規模的元思維智能體的強化學習訓練演化過程,團隊設計了一個可解釋性動作集合。通過讓模型輸出 JSON 格式的動作(先確定動作類型(DECOMPOSE,REWRITE,EMPTY),再輸出相應的內容),以實現對模型輸出動作類型的監控。圖四展示了三種動作類型對應的問題難度在訓練中的變化,實驗發現,在小模型上進行訓練時(Llama3.2-1B-Instruct),元思維策略會快速收斂到輸出簡單策略,即 “什么都不做”;而稍大一些的模型(如 Llama3.1-8B-Instruct)則能夠學會根據問題難度自適應的選擇不同的元思維動作。這個結果也意味著,現在越來越受到關注的自主快慢思考選擇的問題,一定程度上可以被 ReMA 有效解決。
多輪 ReMA 的實驗

圖五:多輪ReMA的實驗結果
最后,團隊擴展到多輪設定下進行了實驗。首先,由于大多數語言模型本身不具備將問題拆解成多輪對話來完成的能力,團隊先從 LIMO 數據集中轉換了 800 條多輪 MAMRP 的樣本作為冷啟動數據,接著使用 SFT 后的權重進行強化學習訓練。圖五左側展示了在 MATH level 3-5 (8.5k)數據集上的訓練曲線和在七個測試集上的平均準確率。團隊發現了以下結論:
- 1. 多輪 ReMA 訓練在訓練集上可以進一步提升,但是在測試集上的提升不明顯。
- 2. 訓練具有不穩定性,并且對超參數很敏感,不同的采樣設定(單輪最大 token 數和最大對話輪數)間會有不同的訓練趨勢。
圖五右側展示了前文中提出的兩個改進(共享參數更新和輪次級比率)對于多輪訓練的影響,團隊采樣了一個包含所有問題類型的小數據集以觀察算法在其上的收斂速度和樣本效率。不同采樣設定下的實驗結果均表明該方案能夠有效提升樣本效率。
總結
總的來說,團隊嘗試了一種新的復雜推理范式,即使用兩個層次化的智能體來顯式區分推理過程中的元思維,并通過強化學習促使他們協作完成復雜推理任務。團隊在單輪與多輪的實驗上取得了一定的效果,但是在多輪訓練的中還需要進一步解決訓練崩潰的問題。這表明目前基于 Deterministic MDP 的訓練流程也許并不適用于 Stochastic/Non-stationary MDP,對于這類問題的數據、模型方面還需要有更多的探索。