ICML Oral | 首個「萬億級時間點」預(yù)訓(xùn)練,清華發(fā)布生成式時序大模型日晷
最近,清華大學(xué)大數(shù)據(jù)系統(tǒng)軟件國家工程研究中心的?項時序?模型?作被ICML 2025接受為Oral?章。

論文鏈接:https://arxiv.org/pdf/2502.00816
代碼鏈接:https://github.com/thuml/Sundial
開源模型:https://huggingface.co/thuml/sundial-base-128m
在論文剛發(fā)布時,這項工作就引起了學(xué)界和業(yè)界關(guān)注。

在HuggingFace發(fā)布一周后,日晷在時序預(yù)測板塊的Trending排名第四,下載量達(dá) 6k。

HuggingFace 時序預(yù)測(Time Series Forecasting)板塊
該工作的主要貢獻(xiàn)如下:
- 針對時序預(yù)測的非確定性,提出基于流匹配的預(yù)測損失函數(shù),能根據(jù)歷史序列生成多條預(yù)測軌跡,并緩解時序大模型預(yù)訓(xùn)練時的模式坍塌。
- 構(gòu)建了首個萬億時間點規(guī)模的高質(zhì)量時序數(shù)據(jù)集,發(fā)布了支持零樣本預(yù)測的預(yù)訓(xùn)練模型。
- 相較統(tǒng)計方法和深度模型,無需專門微調(diào)在多項預(yù)測榜單取得效果突破,具備毫秒級推理速度。
時序大模型
時間序列揭示了數(shù)據(jù)隨時間的變化規(guī)律,時序預(yù)測在氣象、金融、物聯(lián)網(wǎng)等多個領(lǐng)域中發(fā)揮著重要作用。
針對時序數(shù)據(jù)的統(tǒng)計學(xué)習(xí),機(jī)器學(xué)習(xí),深度學(xué)習(xí)方法層出不窮,然而,不同方法都有各自的優(yōu)勢區(qū)間:
- 深度學(xué)習(xí)模型雖好,但在數(shù)據(jù)稀缺時容易出現(xiàn)性能劣化;
- 統(tǒng)計學(xué)習(xí)方法雖快,但需逐序列擬合,缺乏泛化性。

訓(xùn)練數(shù)據(jù)與模型效果的規(guī)模曲線同樣適用于時序分析
最近研究旨在構(gòu)建時序大模型:在大規(guī)模時序數(shù)據(jù)上預(yù)訓(xùn)練,在分布外數(shù)據(jù)上預(yù)測(零樣本預(yù)測)。
由于不需要訓(xùn)練,其資源開銷主要集中在推理,速度媲美 ARIMA 等統(tǒng)計方法,并擁有更強(qiáng)的泛化性。
谷歌,亞馬遜,以及 Salesforce 等公司相繼自研時序大模型,用于在特定場景下提供開箱即用預(yù)測能力。
非確定性預(yù)測
目前業(yè)界的深度模型主要支持確定性預(yù)測:給定歷史序列,產(chǎn)生固定的預(yù)測結(jié)果。
然而,時序預(yù)測存在非確定性,對預(yù)測結(jié)果的把握取決于信息的充分程度。
深度學(xué)習(xí)以數(shù)據(jù)驅(qū)動的方式建模時序變化的隨機(jī)過程,實際觀測到的序列也是上述隨機(jī)過程的一次采樣。
因此,時序預(yù)測不光存在信息完備的難題,即使信息充分,未來結(jié)果也存在一定的不確定性。
決策過程往往更需要對預(yù)測結(jié)果的風(fēng)險評估(例如方差,置信度等),因此概率預(yù)測能力至關(guān)重要。
預(yù)訓(xùn)練模式坍塌
概率預(yù)測并非難事
均方損失函數(shù)能建模高斯先驗的預(yù)測分布,尖點損失函數(shù)(Pinball Loss)可實現(xiàn)分位數(shù)預(yù)測。
然而,為時序大模型賦予概率預(yù)測能力充滿挑戰(zhàn):大規(guī)模時序數(shù)據(jù)往往呈現(xiàn)復(fù)雜多峰分布——相似的歷史序列,在不同領(lǐng)域/樣本中可能出現(xiàn)完全不同的未來變化。

