RAG 結(jié)合了大型語(yǔ)言模型和信息檢索模型的力量,允許它們用從大量文本數(shù)據(jù)中提取的相關(guān)事實(shí)和細(xì)節(jié)來(lái)補(bǔ)充生成的響應(yīng)。事實(shí)證明,這種方法在提高模型輸出的實(shí)際準(zhǔn)確性和總體質(zhì)量方面是有效的。
 圖片
圖片
然而,隨著 RAG 系統(tǒng)得到更廣泛的采用,它們的局限性開(kāi)始浮出水面,具體而言:
- 平面檢索: RAG 將每個(gè)文檔作為一個(gè)獨(dú)立的信息。想象一下,閱讀單獨(dú)的書(shū)頁(yè),卻不知道它們之間是如何連接的。這種方法錯(cuò)過(guò)了不同信息片段之間更深層次的關(guān)系。
- 語(yǔ)境缺陷: 如果不理解關(guān)系和語(yǔ)境,人工智能可能會(huì)提供不連貫的反應(yīng)。這就像有一個(gè)圖書(shū)管理員,他知道在哪里可以找到書(shū),但是卻不知道書(shū)中的故事之間的聯(lián)系。
- 可伸縮性問(wèn)題: 隨著信息量的增長(zhǎng),尋找正確的文檔變得越來(lái)越慢,也越來(lái)越復(fù)雜,就像試圖在不斷擴(kuò)展的庫(kù)中找到一本特定的書(shū)一樣。
也就是說(shuō),對(duì)非結(jié)構(gòu)化文本數(shù)據(jù)的依賴意味著這些模型很難捕捉到處理復(fù)雜查詢所必需的更深層次的語(yǔ)義關(guān)系和上下文細(xì)微差別。此外,為每個(gè)查詢檢索和處理大量文本的計(jì)算成本構(gòu)成了重大挑戰(zhàn)。
1.什么是GraphRAG
GraphRAG 是檢索增強(qiáng)生成領(lǐng)域的一個(gè)重要進(jìn)展。GraphRAG 不使用非結(jié)構(gòu)化的文本,而是利用知識(shí)圖譜的力量ーー實(shí)體的結(jié)構(gòu)化表示、屬性以及它們之間的關(guān)系。通過(guò)以這種結(jié)構(gòu)化的格式表達(dá),GraphRAG 可以克服傳統(tǒng) RAG 方法的局限性。知識(shí)圖譜可以更精確和全面地檢索相關(guān)信息,使模型能夠產(chǎn)生不僅事實(shí)準(zhǔn)確而且與上下文相關(guān)并涵蓋查詢所需方面的答復(fù)。
1.1 GraphRAG中的結(jié)構(gòu)化表達(dá)——知識(shí)圖譜
讓我們來(lái)理解 GraphRAG 如何存儲(chǔ)信息,例如“2型糖尿病是一種擁有屬性高血糖的慢性疾病,可能導(dǎo)致神經(jīng)損傷、腎臟疾病和心血管疾病等并發(fā)癥。”
以下是 GraphRAG 如何在知識(shí)圖譜中表示這些信息:
# 實(shí)體
二型糖尿病(病況)
高血糖水平(癥狀)
神經(jīng)損傷(并發(fā)癥)
腎臟疾病(并發(fā)癥)
心血管疾病(并發(fā)癥)
# 關(guān)系
2型糖尿病-> 有癥狀-> 高血糖水平
2型糖尿病-> 可導(dǎo)致-> 神經(jīng)損傷
2型糖尿病-> 可導(dǎo)致-> 腎臟疾病
