機器人感知:探索 Grounded SAM2 的潛力
機器人感知涉及使用攝像頭、激光雷達和雷達等傳感器收集環境數據,算法處理這些數據以解釋周圍環境。這使得機器人能夠檢測物體,并支持狀態估計、定位、導航、控制和規劃等功能,從而執行復雜任務。

在本文中,我們專注于使用攝像頭進行物體檢測和分割。攝像頭捕捉圖像,算法識別這些幀中的物體,提供邊界框和分割掩碼。這些信息通過指示要避開的物體位置和理解哪些區域是可通行的,幫助機器人進行導航。

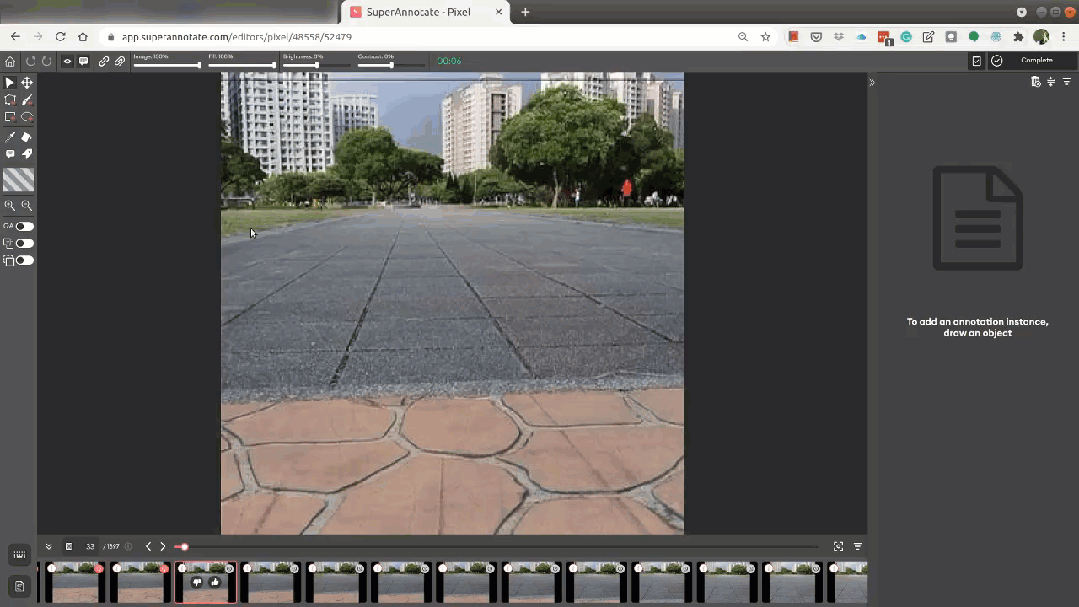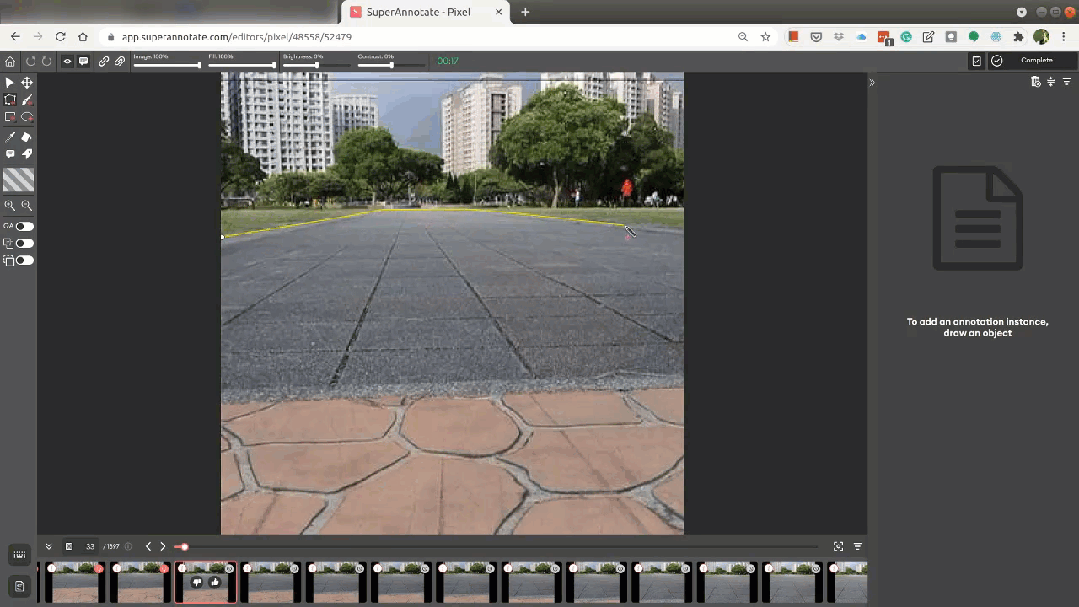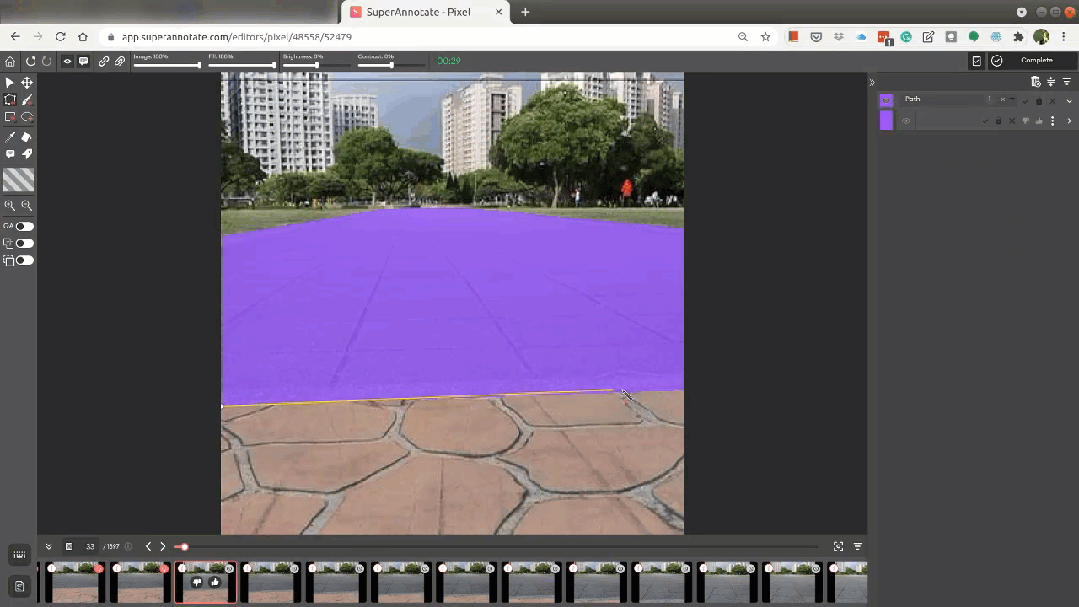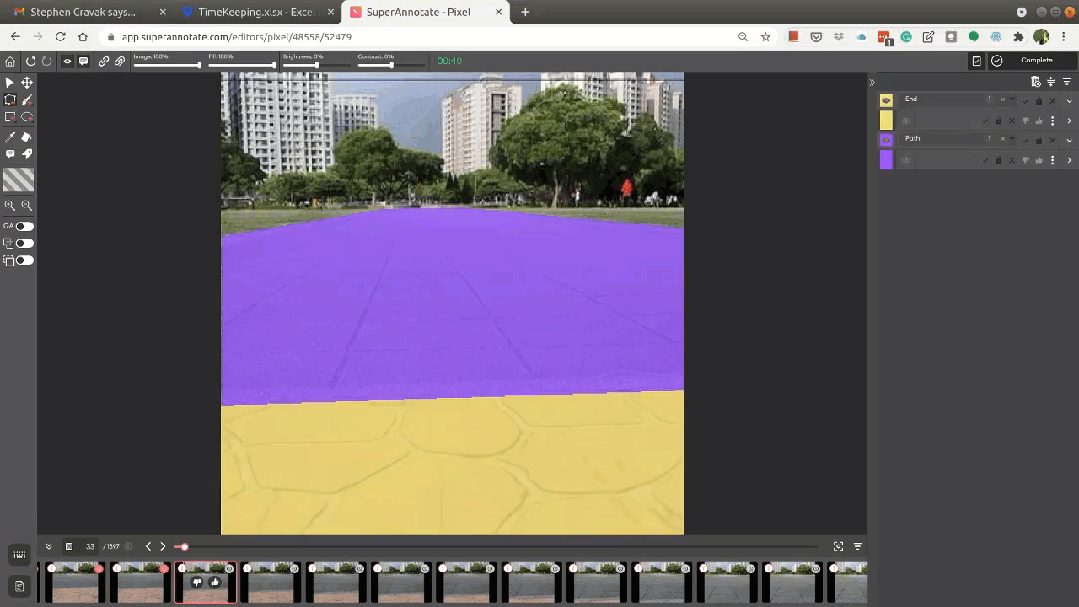
創建手動注釋的可駕駛表面語義分割數據集
在深度學習之前,實現準確的感知是具有挑戰性的,限制了機器人的能力。深度學習的出現改善了基于攝像頭的感知,但需要大量的數據收集、手動注釋和模型重新訓練以識別新物體。視覺語言模型(VLMs)通過將視覺輸入與文本描述相結合,徹底改變了這一領域,實現了開放詞匯物體檢測和分割。VLMs可以識別各種類別的物體,包括訓練期間未遇到的物體,減少了手動數據注釋和模型重新訓練的需求。這一進步顯著增強了機器人理解和與環境交互的能力。
現在讓我們探索VLMs在開放詞匯(OV)物體檢測和分割中的強大功能。我的實驗簡單地旨在確定OV模型是否能夠檢測到我的形狀異常的機器人。

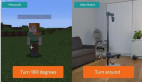
我的機器人SHL-1
我嘗試的第一個OV工具是YOLO-World,這是第一個基于流行的YOLO-v8工具的實時開放詞匯物體檢測模型。與所有其他YOLO模型一樣,YOLO-World非常快。與其他YOLO不同,它可以通過定義新類別來檢測訓練集中未見的物體。在測試我的機器人之前,我測試了一張更受歡迎的機器人圖片,本田的人形機器人Asimo。
# Load model
model = YOLO("yolov8x-worldv2.pt")
# Define custom classes
model.set_classes(["robot"])