時序預(yù)測的非確定性來自時序數(shù)據(jù)的分布異構(gòu)性。時序數(shù)據(jù)還存在其他異構(gòu)性:例如維度異構(gòu),語義異構(gòu)等。目前時序大模型尚處于如何有效處理時序數(shù)據(jù)異構(gòu)性的階段
在大規(guī)模時序數(shù)據(jù)的復(fù)雜異構(gòu)分布上訓(xùn)練,以往模型往往給出「過平滑」的預(yù)測結(jié)果(上圖右)。
雖然從優(yōu)化目標(biāo)來看,該結(jié)果是全局最優(yōu)的,但預(yù)測結(jié)果沒有提供實際有效的信息。
作者團(tuán)隊將該現(xiàn)象稱為時序模型「模式坍塌」,源自使用帶先驗的損失函數(shù),限制了模型的假設(shè)空間 (Hypotheses Space)。
為緩解模式坍塌,Moirai使用混合分布處理模棱兩可的預(yù)測情況。然而,混合分布依然引入了概率先驗,不夠靈活。
亞馬遜Chronos將時間序列離散化,使用交叉熵優(yōu)化學(xué)習(xí)弱先驗的多峰概率分布。
但是,交叉熵?fù)p失依賴離散化,存在精度損失和詞表外泛化(Out-of-Vocabulary)等問題,不夠原生。

日晷相較此前時序大模型的區(qū)別:(1)時序原生性:無需離散化,使用 Transformer 直接編碼連續(xù)時間值,突破語言建模(Language Modeling)(2)分布靈活性:不引入分布先驗,基于生成模型學(xué)習(xí)靈活的數(shù)據(jù)分布,突破參數(shù)先驗(Parametric Densities)
針對原生性和靈活性的矛盾,該工作深入原生連續(xù)編碼和生成式建模,提出首個基于流匹配的生成式時序大模型。
無需離散化,在連續(xù)值序列上進(jìn)行處理和預(yù)測;無需假定預(yù)測分布,釋放模型對大規(guī)模時序數(shù)據(jù)的學(xué)習(xí)能力。
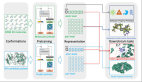
時序Transformer+流匹配生成
日晷模型主體為可擴(kuò)展Transformer,使用重歸一化,分塊嵌入和多分塊預(yù)測等技術(shù)適配時序數(shù)據(jù)特性,并融入了FlashAttention,KV Cache等進(jìn)行效率優(yōu)化。

日晷可視作一種ARMA模型(自回歸和與移動平均):Transformer自回歸地學(xué)習(xí)任意長度的時間序列表征;基于該表征,時間流(TimeFlow)將隨機(jī)噪聲轉(zhuǎn)換為非確定性預(yù)測結(jié)果
基于Transformer提取的上下文表征,研究人員提出時間流預(yù)測損失(TimeFlow Loss),將歷史序列表征作為生成條件引入到流匹配過程中。
流匹配是生成式建模的前沿技術(shù),通過學(xué)習(xí)速度場,將簡單分布變換為任意復(fù)雜分布,從簡單分布中采樣隨機(jī)噪聲,能夠生成服從復(fù)雜分布的樣本。
所提出的損失函數(shù)不引入任何概率先驗,模型將采樣隨機(jī)性引入訓(xùn)練過程,擴(kuò)展了預(yù)測分布的假設(shè)空間,增強(qiáng)了模型的擬合能力,使其能更加靈活地處理時序數(shù)據(jù)的分布異構(gòu)性,
推理時,通過多次從簡單分布中采樣,模型能夠生成多條符合歷史變化的預(yù)測軌跡;基于多條預(yù)測樣本,能夠構(gòu)建預(yù)測序列的分布,從而估計預(yù)測值,方差和置信區(qū)間等。