2型糖尿病-> 可導(dǎo)致-> 心血管疾病在這個(gè)知識(shí)圖譜中,實(shí)體(節(jié)點(diǎn))表示句子中提到的關(guān)鍵概念,如病況、癥狀和并發(fā)癥。這些關(guān)系(邊)捕捉了這些實(shí)體之間的聯(lián)系,例如,2型糖尿病有高血糖水平的癥狀,并可能導(dǎo)致各種并發(fā)癥。這種結(jié)構(gòu)化的表示允許 GraphRAG 理解句子中的語(yǔ)義關(guān)系和上下文,而不是僅僅將其視為一個(gè)單詞包。當(dāng)用戶問(wèn)一個(gè)與2型糖尿病相關(guān)的問(wèn)題時(shí),比如“2型糖尿病的并發(fā)癥是什么?”,
GraphRAG 可以快速遍歷知識(shí)圖,從“2型糖尿病”實(shí)體開(kāi)始,遵循“可以導(dǎo)致”關(guān)系來(lái)檢索相關(guān)并發(fā)癥(神經(jīng)損傷,腎臟疾病和心血管問(wèn)題)。
1.2 GraphRAG 的主要特性
GraphRAG 已被證明可以顯著提高生成文本的準(zhǔn)確性和相關(guān)性,使其成為一個(gè)有價(jià)值的解決方案,用于準(zhǔn)確、合理的實(shí)時(shí)答案。它還因其通過(guò)跟蹤圖中的關(guān)系鏈來(lái)處理復(fù)雜查詢的能力而受到關(guān)注,提供了對(duì)回答問(wèn)題所需信息的更為豐富的理解。
GraphRAG 的主要特性如下:
- 結(jié)構(gòu)化知識(shí)表示: GraphRAG 使用知識(shí)圖譜來(lái)表示信息、捕獲實(shí)體、關(guān)系和層次結(jié)構(gòu)。
- 上下文檢索: 知識(shí)圖譜使 GraphRAG 能夠理解語(yǔ)義上下文和關(guān)系,允許更全面的檢索。
- 高效處理: 在知識(shí)圖譜中將數(shù)據(jù)預(yù)處理可以降低計(jì)算成本,并且與傳統(tǒng)的 RAG 方法相比,可以更快地檢索。
- 多方面查詢處理: GraphRAG 可以通過(guò)綜合來(lái)自知識(shí)圖譜多個(gè)部分的相關(guān)信息來(lái)處理復(fù)雜的多方面查詢。
- 可解釋性: 與大模型的黑盒輸出相比,GraphRAG 中的結(jié)構(gòu)化知識(shí)表示提供了更高的透明度和可解釋性。
GraphRAG 的這些關(guān)鍵特性展示了它相對(duì)于傳統(tǒng) RAG 模型的優(yōu)勢(shì),以及它在各種應(yīng)用中革新檢索增強(qiáng)生成的潛力。
2.GraphRAG 的應(yīng)用場(chǎng)景
GraphRAG的應(yīng)用場(chǎng)景非常廣泛。下面簡(jiǎn)要介紹 GraphRAG 的兩個(gè)用例,以及它們是如何在每個(gè)用例中使用的。
2.1 醫(yī)療領(lǐng)域
GraphRAG 可以幫助醫(yī)學(xué)專業(yè)人員從大量的醫(yī)學(xué)文獻(xiàn)中快速找到相關(guān)信息,以回答關(guān)于患者癥狀、治療和結(jié)果的復(fù)雜問(wèn)題。通過(guò)將醫(yī)學(xué)知識(shí)表示為一個(gè)結(jié)構(gòu)化的知識(shí)圖譜,GraphRAG 使得多跳推理能夠連接不同的信息并提供全面的答案。這可以導(dǎo)致更快和更準(zhǔn)確的診斷,更知情的治療決定,并改善患者的結(jié)果。
