













文生圖10倍速,視頻實時渲染!清華發布LCM:兼容全部SD大模型、LoRA、插件等
Latent Consistency Models(潛一致性模型)是一個以生成速度為主要亮點的圖像生成架構。
和需要多步迭代傳統的擴散模型(如Stable Diffusion)不同,LCM僅用1 - 4步即可達到傳統模型30步左右的效果。
由清華大學交叉信息研究院研究生駱思勉和譚亦欽發明,LCM將文生圖生成速度提升了5-10倍,世界自此邁入實時生成式AI的時代。

LCM-LoRA: https://huggingface.co/papers/2311.05556
項目主頁:https://latent-consistency-models.github.io/
Stable Diffusion殺手:LCM
在LCM出現之前, 不同團隊在各種方向探索了五花八門的SD1.5和SDXL替代方案。這些項目各有特色,但都存在著不兼容LoRA和不完全兼容Stable Diffusion生態的硬傷。按發布時間順序,比較重要的項目有:
模型名稱 | 介紹 | 生成速度 | 訓練難度 | SD生態兼容性 |
DeepFloyd IF | 高質量、可生成文字,但架構復雜 | 更慢 | 更慢 | 不兼容 |
Kandinsky 2.2 | 比SDXL發布更早且質量同樣高;兼容ControlNet | 類似 | 類似 | 不兼容模型和LoRA,兼容ControlNet等部分插件 |
Wuerstchen V2 | 質量和SDXL類似 | 2x - 2.5x | 更容易 | 不兼容 |
SSD-1B | 由Segmind蒸餾自SDXL,質量略微下降 | 1.6x | 更容易 | 部分兼容 |
PixArt-α | 華為和高校合作研發,高質量 | 類似 | SD1.5十分之一 | 兼容ControlNet等部分插件 |
LCM (SDXL, SD1.5) | 訓練自DreamShaper、SDXL,高質量、速度快 | 5x -10x | 更容易 | 部分兼容 |
LCM-LoRA | 體積小易用,插入即加速;犧牲部分質量 | 5x -10x | 更容易 | 兼容全部SD大模型、LoRA、ControlNet,大量插件 |
這時,LCM-LoRA出現了:將SD1.5、SSD1B、SDXL蒸餾為LCM的LoRA,將生成5倍加速生成能力帶到所有SDXL模型上并兼容所有現存的LoRA,同時犧牲了小部分生成質量; 項目迅速獲得了Stable Diffusion生態大量插件、發行版本的支持。
LCM同時也發布了訓練腳本,可以支持訓練自己的LCM大模型(如LCM-SDXL)或LCM-LoRA,做到兼顧生成質量和速度。只要一次訓練,就可以在保持生成質量的前提下提速5倍。
至此,LCM生態體系具備了完整替代SD的雛形。
截止至2023/11/22,已支持LCM的開源項目:
- Stable Diffusion發行版
- WebUI(原生支持LCM-LoRA,LCM插件支持LCM-SDXL)、ComfyUI、Fooocus(LCM-LoRA)、DrawThings
- 小模型
LCM-LoRA兼容其他LoRA,ControlNet
AnimateDiff WebUI插件
計劃中添加支持的項目:
- WebUI主分支持
- 訓練腳本Kohya SS
- LCM-SDXL、LCM-DreamShaper專屬的ControlNet
- LCM-AnimateDiff
隨著生態體系的逐漸發展,LCM有潛力作為新一代圖像生成底層完整替代Stable Diffusion。
未來展望
自Stable Diffusion發布至今,生成成本被緩慢優化,而LCM的出現使得圖像生成成本直接下降了一個數量級。每當革命性的技術出現,都會帶來重塑產業的大量機會。LCM至少能在圖像生成成本消失、視頻生成、實時生成三大方面給產業格局帶來重大變化。
1. 圖像生成成本消失
To C產品端,免費替代收費。受高昂的GPU算力成本限制,以Midjourney為代表的大量文生圖服務選擇免費增值作為商業模型。LCM使手機客戶端、個人電腦CPU、瀏覽器(WebAssembly)、更容易彈性擴容的CPU算力都可能在未來滿足圖像生成的算力需求。簡單的收費文生圖服務如Midjourney會被高質量的免費服務替代。
To B服務端,減少的生成算力需求會被增長的訓練算力需求替代。
AI圖片生成服務對算力的需求在峰值和谷底漲落極大,購買服務器閑置時間通常超過50%。這種特點促進了大量函數計算GPU(serverless GPU)如美國Replicate、中國阿里云的蓬勃發展。
硬件虛擬化方面如國內的瑞云、騰訊云等也在浪潮中推出了圖像模型訓練相關虛擬桌面產品。隨著生成算力下放到邊緣、客戶端或更容易擴容的CPU算力,AI生圖將普及到各類應用場景中,圖像模型微調的需求會大幅上漲。在圖像領域,專業、易用、垂直的模型訓練服務會成為下一階段云端GPU算力的主要消費者。
2. 文生視頻
文生視頻目前極高的生成成本制約了技術的發展和普及,消費級顯卡只能以緩慢的速度逐幀渲染。以AnimateDiff WebUI插件為代表的一批項目優先支持了LCM,使得更多人能參與到文生視頻的開源項目中。更低的門檻必然會加速文生視頻的普及和發展。