日晷可多次采樣生成未來可能出現(xiàn)的情況,隱式構(gòu)建預(yù)測值的概率分布,使用者可在此基礎(chǔ)上計算關(guān)心的分布指標(biāo),或者引入反饋信號進(jìn)行調(diào)優(yōu)
萬億時間點預(yù)訓(xùn)練
該工作構(gòu)建了領(lǐng)域最大的時序數(shù)據(jù)集TimeBench,由真實數(shù)據(jù)和合成數(shù)據(jù)構(gòu)成,覆蓋氣象、金融、交通、能源、物聯(lián)網(wǎng)等多個領(lǐng)域,包含小時到日度等多種采樣頻率和預(yù)測時效,總計萬億(10^12)時間點。

TimeBench 由大量真實數(shù)據(jù)和少量合成數(shù)據(jù)組成,覆蓋多種時序預(yù)測的應(yīng)用相關(guān)領(lǐng)域
在萬億數(shù)據(jù)基礎(chǔ)上,模型在擴(kuò)展的數(shù)據(jù)量/參數(shù)規(guī)模中預(yù)訓(xùn)練,驗證了生成式時序大模型的「規(guī)模定律」。

不同參數(shù)規(guī)模的模型訓(xùn)練曲線
預(yù)測榜單效果
日晷在多項榜單中進(jìn)行了測試,涵蓋多種輸入輸出長度,包含點預(yù)測以及概率預(yù)測場景:
- GIFT-Eval 榜單:日晷的零樣本預(yù)測能力超過此前Chronos,Moirai,以及分布內(nèi)訓(xùn)練的深度模型。

GIFT-Eval 為 Salesforce 發(fā)布的預(yù)測榜單,包含24個數(shù)據(jù)集,超過144,000個時間序列和1.77億個數(shù)據(jù)點,跨越7個領(lǐng)域,10種頻率,涵蓋多變量,短期和長期的預(yù)測場景
- FEV 榜單:日晷大幅超過 ARIMA 等統(tǒng)計方法,取得了與 Chronos 相當(dāng)?shù)男Ч瑑H需1/35的推理時間。

GIFT-Eval 為 AutoGluon 發(fā)布的預(yù)測榜單,包含27個數(shù)據(jù)集,指標(biāo)從左到右依次為:概率預(yù)測(WQL),點預(yù)測(MASE)和推理時間(ms)
- Time-Series-Library 榜單:日晷取得了第一的零樣本預(yù)測效果,隨參數(shù)規(guī)模擴(kuò)大,效果持續(xù)提升。

開箱即用模型
目前 HuggingFace 上開源了基礎(chǔ)模型,僅需不到十行代碼,就可調(diào)用模型進(jìn)行零樣本預(yù)測,并提供了均值預(yù)測,分位數(shù)預(yù)測,置信區(qū)間預(yù)測等示例。

模型可在CPU上直接推理,生成多條預(yù)測結(jié)果的時間不到一秒。

總結(jié)與展望
日晷結(jié)合了連續(xù)值編碼、Transformer和生成式預(yù)測目標(biāo),緩解了時序數(shù)據(jù)預(yù)訓(xùn)練的模式坍塌問題。通過萬億規(guī)模預(yù)訓(xùn)練和工程效率優(yōu)化,模型提供了開箱即用預(yù)測能力和毫秒級推理速度。
所提出的生成式預(yù)測范式有望擴(kuò)展時序模型的應(yīng)用前景,使其成為許多行業(yè)的決策工具。
未來,該工作計劃探索在多變量預(yù)測場景下的訓(xùn)練和微調(diào)技術(shù),融入特定場景下的機(jī)理知識和決策反饋,進(jìn)一步釋放時序大模型的泛化性和可控性。