譯者 | 崔皓
審校 | 重樓
隨著機器學習模型的復雜性和規模不斷增長,任何企業或者組織在部署、擴展模型上都面臨著巨大的挑戰。迫在眉睫的挑戰是如何在內存限制與模型規模之間取得平衡,并保持高性能和成本效益。本文探討了一種創新的架構解決方案,通過將共享神經編碼器與專門的預測頭結合的混合方法來應對這些挑戰。

挑戰:ML 模型部署中的內存限制
傳統機器學習模型的部署通常需要將完整模型加載到內存中,以供用例或客戶應用程序使用。例如,在自然語言理解(NLU)應用中使用基于 BERT 的模型,每個模型通常消耗大約 210-450MB 的內存。在為眾多客戶提供服務時,這會面臨內存容量不足需要擴展的挑戰。擁有 72GB CPU 內存的經典服務器只能支持大約 100 個模型,如此這般就會為服務能力設定上限。
一種新穎的解決方案:解耦架構
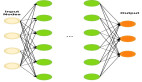
為了解決模型服務量增大而內存不足的問題,我們采用了解耦架構,將模型分為兩個關鍵組件。第一個是共享神經編碼器(SNE),一個預訓練的神經網絡組件,處理輸入數據的基本編碼。在實踐應用過程中,基于 BERT 架構的這個編碼器生成上下文嵌入 - 對于輸入文本中的每個標記是 768 維向量。第二個組件是任務特定的預測頭(TSPH),它是用來嵌入特定預測的專業化組件。這種架構允許多個客戶應用相同的共享編碼器,同時通過各自的專業化組件保持其獨特的預測能力。
關鍵組件及其相互作用
共享神經編碼器
共享神經編碼器充分利用了預訓練模型,該預訓練模型在大型通用數據集上進行過訓練。實現過程中,編碼器組件需要大約 227 MB 的非量化形式,但通過 INT8 量化,可以將其減少到約 58 MB。在處理文本時,它處理長達 250 個令牌的序列,生成高維上下文嵌入。對于典型的包含 15 個令牌的話語,編碼器生成尺寸為 15x768 的輸出張量,對嵌入需要約 45 KB 的內存。
任務特定的預測頭
任務專用預測頭代表了在效率上的顯著改進,其非量化形式只需 36 MB,量化后甚至只需 10 MB。該組件針對意圖分類和實體識別等任務保留了自定義配置,同時比傳統完整模型消耗的內存大大減少。例如,單個預測頭可以在標準 CPU 硬件上在不到 5 毫秒內處理 15x768 維的嵌入向量并輸出分類分數。
性能指標和實施
通過使用這種架構進行的測試,收獲了令人滿意的性能特征。使用一臺具有 36 個虛擬 CPU 和 72GB 內存的 c5.9xlarge 實例,單個服務器在僅運行預測頭時可以處理約每秒 1,500 筆運算(TPS),且 p90 延遲為 25 毫秒。當將兩個組件組合在同一硬件上時,我們仍然可以實現 300TPS,p90 延遲為 35 毫秒——對大多數生產工作負載來說已足夠。
編碼器組件在 GPU 硬件上部署時(具體為 p3.2xlarge 實例),可以以每秒超過 1,000 個請求的速度處理,延遲僅為 10 毫秒。該配置允許對請求進行高效的分批處理,最佳分批大小為 16 個請求,提供吞吐量和延遲的最佳平衡。
基礎設施設計
采用具有特定性能目標的單元架構方法。架構中的每個單元設計用于處理約 1,000 個活躍模型,同時具有自動擴展功能,可在三個可用區域中保持單元的健康狀態。系統采用復雜的負載平衡策略,能夠處理每個單元高達 600TPS 的突發量,同時保持 p99 延遲在 80 毫秒以下。
為了實現高可用性,架構實施了一種多環設計,其中每個環提供特定的語言區域。例如,所有英語變體可能共享一個環,而法語變體則共享另一個環,可根據特定語言模型特性進行有效的資源分配。每個環包含多個單元格,可以根據需求獨立進行擴展。
資源優化
解耦架構實現了顯著的資源優化。在生產環境中,實際測量顯示如下:
- 內存減少。原始 210 MB 的模型被縮減到 10 MB 的預測頭部加上一個共享的 58 MB 編碼器。
- 存儲效率。編碼器可以為數千個預測頭提供服務,最多可以減少 75%的總存儲需求。
- 成本效率。 GPU 資源在編碼器的所有請求之間共享,而更便宜的 CPU 資源用于處理預測頭。
- 延遲改善。端到端處理時間,對于緩存模型從 400 毫秒減少到大約 35 毫秒。
對未來的影響
這種架構模式為 ML 部署打開了新的可能性,特別是隨著模型規模不斷增長。隨著當前趨勢指向更大的語言模型,共享編碼表示變得越來越有價值。這種架構通過以下方式支持未來的增長:
- 動態模型更新:可以部署新的編碼器版本,而無需更新預測頭。
- 靈活的縮放:基于特定工作負載特征獨立縮放編碼器和預測組件。
- 資源池:高效共享 GPU 資源,服務于更多客戶。
結論
將“共享神經編碼器”與“特定任務預測頭”相結合的解耦架構代表著機器學習模型部署中的一項重大進步。在性能提升方面表現優秀,例如: 75% 的內存減少、40% 的延遲改善,從而支持高并發模型。該方法提供了一種解決方案,既可以應對規模挑戰,同時又能保持性能并控制成本。
對于希望實施類似架構的組織,應仔細考慮特定工作負載特征。方案的成功與否取決于,對基礎設施設計和智能資源管理策略的深度思考,只有這樣才能支持強大的監控和擴展策略。
譯者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。
原文標題:Scaling ML Models Efficiently With Shared Neural Networks,作者:Meghana Puvvadi