性能提升84%-166%!L-Zero僅靠強化學習解鎖大模型探索世界的能力 | 已開源
大模型可以不再依賴人類調教,真正“自學成才”啦?
新研究僅通過RLVR(可驗證獎勵的強化學習),成功讓模型自主進化出通用的探索、驗證與記憶能力,讓模型學會“自學”!

當前主流的LLM Agent依然高度依賴于提示詞工程、復雜的系統編排、甚至靜態規則表,這使得它們在面對復雜任務時難以實現真正的智能行為演化。
而來自招商局獅子山人工智能實驗室的研究團隊認為,RLVR范式是智能體(Agent)通往更高通用性和自主性的重要突破口。
于是,他們從兩個關鍵層面出發構建了端到端Agent訓練pipeline——L0系統:
- 智能體架構層面提出了結構化智能體框架——NB-Agent,在經典”代碼即行動”(Code-as-Action)架構基礎上進行擴展,使智能體能夠操作記憶/上下文,從而獲得類人類的記憶存儲、信息總結與自我反思能力。
- 學習范式層面探索了一個核心問題:是否可以僅通過RLVR范式,引導智能體從零開始,學會如何規劃、搜索、驗證與記憶,最終解決復雜的多輪推理任務?
L0系統的框架、模型及訓練集已全部開源,詳細可見文末鏈接。
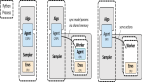
結構化智能體框架:Notebook Agent(NB-Agent)

△NB-Agent的“Think-Code-Observe”循環
受到“代碼即行動”的啟發,NB-Agent選擇使用代碼作為通用的動作空間,并且遵循“讀取-求值-輸出”循環(Read-Eval-Print-Loop,REPL)的方式來和Jupyter Kernel交互。
每一步都是“Think-Code-Observe”:
- Think:模型生成推理邏輯;
- Code:將推理轉化為Python代碼;
- Observe:執行代碼并觀察輸出結果,反饋進入下一輪思考。
在這個過程中,長文本處理是智能體驅動模型(Agentic model)面臨的核心挑戰。
為此,研究團隊提出一個創新方案:將模型的上下文窗口(context)與一個Python運行時的變量進行雙向綁定。
這賦予了智能體主動管理自身記憶的能力,不再被動受限于上下文長度。
具體來說,研究團隊提供了一個Notepad Python類作為結構化的外部記憶模塊。智能體可以通過代碼指令,將關鍵信息、推理步驟或中間結果寫入Notepad。
這些信息會持久存在,并映射到上下文中一個穩定區域,確保在長程任務中不被遺忘。
同時,REPL的交互模式,使智能體能像程序員一樣,將復雜信息存入變量、隨時取用,從而徹底突破上下文的枷鎖。
訓練流程:端到端強化學習

△L0的multi-turn訓練過程
L0采用端到端強化學習進行智能體訓練:
- 重新定義動作粒度一個動作不再是一個token,而是一個完整的“思考+代碼段”;
- 提出Agentic Policy Gradient算法適應序列級動作定義,將策略梯度從單token級擴展到完整動作序列級;
- 構建多維度自動獎勵函數包括最終答案正確性、代碼執行情況、輸出結構規范性等;
- 分布式訓練架構采用輕量級沙箱隔離(Bubblewrap),支持高并發、低部署門檻的大規模RL訓練。
測試:L0顯著提升了模型在多個基準測試上的性能
在多個經典的開放領域問答數據集對L0系統進行測試,見證了智能體的驚人進化。

以Qwen2.5-7B這個基礎模型為例:
在L0-Scaffold(僅有架構,未經過RL訓練)下,它就像一個剛拿到Notebook的新手,在HotpotQA上得分22%。
經過L0-RL(強化學習訓練)后,它學會了如何高效搜索、驗證信息、剔除冗余步驟,最終在同一任務上得分飆升至41%(提升84%)。
在SimpleQA數據集上,L0-RL帶來的提升更加顯著:EM(精確匹配)得分從30%暴漲到80%(提升166%)。

L0在與其他工作的比較中也獲得了具有競爭力的性能,在平均表現上明顯優于Search-R1和ZeroSearch。
這表明L0框架為強化學習提供了更豐富和更具表現力的環境:其他方法訓練智能體學習何時調用單個工具(例如搜索引擎),而L0框架訓練智能體成為一個程序化的問題解決者,學習如何在結構化環境中組合動作、管理狀態和進行推理。
這意味著什么?
在真實搜索之外,模型自己“學會”的搜索、規劃和記憶行為,比直接調用API的規則式Agent更穩定、更泛化、也更強大!
它不再是生硬地調用工具,而是真正理解了怎么利用代碼和這個世界交互,展現了通往更高級通用智能的清晰路徑。
論文:https://github.com/cmriat/l0/tree/main/papers/l0.pdf
NB-Agent框架、訓練pipeline和所有訓練recipe:https://github.com/cmriat/l0
模型checkpoint:https://huggingface.co/cmriat/models
20K訓練數據集:https://huggingface.co/cmriat/datasets
用checkpoint執行深度搜索任務的示例:https://github.com/cmriat/l0/blob/main/examples/nb_agent/deep_searcher_case.md