分布式一致性方案有多難?看完這篇我驚出冷汗
兄弟們,今天咱們來聊聊分布式系統里一個讓人又愛又恨的話題 —— 分布式一致性方案。為啥說又愛又恨呢?愛的是它是分布式系統的核心基石,恨的是它實在太難搞了,分分鐘讓人驚出冷汗。別著急,咱們慢慢嘮,盡量用大白話,帶點小幽默,讓大家舒舒服服地把這硬骨頭啃下來。
一、先搞懂啥是分布式一致性
咱先不著急上技術,先打個比方。假設你和幾個好兄弟一起開了個小超市,每個人負責一個貨架,記錄商品的庫存。突然有一天,你們覺得單干不行,得搞個聯合庫存系統,大家的庫存數據得保持一致,不然顧客來買東西,這邊說有貨,那邊說沒貨,那就鬧笑話了。這時候,你們就面臨著分布式一致性的問題 —— 多個節點(你們各自的貨架記錄)的數據要保持一致。
在分布式系統中,一致性指的是多個副本之間的數據是否一致。這里的副本可以是數據庫的副本、緩存的副本等等。分布式系統為啥會有一致性問題呢?因為它由多個節點組成,節點之間通過網絡通信,而網絡是不可靠的,可能會出現延遲、丟包,甚至節點故障等情況。這就好比你和兄弟之間打電話溝通庫存,電話可能會斷,信號可能不好,導致信息傳遞有誤。
二、一致性模型:不同的一致性要求
在分布式系統中,根據一致性的強弱,有幾種不同的一致性模型。
強一致性
強一致性是最嚴格的一致性模型,要求更新操作完成后,所有節點在同一時間看到的最新數據都是一致的。就像你和兄弟說,我剛剛把蘋果的庫存從 10 個改成 8 個,那不管誰去查,都得馬上看到 8 個,不能有的看到 10 個,有的看到 8 個。這種一致性很好理解,但實現起來最難,因為要處理各種網絡問題和節點故障,確保所有節點都收到更新并應用。
弱一致性
弱一致性就比較寬松了,允許在更新操作后,不是所有節點都立即看到最新數據,而是過一段時間后才會逐漸一致。比如你改了蘋果庫存,可能有的兄弟節點過一會兒才收到消息更新庫存。這種一致性實現起來簡單一些,但可能會出現數據不一致的情況,比如顧客在不同節點查詢到不同的庫存數據。
最終一致性
最終一致性是弱一致性的一種特殊情況,它保證在沒有新的更新操作的情況下,經過一段時間后,所有節點的數據最終會達到一致。這是分布式系統中最常用的一致性模型,比如分布式緩存 Redis 的集群模式就采用了最終一致性。就像你和兄弟雖然一開始庫存數據不一樣,但隨著時間推移,通過各種同步機制,最終會變成一樣的。
三、分布式一致性方案大起底
接下來,咱們就來看看那些讓人又愛又恨的分布式一致性方案。
二階段提交(2PC):理想很豐滿,現實很骨感
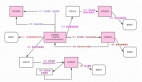
二階段提交是分布式事務中常用的一致性方案,它把事務的提交過程分成兩個階段:準備階段和提交階段。
準備階段(投票階段)
協調者(可以看作是分布式系統中的一個中心節點)向所有參與者(其他節點)發送準備請求,詢問是否可以執行事務提交操作。參與者收到請求后,會執行事務的所有操作,但不會真正提交事務,而是記錄日志,然后向協調者返回是否同意提交的響應。比如在數據庫的分布式事務中,參與者會執行數據庫的更新操作,但只是把數據寫入日志,不真正更新數據庫的數據。
這就好比公司要組織一次團建,領導(協調者)先問各個部門(參與者),下周六大家有沒有空參加團建呀?各個部門回去看看自己的工作安排,然后告訴領導能不能參加。
提交階段(執行階段)
如果協調者收到所有參與者都同意提交的響應,那么就向所有參與者發送提交請求,參與者收到后就會真正提交事務。如果有任何一個參與者不同意提交,或者在規定時間內沒有收到參與者的響應,協調者就會向所有參與者發送回滾請求,參與者回滾事務。