# Execute prediction for specified categories on an image
results = model.predict("https://upload.wikimedia.org/wikipedia/commons/0/05/HONDA_ASIMO.jpg")
# Show results
results[0].show()
YOLO-World成功檢測到了人形機器人Asimo
接下來,我用我的機器人SHL-1的圖片嘗試了YOLO-World,但模型無法檢測到形狀異常的機器人。YOLO-World通過實現更簡單的架構實現了即使在CPU上也能實時推理,但代價是無法檢測到更廣泛的分布外物體。
然后,我安裝并測試了Grounded SAM 2【https://github.com/IDEA-Research/Grounded-SAM-2】,這是一個基于Meta流行的Segment Anything Model 2(SAM 2)【https://ai.meta.com/sam2/】的更復雜和更大的VLM。與YOLO-World不同,在YOLO-World中你指定類別名稱,而在Grounded SAM 2中你可以用更復雜的文本進行提示。在我的第一個實驗中,我只使用了提示“robot”來匹配為YOLO-World指定的類別。
# setup the input image and text prompt for SAM 2 and Grounding DINO
# VERY important: text queries need to be lowercased + end with a dot
TEXT_PROMPT = "robot."
IMG_PATH = "robot_almost_back_closer_180/left/left_50.png"
inference(TEXT_PROMPT, IMG_PATH)
Grounded SAM 2可以檢測到SHL-1,但也錯誤地檢測到了附近的滑板車
請注意,與YOLO-World不同,Grounded SAM 2(G-SAM2)還可以執行分割。模型能夠檢測到SHL-1,但也將附近的滑板車誤認為機器人。抱歉,G-SAM2,在我們開發出自主滑板車之前,我們不能將它們視為機器人。
