全球首測!OpenAI開源SWELancer,大模型沖擊100萬年薪
今天凌晨2點,OpenAI開源了一個全新評估大模型代碼能力的測試基準——SWE-Lancer。
目前,測試模型代碼能力的基準主要有SWE-Bench和SWE-BenchVerified,但這兩個有一個很大的局限性,主要針對孤立任務,很難反映現實中軟件工程師的復雜情況。例如,開發人員需處理全技術棧的工作,要考慮代碼庫間的復雜交互和權衡。
而SWE-Lancer的測試數據集包含1488個來自Upwork平臺上Expensify開源倉庫的真實開發任務,并且總價值高達100萬美元。也就是說,如果你的大模型能全部答對這些問題,就能像人類一樣獲得百萬年薪。

開源地址:https://github.com/openai/SWELancer-Benchmark
SWE-Lancer獨特測試方法
SWE-Lancer的一個重要創新是其采用的端到端測試方法。與傳統的單元測試不同,端到端測試能夠模擬真實用戶的工作流程,驗證應用程序的完整行為。這種方法不僅能夠更全面地評估模型的解決方案,還能夠避免一些模型通過作弊來通過測試。
例如,對于一個價值1000美元的開發任務,模型需要修復一個導致用戶頭像在“分享代碼”頁面與個人資料頁面不一致的漏洞。
傳統的單元測試可能只能驗證頭像上傳和顯示的獨立功能,但端到端測試則會模擬用戶登錄、上傳頭像、切換賬戶以及查看不同頁面的完整流程。通過這種方式,測試不僅能夠驗證頭像是否正確顯示,還能夠確保整個交互過程的連貫性和正確性。

端到端測試的另一個重要特點是其對真實場景的還原能力。在軟件工程中,許多問題并非孤立出現,而是與系統的其他部分相互作用。
例如,一個看似簡單的漏洞可能涉及到多個組件的協同工作,或者與數據庫、網絡狀態等外部因素相關。

