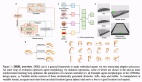
網(wǎng)頁智能體新突破!引入?yún)f(xié)同進(jìn)化世界模型,騰訊AI Lab提出新框架
讓網(wǎng)頁智能體自演進(jìn)突破性能天花板!
騰訊AI Lab提出WebEvolver框架,通過引入協(xié)同進(jìn)化的世界模型(World Model),讓智能體在真實網(wǎng)頁環(huán)境中實現(xiàn)10%的性能提升。
由此突破現(xiàn)有基于大語言模型(LLM)的網(wǎng)頁智能體“自我迭代演進(jìn)的性能最終會停滯”的瓶頸。

下面的案例展示了世界模型在GitHub搜索界面中的合成軌跡生成能力:

研究指出,世界模型具有知識遷移能力,盡管世界模型未專門訓(xùn)練過GitHub中“點擊排序菜單”這類操作,卻能準(zhǔn)確生成GitHub搜索的排序選項(如“最佳匹配”、“最多星標(biāo)”等),這表明LLM內(nèi)建的網(wǎng)頁結(jié)構(gòu)常識知識具有可遷移性。
另外研究還指出世界模型具有多樣化軌跡生成能力,世界模型生成的菜單項與真實網(wǎng)站高度吻合,證明其能有效提升與未見過網(wǎng)站的交互多樣性,這種能力源于LLM預(yù)訓(xùn)練階段吸收的海量網(wǎng)頁知識。
團(tuán)隊認(rèn)為,該發(fā)現(xiàn)驗證了世界模型作為“虛擬網(wǎng)頁引擎”的核心價值——即使存在輕微幻覺,其生成的多樣化軌跡仍能顯著提升Agent的訓(xùn)練效果。
以下是論文詳情。
引入?yún)f(xié)同進(jìn)化的世界模型
最近,世界模型迎來了一波熱潮:Yann Lecun推出了全新的世界模型V-JEPA 2,谷歌也發(fā)布了理論成果,證明General agents need world models,這些進(jìn)展都凸顯了世界模型在智能體發(fā)展中的重要性。
論文指出,當(dāng)前智能體自我迭代的瓶頸源于兩大核心問題:
- 探索局限:隨著訓(xùn)練深入,智能體策略趨于保守,難以發(fā)現(xiàn)新狀態(tài)和動作
- 知識閑置:LLM預(yù)訓(xùn)練時積累的海量網(wǎng)頁知識未被充分激活
就像人類需要想象力來規(guī)劃行動,智能體也可以使用一個’大腦模擬器’來預(yù)演不同操作的結(jié)果。
研究團(tuán)隊創(chuàng)新性地引入了協(xié)同進(jìn)化的世界模型LLM。
在網(wǎng)頁Agent場景中,世界模型被定義為這樣一種LLM:
其輸入為(當(dāng)前網(wǎng)頁觀測、待執(zhí)行的操作),輸出則是執(zhí)行該操作后的網(wǎng)頁觀測。
盡管在此過程中可能會出現(xiàn)“幻覺”問題,例如LLM無法輸出實時信息,或其內(nèi)部存儲的網(wǎng)頁知識可能存在錯誤,但這并不影響整體框架的有效性。因為本文的核心目標(biāo)是讓智能體在多樣化的網(wǎng)站環(huán)境中進(jìn)行穩(wěn)健推理,而非要求世界模型完美預(yù)測下一頁面。
(注:未來研究可聚焦于細(xì)粒度的下一頁面預(yù)測,具體可通過在生成過程中對實時信息進(jìn)行占位符掩碼處理,等待外部工具填充真實數(shù)據(jù)來實現(xiàn)。)