2.2 銀行金融業(yè)
GraphRAG 可以通過(guò)在知識(shí)圖譜中表示客戶交易、賬戶信息和行為模式來(lái)幫助銀行檢測(cè)和防止欺詐。通過(guò)分析圖譜中的關(guān)系和異常,GraphRAG 可以識(shí)別可疑活動(dòng),并向銀行的欺詐檢測(cè)系統(tǒng)發(fā)出警報(bào)。這可以導(dǎo)致更快、更準(zhǔn)確的欺詐檢測(cè),減少財(cái)務(wù)損失,提高客戶對(duì)銀行安全措施的信任。
3.GraphRAG的工作原理
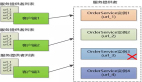
GraphRAG 首先從輸入文檔中提取實(shí)體和關(guān)系,生成知識(shí)圖譜,然后通過(guò)圖算法檢測(cè)社區(qū)結(jié)構(gòu)。接下來(lái),使用 LLM 為每個(gè)社區(qū)生成自然語(yǔ)言摘要,保留分層結(jié)構(gòu)。在用戶查詢時(shí),系統(tǒng)先進(jìn)行局部檢索匹配高級(jí)主題,再進(jìn)行全局檢索獲取詳細(xì)信息,最后由 LLM 生成準(zhǔn)確相關(guān)的響應(yīng)。GraphRAG 的局部搜索針對(duì)特定上下文提供針對(duì)性信息,而全局搜索則利用預(yù)先計(jì)算的社區(qū)摘要,回答跨多個(gè)文檔的綜合查詢。
 圖片
圖片
3.1 知識(shí)圖譜構(gòu)建
- 輸入文檔: GraphRAG 將一組文本文檔作為輸入,比如研究論文、新聞文章或產(chǎn)品描述。
- 實(shí)體和關(guān)系提取: LLM 用于從輸入文檔中自動(dòng)提取實(shí)體(人、地點(diǎn)、概念)以及它們之間的關(guān)系。這是使用命名實(shí)體識(shí)別和關(guān)系提取等復(fù)雜的自然語(yǔ)言處理技術(shù)完成的。
- 知識(shí)圖譜生成: 利用提取的實(shí)體和關(guān)系構(gòu)造知識(shí)圖譜數(shù)據(jù)結(jié)構(gòu)。在知識(shí)圖譜中,實(shí)體表示為節(jié)點(diǎn),它們之間的關(guān)系表示為邊。
- 分層社區(qū)檢測(cè): 采用圖算法檢測(cè)知識(shí)圖譜中密集連接節(jié)點(diǎn)形成的社區(qū)。這些社區(qū)代表了跨越多個(gè)文檔的主題或主題。社區(qū)按等級(jí)組織,高層次社區(qū)包含低層次的子社區(qū)。
3.2 知識(shí)圖譜的信息摘要
- 社區(qū)摘要: 對(duì)于知識(shí)圖譜中檢測(cè)到的每個(gè)社區(qū),使用 LLM 生成自然語(yǔ)言摘要。這些摘要描述了每個(gè)社區(qū)中的關(guān)鍵實(shí)體、關(guān)系和主題。
- 分層摘要: 社區(qū)的分層結(jié)構(gòu)保留在摘要中。高級(jí)摘要描述寬泛的主題,而低級(jí)摘要提供更細(xì)粒度的細(xì)節(jié)。
3.3 檢索增強(qiáng)生成
- 用戶查詢: 用戶向系統(tǒng)提出一個(gè)問(wèn)題或查詢,例如“可再生能源的最新發(fā)展是什么?”
