













華人研究團(tuán)隊(duì)揭秘:DeepSeek-R1-Zero或許并不存在「頓悟時(shí)刻」
在過去這半個(gè)月里,關(guān)于 DeepSeek 的一切都會(huì)迅速成為焦點(diǎn)。
一項(xiàng)非常鼓舞人心的發(fā)現(xiàn)是:DeepSeek-R1-Zero 通過純強(qiáng)化學(xué)習(xí)(RL)實(shí)現(xiàn)了「頓悟」。在那個(gè)瞬間,模型學(xué)會(huì)了自我反思等涌現(xiàn)技能,幫助它進(jìn)行上下文搜索,從而解決復(fù)雜的推理問題。
在 R1-Zero 發(fā)布后的短短幾天內(nèi),連續(xù)幾個(gè)項(xiàng)目都在較小規(guī)模(如 1B 到 7B)上獨(dú)立「復(fù)制」了類似 R1-Zero 的訓(xùn)練,并且都觀察到了「頓悟時(shí)刻」,這種時(shí)刻通常伴隨著響應(yīng)長度的增加。

原文鏈接:https://oatllm.notion.site/oat-zero
最近,來自新加坡 Sea AI Lab 等機(jī)構(gòu)的研究者再次梳理了類 R1-Zero 的訓(xùn)練過程,并在一篇博客中分享了三項(xiàng)重要發(fā)現(xiàn):
1. 在類似 R1-Zero 的訓(xùn)練中,可能并不存在「頓悟時(shí)刻」。相反,我們發(fā)現(xiàn)「頓悟時(shí)刻」(如自我反思模式)出現(xiàn)在 epoch 0,即基礎(chǔ)模型中。
2. 他們從基礎(chǔ)模型的響應(yīng)中發(fā)現(xiàn)了膚淺的自我反思(SSR),在這種情況下,自我反思并不一定會(huì)導(dǎo)致正確的最終答案。
3. 仔細(xì)研究通過 RL 進(jìn)行的類 R1-Zero 的訓(xùn)練,發(fā)現(xiàn)響應(yīng)長度增加的現(xiàn)象并不是因?yàn)槌霈F(xiàn)了自我反思,而是 RL 優(yōu)化設(shè)計(jì)良好的基于規(guī)則的獎(jiǎng)勵(lì)函數(shù)的結(jié)果。
以下是博客的內(nèi)容:
Epoch 0 的頓悟時(shí)刻
實(shí)驗(yàn)設(shè)置如下:
基礎(chǔ)模型。我們研究了由不同組織開發(fā)的各種基礎(chǔ)模型系列,包括 Qwen-2.5、Qwen-2.5-Math、DeepSeek-Math、Rho-Math 和 Llama-3.x。
提示模板。我們使用 R1-Zero 和 SimpleRL-Zero 中使用的模板直接提示基礎(chǔ)模型:
- 模板 1(與 R1-Zero 相同)

- 模板 2(與 SimpleRL-Zero 相同)