3分鐘快速渲染:AnimateDiff Vid2Vid + LCM
3. 實時渲染
速度的增加催生了大量新應用,不斷拓展著所有人的想象空間。
RT-LCM與AR
以RealTime LCM為先導,消費級GPU上第一次實現了每秒10幀左右的實時視頻生成視頻,這在AR領域必然產生深遠的影響。
目前高清、低延時捕捉重繪視線內整個場景需要極高算力,所以過去AR應用主要以添加新物體、提取特征后低清重繪部分物體為主。LCM使得實時重繪整個場景成為可能,在游戲、互動式電影、社交等場景中都有無限的想象空間。
未來游戲場景不需新建,帶上AR眼鏡,身處的街道立刻轉換為霓虹閃爍的賽博朋克未來風格供玩家探索;看未來的互動式恐怖電影時帶上AR眼鏡,家中熟悉的一切可以無縫融入場景,嚇人的東西就藏在臥室門后。虛擬和現實將無縫融合,真實和夢境讓人愈發難以區分。而這一切底層都可能會有LCM的身影。

RT-LCM視頻渲染
交互方式 - 所想即所得(What you imagine is what you get)
由Krea.ai、ilumine.ai首先產品化的實時圖像編輯UI再次降低了創作的門檻、擴大了創意的邊界,讓更多人在精細控制的基礎上獲得了最終畫作的實時反饋。

Krea.ai實時圖像編輯
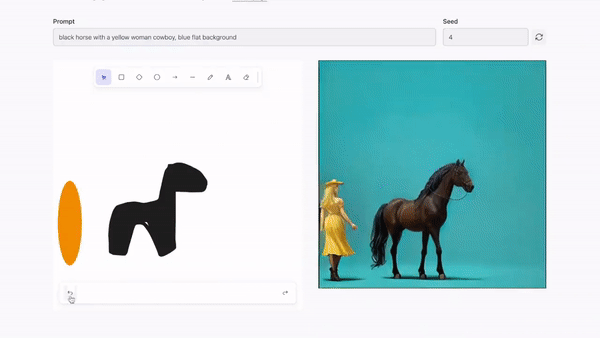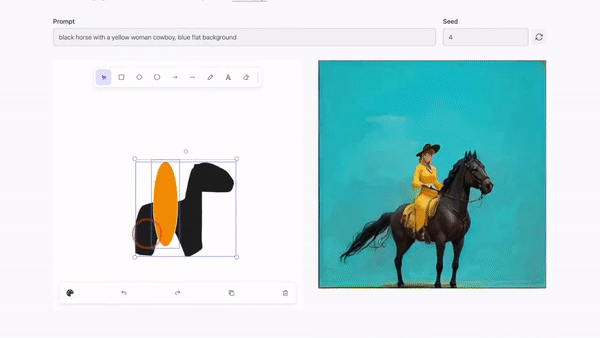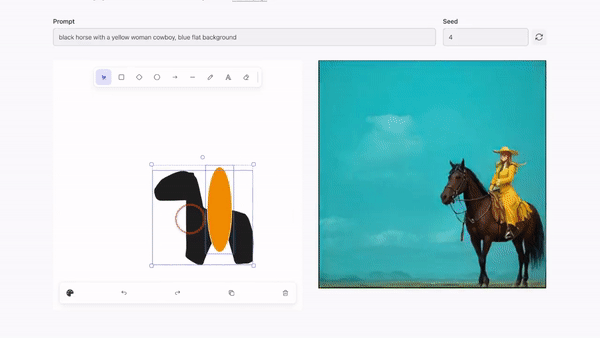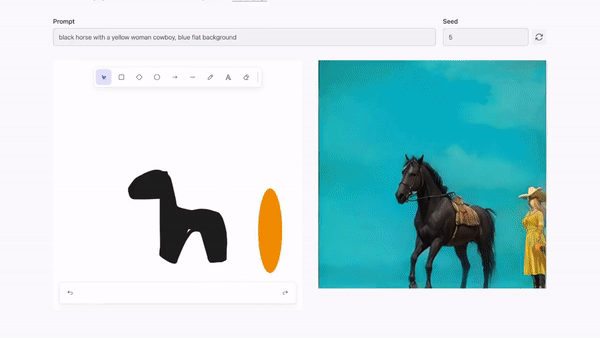
實時圖像編輯
建模軟件 + LCM探索了3D建模的新方向,讓3D建模師在所見即所得基礎上更進一步,獲得了所想即所得的能力。

LCM實時空間建模渲染
手是人類最沒用的東西,因為手永遠跟不上腦子的速度。所見即所得(What you see is what you get)太慢,所想即所得(What you imagine is what you get)會成為未來的創意工作的主流。
LCM第一次讓展示效果跟上了靈感創意產生的速度。新的交互方式持續涌現,AIGC革命的終點是將創意的成本、技術門檻降低至無限接近于0。不分行業,好的創意將會從稀缺變為過剩。LCM將我們向未來又推進了一步。



