接著上面的例子,領導收到所有部門都說有空,那就通知大家下周六去團建;要是有一個部門說沒空,領導就只能取消團建,通知大家各忙各的。
看起來挺合理的吧?但在實際應用中,二階段提交有很多問題。首先,它是同步阻塞的,在準備階段和提交階段,所有參與者都處于阻塞狀態,不能處理其他事務,這會影響系統的性能。其次,它對協調者的依賴很強,如果協調者在提交階段發生故障,比如發送提交請求到一半死機了,有的參與者收到了提交請求,有的沒收到,就會導致數據不一致。還有,網絡延遲和超時處理也很麻煩,比如參與者在準備階段同意提交,但在提交階段因為網絡問題沒收到提交請求,一直處于阻塞狀態,不知道該提交還是回滾。
三階段提交(3PC):想彌補 2PC 的缺陷,卻還是有漏洞
三階段提交是為了改進二階段提交的缺陷而提出的,它把提交過程分成了三個階段:CanCommit、PreCommit 和 DoCommit。
CanCommit 階段
協調者向參與者發送一個詢問請求,詢問是否可以執行事務。參與者只需要檢查自身的資源是否足夠,比如數據庫的連接、鎖等,而不需要執行實際的事務操作。如果可以,就返回同意;否則返回不同意。這相當于領導先問大家,下周六理論上有沒有可能參加團建,不考慮具體的工作安排,只是看看時間上是否有沖突。
PreCommit 階段
如果 CanCommit 階段所有參與者都同意,協調者就會進入 PreCommit 階段,向參與者發送預提交請求,參與者執行事務操作,但和 2PC 一樣,不真正提交,記錄日志,然后返回確認。如果有參與者不同意,或者協調者超時,就會進入中斷流程,發送中斷請求,參與者不執行事務。
這一步和 2PC 的準備階段有點類似,但這里協調者在發送預提交請求之前,會先發送一個心跳包,檢查參與者的狀態,避免 2PC 中協調者故障導致的問題。
DoCommit 階段
如果 PreCommit 階段所有參與者都確認,協調者就發送提交請求,參與者真正提交事務;如果有問題,就發送回滾請求。
三階段提交相比二階段提交,減少了阻塞的時間,在 CanCommit 階段可以提前發現一些無法執行事務的情況,避免后續的無用操作。而且引入了超時機制,當參與者超時沒收到協調者的請求時,會自動進行提交或回滾,一定程度上解決了協調者故障的問題。但它還是沒有完全解決分布式系統中的一致性問題,比如在 DoCommit 階段,協調者發送提交請求后故障,部分參與者收到了,部分沒收到,還是會導致數據不一致。而且實現起來比 2PC 更復雜,所以在實際應用中也不是特別廣泛。
Paxos 算法:分布式一致性的經典之作,卻難倒一片英雄漢
Paxos 算法是分布式一致性領域的經典算法,由 Leslie Lamport 提出。它的目標是在一個可能發生消息丟失、重復、延遲的分布式系統中,確保多個進程對某個值達成一致。
基本概念
- 提案(Proposal):包含一個提案編號和一個值,提案編號是唯一的,且單調遞增。
- 提議者(Proposer):提出提案的節點,負責發起一致性過程。
- 接受者(Acceptor):接收提案的節點,決定是否接受提案。
- 學習者(Learner):只需要知道最終達成一致的值,不參與提案的過程。
算法過程
Paxos 算法的過程可以分為兩個階段:prepare 階段和 accept 階段。
prepare 階段
提議者選擇一個提案編號 n,向大多數接受者發送 prepare 請求。接受者收到 prepare 請求后,如果提案編號 n 大于之前收到的所有提案編號,就會返回自己之前接受過的提案中編號最大的那個提案的值(如果有的話),并承諾不再接受編號小于 n 的提案。