這個世界模型扮演著雙重角色:
1、虛擬服務(wù)器:生成多樣化的合成訓(xùn)練軌跡
通過世界模型模擬與未見網(wǎng)頁的交互。具體操作為,將原本網(wǎng)頁智能體系統(tǒng)中的網(wǎng)頁服務(wù)器直接替換為世界模型LLM來進(jìn)行交互、采集生成的軌跡,作為額外的訓(xùn)練數(shù)據(jù)(圖2上半部分)。
2、想象引擎:推理時多步前瞻推演
使用類似WebDreamer的基于LLM對未來預(yù)測進(jìn)行action篩選的方法,在每一步action生成時生成多個候選,利用世界模型來對每個action未來1~3步的結(jié)果進(jìn)行預(yù)測。使用GPT-4o對候選動作評估潛在收益后執(zhí)行最佳操作(圖2下半部分)。
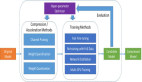
協(xié)同自演進(jìn)實驗技術(shù)方案詳解
本研究構(gòu)建了一個完整的自演進(jìn)學(xué)習(xí)框架,其核心組件包括:
基礎(chǔ)架構(gòu)
- 數(shù)據(jù)集:OpenWebVoyager標(biāo)準(zhǔn)數(shù)據(jù)集(包含48種網(wǎng)站)
- 框架支持:Cognitive Kernel Agent瀏覽器交互環(huán)境
- 基座模型:純文本大模型Llama-3.3(70B參數(shù)版本)
數(shù)據(jù)采集流程
- 采用Cognitive Kernel+Llama-3.3組合進(jìn)行多步軌跡采樣
- 通過”拒絕采樣”機(jī)制篩選成功完成的軌跡
- 保留軌跡中的完整推理鏈(Chain-of-Thought)信息
雙模型協(xié)同訓(xùn)練機(jī)制
- Agent策略模型:學(xué)習(xí)軌跡中的動作決策模式
- 世界模型:重構(gòu)為”當(dāng)前觀察+動作→下一觀察”的預(yù)測任務(wù)
- 兩模型共享采樣數(shù)據(jù)但采用不同訓(xùn)練目標(biāo)函數(shù)
技術(shù)突破點
- 首創(chuàng)將瀏覽器交互軌跡同時用于策略模型和世界模型訓(xùn)練
- 通過軌跡格式轉(zhuǎn)換實現(xiàn)單數(shù)據(jù)源多任務(wù)學(xué)習(xí)
- 建立可擴(kuò)展的自演進(jìn)訓(xùn)練范式(iterative bootstrapping)
重復(fù)多輪(3輪)自演進(jìn)之后,在WebVoyager和Mind2web-live數(shù)據(jù)集上進(jìn)行測試,自演進(jìn)結(jié)果:


結(jié)果:
- 自演進(jìn)baseline在第二輪后增長受限
- 世界模型對突破性能瓶頸的關(guān)鍵作用
- 合成軌跡數(shù)據(jù)有效提升探索多樣性
- 多步前瞻(d=2)達(dá)到最佳性價比
在GAIA和SimpleQA (前100條數(shù)據(jù),和bing.com進(jìn)行交互搜索) 這兩個有標(biāo)準(zhǔn)答案的數(shù)據(jù)上進(jìn)行out-of-domain測試,也能顯著提升結(jié)果。

團(tuán)隊對世界模型的網(wǎng)頁建模能力也進(jìn)行了一些評估,在測試的軌跡里采樣了一些軌跡,讓世界模型根據(jù)上一步觀測和執(zhí)行的action預(yù)測下一步的觀測。

評估標(biāo)準(zhǔn)為:
- 結(jié)構(gòu)正確性(STR):檢驗生成網(wǎng)頁的可訪問性樹在層級結(jié)構(gòu)和元素關(guān)系上是否符合真實網(wǎng)頁的拓?fù)溥壿?/span>
- 內(nèi)容相似度(Sim.):量化生成內(nèi)容與真實網(wǎng)頁在文本語義層面的匹配程度
- 整體功能評估(O/A):綜合判斷生成網(wǎng)頁在交互功能和語義表達(dá)上的可用性
評估重點特別關(guān)注交互元素(按鈕/輸入框等)的功能完整性、動態(tài)內(nèi)容(如搜索結(jié)果)的邏輯合理性、網(wǎng)頁核心功能的可操作性。
該評估體系有效驗證了世界模型對網(wǎng)頁狀態(tài)變化的預(yù)測能力,為模型優(yōu)化提供了量化依據(jù)。發(fā)現(xiàn)世界模型的能力隨著自演進(jìn)的步驟提升而上升。
總之,WebEvolver框架通過世界模型與智能體的協(xié)同進(jìn)化,成功突破傳統(tǒng)自演進(jìn)智能體的性能天花板。該技術(shù)為構(gòu)建持續(xù)進(jìn)化的通用網(wǎng)絡(luò)智能體提供了新范式,為后續(xù)無環(huán)境RL的實現(xiàn)提供引導(dǎo)。
論文網(wǎng)址:https://arxiv.org/pdf/2504.21024
GitHub:https://github.com/Tencent/SelfEvolvingAgent/tree/main/WebEvolver