數(shù)據(jù)。我們從 MATH 訓(xùn)練數(shù)據(jù)集中收集了 500 道題,這些題統(tǒng)一涵蓋了五個(gè)難度級(jí)別和所有科目,用于填充上述模板中的 {Question}。
生成參數(shù)。我們?cè)?0.1 至 1.0 之間對(duì)探索參數(shù)(溫度)進(jìn)行網(wǎng)格搜索,以便對(duì)選定的問題進(jìn)行模型推理。在所有實(shí)驗(yàn)中,Top P 設(shè)置為 0.9。我們?yōu)槊總€(gè)問題生成 8 個(gè)回答。
經(jīng)驗(yàn)結(jié)果
我們首先嘗試了所有模型和提示模板(模板 1 或模板 2)的組合,然后根據(jù)每個(gè)模型的指令遵循能力為其選擇了最佳模板,并將其固定用于所有實(shí)驗(yàn)。得出以下結(jié)論:
發(fā)現(xiàn):「頓悟時(shí)刻」出現(xiàn)在 Epoch 0。我們觀察到,所有模型(除了 Llama-3.x 系列)在沒有任何后期訓(xùn)練的情況下就已經(jīng)表現(xiàn)出了自我反思模式。
我們?cè)谙卤碇辛谐隽怂杏^察到的表明自我反思模式的關(guān)鍵詞。請(qǐng)注意,該列表可能并不詳盡。這些關(guān)鍵詞都是經(jīng)過人工驗(yàn)證的,「等待」等詞被過濾掉了,因?yàn)樗鼈兊某霈F(xiàn)并不一定意味著自我反思,而可能是幻覺的結(jié)果。我們注意到,不同的模型會(huì)顯示與自我反思相關(guān)的不同關(guān)鍵詞,我們假設(shè)這是受其預(yù)訓(xùn)練數(shù)據(jù)的影響。
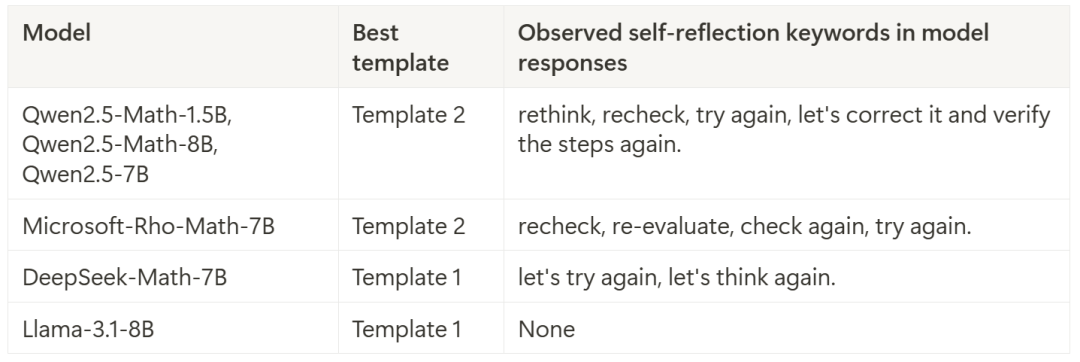
圖 1a 展示了在不同基礎(chǔ)模型中引發(fā)自我反思行為的問題數(shù)量。結(jié)果表明,在不同的溫度下都能觀察到自我反思行為,其中一個(gè)趨勢是,溫度越高,在 epoch 0 出現(xiàn)「頓悟時(shí)刻」的頻率越高。
圖 1b 展示了不同自我反思關(guān)鍵詞的出現(xiàn)次數(shù)。我們可以觀察到,Qwen2.5 系列的基礎(chǔ)模型在產(chǎn)生自我反思行為方面最為活躍,這也部分解釋了為什么大多數(shù)開源的 R1-Zero 復(fù)現(xiàn)都是基于 Qwen2.5 模型。
圖 1a. 在不同基礎(chǔ)模型中,500 道數(shù)學(xué)問題中引發(fā)自我反思行為的問題數(shù)量。圖 1b. 40,000 個(gè)回答中出現(xiàn)的關(guān)鍵詞數(shù)量(500 個(gè)問題 × 每個(gè)問題 8 個(gè)回答 × 10 個(gè)溫度)。
在確認(rèn)「頓悟時(shí)刻」確實(shí)是在沒有任何訓(xùn)練的情況下出現(xiàn)在 epoch 0 后,我們想知道它是否如我們所期望的那樣 —— 通過自我反思來糾正錯(cuò)誤推理。因此,我們直接在 Qwen2.5-Math-7B 基礎(chǔ)模型上測試了 SimpleRL-Zero 博客中使用的例題。令人驚訝的是,我們發(fā)現(xiàn)基礎(chǔ)模型已經(jīng)表現(xiàn)出了合理的自我糾正行為,如圖 2 所示。