這就好比在一個會議上,大家要決定選哪個方案,第一個人(提議者)說我要提一個方案,編號是 1,然后問大部分人(接受者),你們之前有沒有接受過其他方案呀?如果沒有,或者我的編號比你們之前的都大,你們就告訴我你們之前的情況,并且以后別接受比我編號小的方案。
accept 階段
提議者收到大多數接受者的 prepare 響應后,就可以確定一個值。如果有接受者在 prepare 響應中返回了之前接受過的提案的值,提議者就把這個值作為當前提案的值;否則,提議者可以自己確定一個值。然后提議者向這些接受者發送 accept 請求,包含提案編號 n 和確定的值。接受者收到 accept 請求后,如果提案編號 n 不小于之前承諾的最小提案編號,就接受這個提案,并記錄下來。
當有一個提案被大多數接受者接受后,這個值就被選定了,所有學習者就可以學習這個值,達成一致。
Paxos 算法的正確性證明非常復雜,需要滿足一系列的條件,比如安全性和活性。安全性保證不會有錯誤的決定,活性保證最終會達成一致。但它的實現也很困難,因為要處理各種異常情況,比如提議者故障、接受者故障、網絡分區等。而且 Paxos 算法的描述比較抽象,很多人第一次看都覺得云里霧里,這也是它難倒眾多開發者的原因。不過,基于 Paxos 算法衍生出了很多實用的方案,比如 Raft 算法。
Raft 算法:更易理解和實現的分布式一致性算法
Raft 算法是為了讓分布式一致性算法更易理解和實現而設計的,它把分布式系統中的節點狀態分為三種:領導者(Leader)、跟隨者(Follower)和候選人(Candidate)。
領導者選舉
Raft 算法中,首先需要選舉出一個領導者,領導者負責處理客戶端的請求,管理日志的復制,保證數據的一致性。當跟隨者在一段時間內沒有收到領導者的心跳包(心跳包用于維持領導者的地位),就會認為領導者故障,進入候選人狀態,發起選舉。候選人向其他節點發送請求投票,當獲得大多數節點的投票后,就成為新的領導者。
這就像一個班級選班長,一開始有一個班長(領導者),如果同學們(跟隨者)很久沒收到班長的消息,就覺得班長可能不干了,然后有人(候選人)站出來說我來當班長,大家投票,得票最多的就成為新班長。
日志復制
客戶端的寫請求由領導者處理,領導者收到請求后,會將請求作為日志條目添加到自己的日志中,然后發送給所有跟隨者。跟隨者收到日志條目后,會將其寫入自己的日志,并返回確認。當領導者收到大多數跟隨者的確認后,就會提交該日志條目,并通知跟隨者提交,這樣所有節點的數據就保持一致了。
對于讀請求,通常可以直接由領導者處理,或者如果跟隨者保存了最新的數據,也可以處理讀請求,但需要確保跟隨者的數據是最新的,這可以通過領導者的心跳包來保證。
Raft 算法相比 Paxos 算法,更容易理解和實現,因為它把問題分解成了領導者選舉、日志復制等幾個相對獨立的部分,每個部分都有明確的狀態和流程。而且它的安全性和活性也有很好的保證,在實際應用中被廣泛采用,比如分布式存儲系統 etcd 就采用了 Raft 算法。
其他一致性方案
除了上面提到的這些方案,還有一些其他的一致性方案,比如 ZAB 協議(ZooKeeper 原子廣播協議),它和 Raft 算法類似,也是通過領導者選舉和日志復制來保證一致性,主要用于 ZooKeeper 分布式協調服務中。還有基于時間戳的向量時鐘算法,用于解決分布式系統中的因果一致性問題,通過給每個操作分配一個時間戳向量,來判斷操作之間的因果關系,從而保證一致性。
四、分布式一致性方案的難點在哪里
說了這么多方案,咱們來總結一下分布式一致性方案的難點到底有哪些。
網絡的不可靠性
這是分布式系統面臨的最根本問題之一。網絡可能會出現延遲、丟包、分區等情況,導致節點之間的通信失敗。比如在二階段提交中,協調者發送的提交請求可能因為網絡分區,只有部分參與者收到,導致數據不一致。在 Paxos 和 Raft 算法中,都需要處理網絡分區的情況,確保在網絡恢復后,系統能重新達成一致。