如前所述,G-SAM2可以以類似于我們提示大型語言模型(LLMs)的方式進行提示,盡管短語要短得多。在我的下一個測試中,我使用了提示“6輪機器人”。
TEXT_PROMPT = "6-wheeled robot."
IMG_PATH = "robot_almost_back_closer_180/left/left_50.png"
inference(TEXT_PROMPT, IMG_PATH)
Grounded SAM 2能夠將SHL-1識別為六輪機器人,并正確判斷滑板車沒有六個輪子。
新的提示奏效了。模型對人類語言有足夠的理解,能夠識別出SHL-1是一個機器人并且有六個輪子,而滑板車只有兩個輪子。然而,盡管配備了新提示的G-SAM2可以在其他圖像中一致地檢測到SHL-1,但它有時會錯過帶有激光雷達的支架,如下例所示。
TEXT_PROMPT = "6-wheeled robot."
IMG_PATH = "robot_almost_back_closer_180/left/left_58.png"
inference(TEXT_PROMPT, IMG_PATH)
有時Grounded SAM 2會錯過帶有激光雷達的支架
但不用擔心,有一個提示可以解決這個問題:“帶有激光雷達的六輪機器人。”
TEXT_PROMPT = "6-wheeled robot with mounted LiDAR."
IMG_PATH = "robot_almost_back_closer_180/left/left_58.png"
inference(TEXT_PROMPT, IMG_PATH)
為Grounded SAM 2提供更精確的提示可以提高其性能
在這個簡短的實驗中,我們探索了視覺語言模型的力量,特別是測試了Grounded SAM 2模型。VLMs通過顯著減少擴展機器人能力所需的工作,正在徹底改變機器人感知,從繁瑣的手動數據收集、標注和模型訓練轉向簡單的提示工程。此外,與YOLO-World等較小的模型相比,這些大型模型的能力和準確性顯著提高,盡管代價是需要更多的計算能力。
完整代碼:https://github.com/carlos-argueta/rse_prob_robotics