圖 2. 我們直接在 Qwen2.5-Math-7B 基本模型上測試了 SimpleRL-Zero 博客中報(bào)告的同一問題,發(fā)現(xiàn)「頓悟時(shí)刻」已經(jīng)出現(xiàn)。
膚淺的自我反思
盡管圖 2 中的示例顯示了基礎(chǔ)模型通過自我修正 CoT 直接解決復(fù)雜推理問題的巨大潛力,但我們發(fā)現(xiàn)并非所有來自基礎(chǔ)模型的自我反思都有效,也并不總能帶來更好的解決方案。為了便于討論,我們將它們稱為膚淺的自我反思(Superficial Self-Reflection,SSR)。
就其定義而言,膚淺的自我反思(SSR)是指模型響應(yīng)中缺乏建設(shè)性修改或改進(jìn)的重評(píng)估模式。與沒有自我反思的響應(yīng)相比,SSR 不一定會(huì)帶來更好的答案。
案例研究
為了進(jìn)一步了解 SSR,我們進(jìn)行了案例研究,并觀察到 Qwen-2.5-Math-7B 基礎(chǔ)模型響應(yīng)中的四種自我反思模式:
- 行為 1:自我反思,反復(fù)檢查以確認(rèn)正確答案(圖 3a);
- 行為 2:自我反思,糾正最初錯(cuò)誤的想法(圖 3b 和圖 2);
- 行為 3:自我反思,在原本正確的答案中引入錯(cuò)誤(圖 3c);
- 行為 4:反復(fù)自我反思,但未能得出有效答案(圖 3d)。
其中, 行為 3 和行為 4 是膚淺的自我反思,導(dǎo)致最終答案不正確。