節點的故障
節點可能會因為硬件故障、軟件崩潰等原因而失效。當領導者節點故障時,需要快速選舉出新的領導者,并且保證日志的一致性。在 Raft 算法中,領導者選舉的時間和日志復制的機制都需要考慮節點故障的情況,確保系統的可用性和一致性。
一致性和可用性的權衡
在分布式系統中,有一個著名的 CAP 定理,它指出一個分布式系統不可能同時滿足一致性(Consistency)、可用性(Availability)和分區容錯性(Partition Tolerance)這三個特性,最多只能同時滿足兩個。這就意味著我們在設計分布式一致性方案時,需要根據實際需求,在一致性和可用性之間做出權衡。比如在金融系統中,可能更注重一致性,而在一些高可用性的系統中,可能會選擇最終一致性,犧牲一定的強一致性來保證系統的可用性。
實現的復雜性
從上面介紹的各種方案可以看出,分布式一致性方案的實現都非常復雜,需要處理各種異常情況,保證算法的正確性和效率。比如 Paxos 算法的正確性證明需要嚴格的數學推導,Raft 算法雖然更易理解,但實現起來也需要處理領導者選舉、日志復制、節點故障恢復等多個模塊,每個模塊都可能出現問題,需要仔細調試和測試。
五、如何選擇合適的分布式一致性方案
說了這么多難點,那我們在實際項目中該如何選擇合適的分布式一致性方案呢?
明確業務需求
首先要明確業務對一致性的要求。如果是金融交易、訂單支付等場景,要求強一致性,那就需要選擇像二階段提交、Paxos 算法、Raft 算法等能夠保證強一致性的方案,但也要考慮系統的性能和可用性。如果是一些對一致性要求不高的場景,比如用戶行為日志記錄、緩存數據同步等,可以選擇最終一致性的方案,比如分布式緩存的異步同步機制。
考慮系統的規模和復雜度
如果是小規模的分布式系統,節點數量較少,業務邏輯簡單,可以選擇實現相對簡單的方案,比如 Raft 算法,或者一些基于開源框架的解決方案,比如 etcd 提供的 Raft 實現,減少自己開發的難度和風險。如果是大規模的分布式系統,節點數量眾多,業務復雜,可能需要結合多種方案,比如在分布式事務中使用二階段提交,在分布式存儲中使用 Paxos 或 Raft 算法,同時還要考慮系統的擴展性和容錯性。
參考開源項目和最佳實踐
開源項目是我們學習和借鑒的寶貴資源。比如 ZooKeeper 使用 ZAB 協議,etcd 使用 Raft 算法,Redis 的集群模式采用最終一致性,我們可以研究這些開源項目的實現,了解它們在不同場景下的應用和優化策略。同時,行業內的最佳實踐也很重要,比如在微服務架構中,如何保證多個服務之間的數據一致性,通常會采用分布式事務、最終一致性等方案,結合業務的特點進行選擇。
六、總結:分布式一致性,難,但值得挑戰
分布式一致性方案確實很難,它涉及到網絡、節點故障、算法設計、性能優化等多個方面,每一個環節都可能讓人頭疼不已。但它又是分布式系統的核心,是我們構建高可靠、高可用分布式系統的基礎。
從二階段提交到三階段提交,從 Paxos 算法到 Raft 算法,每一個方案的出現都是為了解決之前方案的不足,都是無數開發者智慧的結晶。雖然實現起來復雜,但隨著技術的發展,越來越多的開源框架和工具提供了成熟的一致性解決方案,讓我們在實際項目中可以站在巨人的肩膀上,不用從頭開始造輪子。
作為 Java 開發者,我們需要了解這些分布式一致性方案的原理和適用場景,根據業務需求做出合適的選擇。同時,也要不斷學習和研究新的技術,迎接分布式系統帶來的挑戰。也許現在覺得難,但只要慢慢啃,總有一天會豁然開朗。