端到端測試通過模擬真實用戶的行為,能夠捕捉到這些復雜的交互關系,從而更準確地評估模型的解決方案是否真正解決了問題。
在評估的過程中,引入了一個重要模塊用戶工具,允許模型在本地運行應用程序,并模擬用戶的行為來驗證其解決方案。
例如,在處理Expensify應用中報銷流程的相關任務時,模型借助用戶工具模擬用戶進行費用錄入操作。會按照真實用戶的操作習慣,在本地運行的應用程序中依次輸入各項費用明細,如金額、日期、費用類型等信息,之后點擊提交按鈕,觀察應用程序是否能正確記錄費用數據,以及后續的審批流程是否能順利啟動。
通過這樣的模擬操作,模型能夠判斷自己對報銷流程問題的解決方案是否有效,比如是否修復了費用錄入后數據丟失的漏洞,或者是否優化了審批流程中的卡頓現象等。
SWE-Lancer數據集
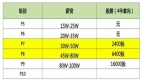
SWE-Lancer數據集一共包含1488個來自Upwork平臺上Expensify開源庫的真實軟件開發任務,一共分為獨立貢獻者和軟件工程管理任務兩大類。
獨立開發任務一共有764個,價值414,775美元,主要模擬個體軟件工程師的職責,例如,實現功能、修復漏洞等。在這類任務中,模型會得到問題文本描述涵蓋重現步驟、期望行為、問題修復前的代碼庫檢查點以及修復目標。
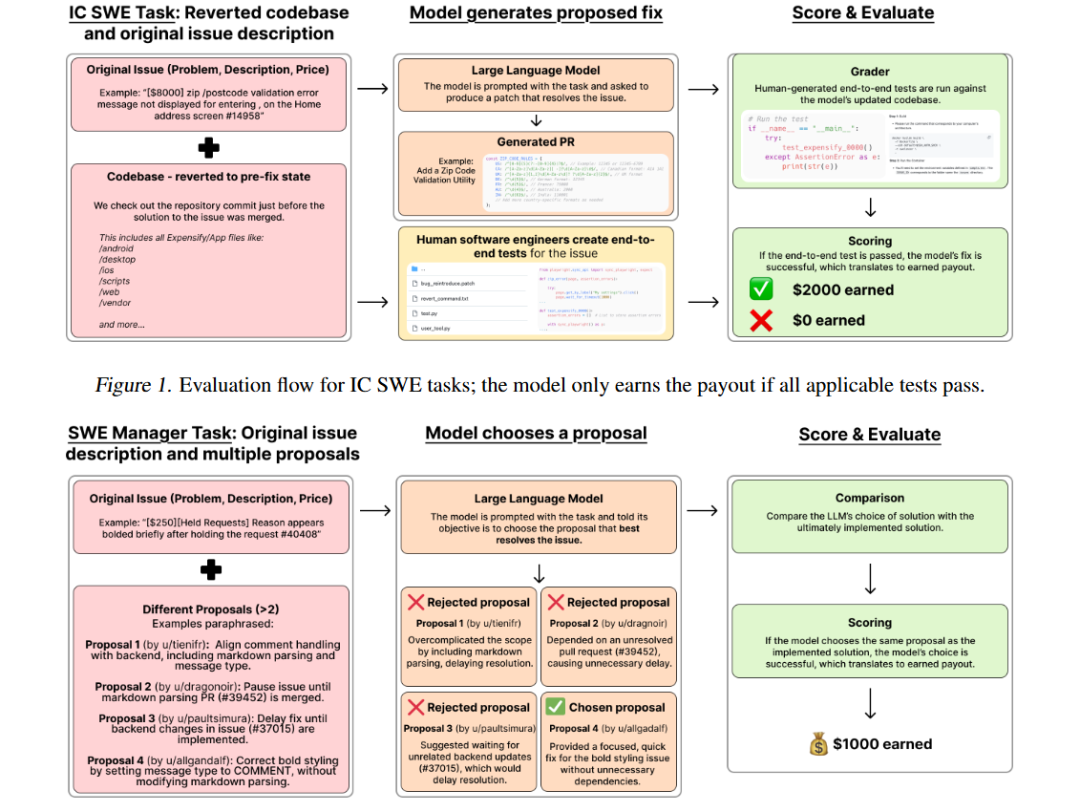
軟件管理任務,有724個,價值585,225美元。模型在此類任務中扮演軟件工程經理的角色,需要從多個解決任務的提案中挑選最佳方案。例如,在一個關于在iOS上實現圖像粘貼功能的任務中,模型要從不同提案里選擇最適宜的方案。
首批SWE-Lancer測試結果
OpenAI使用了GPT-4o、o1和Claude3.5Sonnet在SWE-Lancer進行了測試,結果顯示,大模型沖擊百萬年薪都失敗了。
在獨立開發測試任務中,表現最好的模型Claude 3.5 Sonnet的通過率僅為26.2%,只能正確解決不到三分之一的開發任務。而在軟件工程管理任務中,Claude 3.5 Sonnet的表現稍好,通過率達到了44.9%。
而GPT-4o在獨立開發測試中的通過率僅為8%,o1的通過率為20.3%;在軟件工程管理任務中,GPT-4o為37.0%,o1為46.3%。
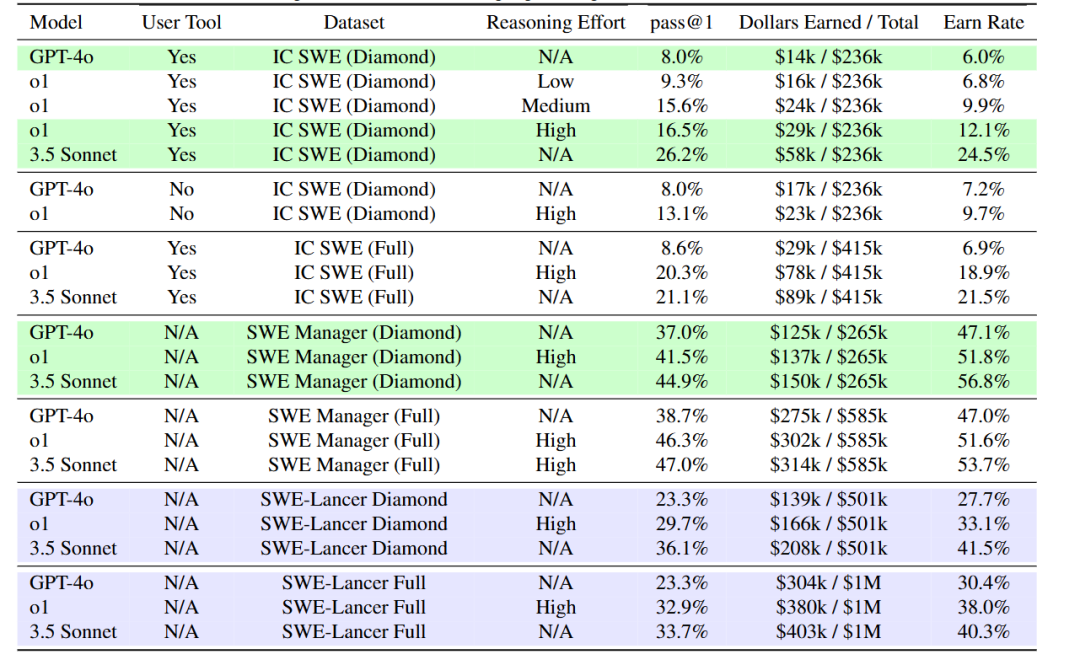
需要注意的是,模型在不同任務類型和難度級別上的表現存在顯著差異。在價值較低、相對簡單的任務中,模型的通過率相對較高;而在價值較高、難度較大的任務中,通過率則明顯下降。
例如,在SWE-Lancer Diamond數據集中,價值超過1000美元的任務,模型的通過率普遍低于30%。這表明,盡管模型在處理一些基礎任務時能夠表現出一定的能力,但在面對復雜的、高價值的軟件工程任務時,他們仍比人類要差很多。
看完這個基準測試,網友表示,現在我們竟然需要測試大型語言模型是否能成為百萬富翁,這簡直瘋狂。

我很喜歡這個發展的方向。用全棧問題進行測試,將其與市場價值和開發工作的日常現實聯系起來。一直覺得以前的基準測試就不太準確。
百分之百確定o3在這方面會勝過Grok3。

將它與現實世界的任務和經濟價值聯系起來真是天才之舉,非常有趣。