圖 3a:自我反思再三檢查答案,確保正確性。

圖 3b:自我反思糾正最初錯(cuò)誤的答案。

圖 3c:自我反思在原本正確的答案(x=12)中引入錯(cuò)誤(x=4)。

圖 3d:反復(fù)自我反思卻無法提供有效的答案(無論正確或不正確)。
基礎(chǔ)模型容易出現(xiàn) SSR
接下來,我們分析了 Qwen2.5-Math-1.5B 正確和錯(cuò)誤答案中自我反思關(guān)鍵詞的出現(xiàn)情況。正如圖 4 所示,在不同的采樣溫度下,大多數(shù)自我反思(以頻率衡量)都沒有得到正確答案。這表明基礎(chǔ)模型容易產(chǎn)生膚淺的自我反思。
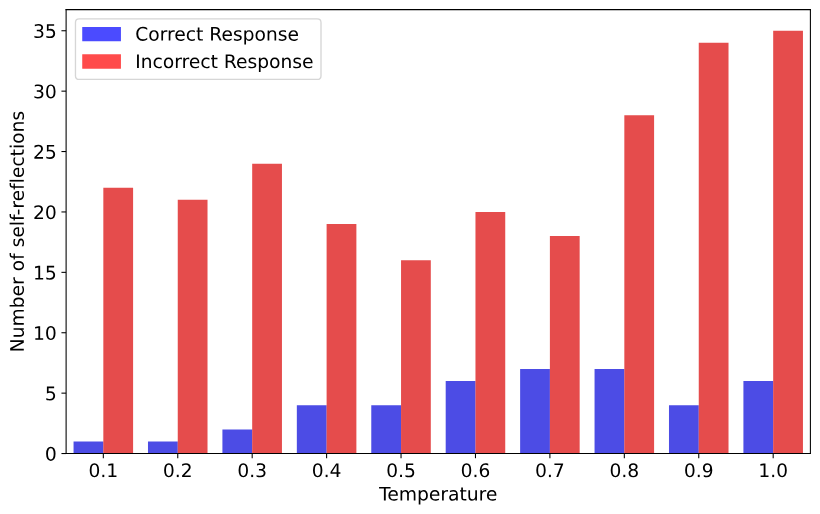
圖 4:正確和錯(cuò)誤答案中的自我反思次數(shù)。藍(lán)色條表示正確答案中自我反思關(guān)鍵詞的總出現(xiàn)次數(shù),而紅色條表示錯(cuò)誤答案中自我反思關(guān)鍵詞的總出現(xiàn)次數(shù)。
深入探討類 R1-Zero 訓(xùn)練
雖然模型響應(yīng)長度的突然增加通常被視為類 R1-Zero 訓(xùn)練中的頓悟時(shí)刻,但正如博客 Section 1 中的研究結(jié)果表明:即使沒有 RL 訓(xùn)練,這種頓悟時(shí)刻也可能發(fā)生。因此,這自然引出了一個(gè)問題:為什么模型響應(yīng)長度遵循一種獨(dú)特的模式,即在訓(xùn)練初期減少,然后在某個(gè)點(diǎn)激增?
為了研究這一點(diǎn),我們通過以下兩種方法來研究類 R1-Zero 訓(xùn)練:
- 在倒計(jì)時(shí)(Countdown)任務(wù)上復(fù)制 R1-Zero 以分析輸出長度動(dòng)態(tài);
- 在數(shù)學(xué)問題上復(fù)制 R1-Zero 以研究輸出長度與自我反思之間的關(guān)系。
長度變化是 RL 動(dòng)態(tài)的一部分
我們使用了支持類 R1-Zero 訓(xùn)練的 oat(一個(gè)研究友好的 LLM 在線對(duì)齊框架),以使用 GRPO 算法在倒計(jì)時(shí)任務(wù)(TinyZero 所用)上對(duì) Qwen-2.5-3B 基礎(chǔ)模型進(jìn)行 RL 調(diào)整。
在該任務(wù)中,模型被賦予三到四個(gè)數(shù)字,并被要求使用算法運(yùn)算(+、-、x、÷)來生成目標(biāo)等式。這樣不可避免地需要模型重試不同的方案,因此需要自我反思行為。
圖 5 右顯示了整個(gè) RL 訓(xùn)練過程中獎(jiǎng)勵(lì)和響應(yīng)長度的動(dòng)態(tài)。與 TinyZero 和 SimpleRL-Zero 類似,我們觀察到獎(jiǎng)勵(lì)持續(xù)增加,而長度先減少然后激增,現(xiàn)有工作將此歸因于頓悟時(shí)刻。然而,我們觀察到重試模式已經(jīng)存在于基礎(chǔ)模型的響應(yīng)中(Section 1),但其中許多都是膚淺的(Section 2 ),因此獎(jiǎng)勵(lì)很低。
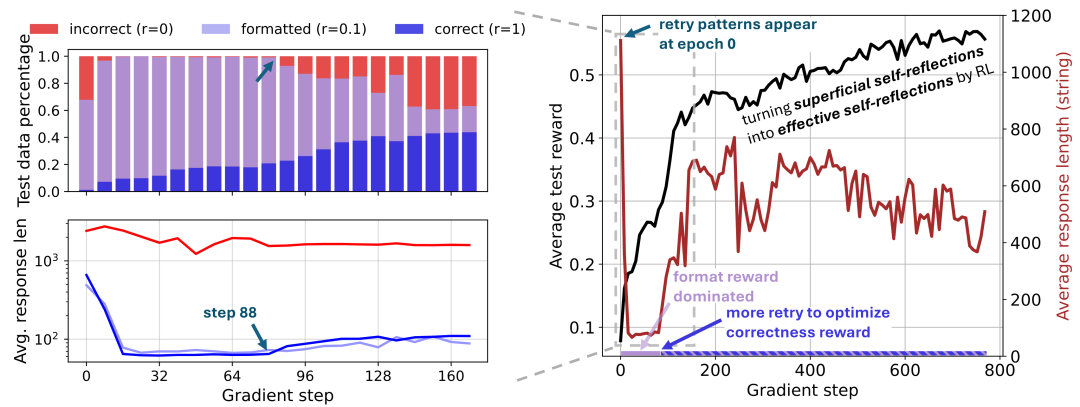
圖 5(左)為不同響應(yīng)組的分布和平均長度的詳細(xì)分析;(右)為測試獎(jiǎng)勵(lì)和模型響應(yīng)長度的 RL 曲線。
在初始學(xué)習(xí)階段,我們分析了基于規(guī)則的獎(jiǎng)勵(lì)塑造對(duì) RL 動(dòng)態(tài)和響應(yīng)長度變化的影響。圖 5(左)根據(jù)獎(jiǎng)勵(lì)將模型響應(yīng)分為了三個(gè)不同的組:

這種簡單的分解揭示了一些關(guān)于 RL 動(dòng)態(tài)的見解:
- 在 88 步之前的訓(xùn)練以塑造獎(jiǎng)勵(lì) (r=0.1) 為主,通過調(diào)整模型使其在生成 token 預(yù)算內(nèi)停止并在 <answer> </answer > 塊內(nèi)格式化答案,從而可以更輕松地進(jìn)行優(yōu)化。在此期間,冗長的錯(cuò)誤響應(yīng)受到抑制,平均響應(yīng)長度急劇下降。
- 在第 88 步,模型開始通過輸出更多重試(retries)來「爬上獎(jiǎng)勵(lì)山」,朝著更高的獎(jiǎng)勵(lì)(r=1 表示正確性)攀登。因此,我們觀察到正確響應(yīng)的長度增加。伴隨而來的副作用是,模型輸出更多冗長的膚淺自我反思,導(dǎo)致平均響應(yīng)長度激增。
- 整個(gè) RL 過程是將原本膚淺的自我反思轉(zhuǎn)變?yōu)橛行У淖晕曳此迹宰畲蠡A(yù)期獎(jiǎng)勵(lì),從而提高推理能力。
輸出長度和自我反思可能并不相關(guān)
按照 SimpleRL-Zero 的設(shè)置,我們使用 8K MATH 提示訓(xùn)練 Qwen2.5-Math-1.5B。在訓(xùn)練開始時(shí),我們觀察到輸出長度減少,直到大約 1700 個(gè)梯度步,長度才開始增加(圖 6)。然而,自我反思關(guān)鍵詞的總數(shù)并沒有表現(xiàn)出圖 7 所示的與輸出長度的單調(diào)關(guān)系。這表明單憑輸出長度可能不是模型自我反思能力的可靠指標(biāo)。
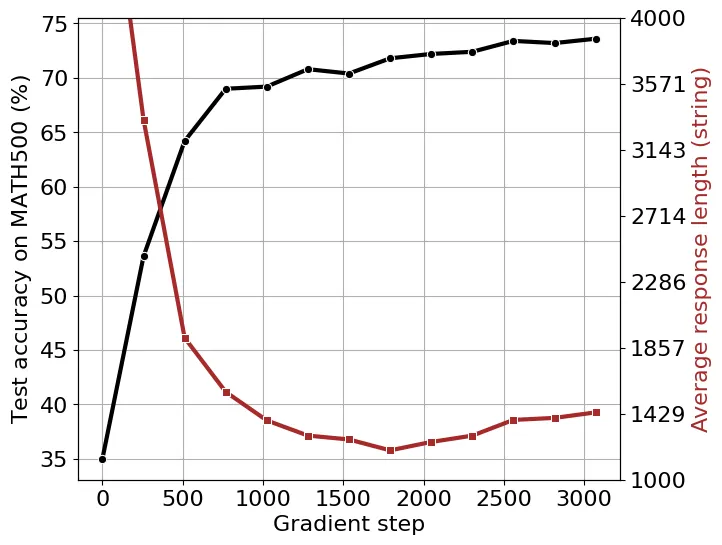
圖 6:使用 8K MATH 提示的 Qwen2.5-Math-1.5B 訓(xùn)練動(dòng)態(tài)。我們報(bào)告了 MATH500 上的測試準(zhǔn)確率和平均響應(yīng)長度。
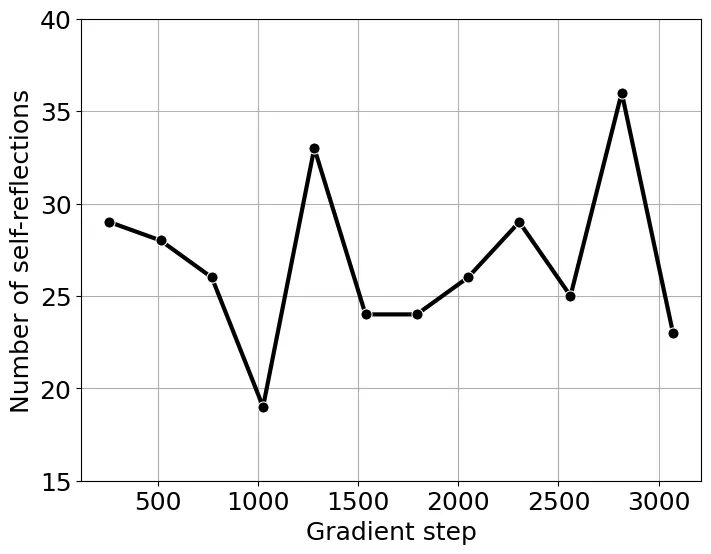
圖 7:訓(xùn)練期間自我反思關(guān)鍵詞的總數(shù)。
在我們使用的單節(jié)點(diǎn)服務(wù)器上,完整訓(xùn)練過程大約需要 14 天,目前仍在進(jìn)行中(進(jìn)度相當(dāng)于 SimpleRL-Zero 中的 48 個(gè)訓(xùn)練步)。我們將在完成后提供更詳細(xì)的分析。

