- 局部檢索: 首先將查詢與社區(qū)摘要進(jìn)行匹配,以查找最相關(guān)的高級(jí)主題。這使得系統(tǒng)可以快速縮小搜索空間。
- 全局檢索: 在相關(guān)的高級(jí)社區(qū)中,系統(tǒng)執(zhí)行更詳細(xì)的搜索,以查找回答查詢所需的特定實(shí)體、關(guān)系和信息。這包括了遍歷知識(shí)圖譜和組合來(lái)自多個(gè)社區(qū)的信息。
- 響應(yīng)生成: 使用檢索到的信息,LLM 生成用戶查詢的最終答案。生成的響應(yīng)基于來(lái)自知識(shí)圖譜的結(jié)構(gòu)化知識(shí),確保其事實(shí)上的準(zhǔn)確性和相關(guān)性。
其中,GraphRAG 中的局部搜索是指從特定實(shí)體或文本塊的局部上下文中檢索和使用信息。這涉及到使用知識(shí)圖譜結(jié)構(gòu)來(lái)查找直接連接到當(dāng)前查詢或上下文的相關(guān)實(shí)體、關(guān)系和文本單元。局部搜索允許系統(tǒng)檢索有針對(duì)性的相關(guān)信息,以增強(qiáng)語(yǔ)言模型對(duì)特定的本地化查詢的響應(yīng)。
GraphRAG 中的全局搜索是指利用知識(shí)圖的更廣泛的層次結(jié)構(gòu)對(duì)整個(gè)數(shù)據(jù)集進(jìn)行推理。這涉及到使用檢測(cè)到的“社區(qū)”或圖中相關(guān)實(shí)體和文本單元的集群來(lái)生成完整數(shù)據(jù)集中關(guān)鍵主題和主題的摘要和概述。全局搜索使系統(tǒng)能夠回答需要跨多個(gè)文檔或?qū)嶓w聚合信息的查詢,例如“文檔中最重要的5個(gè)主題是什么?” 通過(guò)利用預(yù)先計(jì)算的社區(qū)摘要,全局搜索可以提供全面的響應(yīng),而無(wú)需為每個(gè)查詢從頭開(kāi)始搜索整個(gè)數(shù)據(jù)集。
4.GraphRAG 的局限
構(gòu)建全面而精確的知識(shí)圖譜不是一個(gè)簡(jiǎn)單的過(guò)程,其質(zhì)量和覆蓋率嚴(yán)重依賴于輸入數(shù)據(jù)源,隨著知識(shí)圖譜的增長(zhǎng),計(jì)算資源的需求也會(huì)增加,對(duì)實(shí)時(shí)應(yīng)用構(gòu)成挑戰(zhàn)。
- 知識(shí)圖譜構(gòu)建復(fù)雜性: 構(gòu)建一個(gè)全面而精確的知識(shí)圖可能是一個(gè)復(fù)雜而耗時(shí)的過(guò)程,需要復(fù)雜的實(shí)體提取和關(guān)系建模技術(shù)。
- 依賴于底層數(shù)據(jù): 知識(shí)圖譜的質(zhì)量和覆蓋率嚴(yán)重依賴于輸入數(shù)據(jù)源。如果底層數(shù)據(jù)不完整或有偏差,則會(huì)限制 GraphRAG 的有效性。
- 可伸縮性挑戰(zhàn): 隨著知識(shí)圖譜的大小和復(fù)雜性的增長(zhǎng),有效的檢索和推理所需的計(jì)算資源可能成為一個(gè)挑戰(zhàn),特別是對(duì)于實(shí)時(shí)應(yīng)用程序。
5.GraphRAG的實(shí)現(xiàn)示例
有很多種方法可以實(shí)現(xiàn)GraphRAG,例如, 采用微軟開(kāi)源的GraphRAG 解決方案。為了簡(jiǎn)化問(wèn)題, 這里給出了兩種參考實(shí)現(xiàn)的示例。
5.1 基于LLMGraphTransformer 的GraphRAG實(shí)現(xiàn)
首先需要 pip 安裝一些必要的庫(kù):
pip install --upgrade --quiet json-repair networkx langchain-core langchain-google-vertexai langchain-experimental langchain-community
#versions used
langchain==0.2.8
langchain-community==0.2.7
langchain-core==0.2.19
langchain-experimental==0.0.62
langchain-google-vertexai==1.0.3當(dāng)然,可以自己選擇不同的大模型來(lái)替換 google 的 verexai。
然后,導(dǎo)入所需的函數(shù),初始化 LLM 對(duì)象和引用文本。使用任何 SOTA LLM 獲得最佳結(jié)果,因?yàn)閯?chuàng)建知識(shí)圖譜是一項(xiàng)復(fù)雜的任務(wù)。
import os
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_google_vertexai import VertexAI
import networkx as nx
from langchain.chains import GraphQAChain
from langchain_core.documents import Document
from langchain_community.graphs.networkx_graph import NetworkxEntityGraph
llm = VertexAI(max_output_tokens=4000,model_name='text-bison-32k')
text = """
your content in details.
"""接下來(lái),我們需要將該文本作為 GraphDocument 加載,并創(chuàng)建 LLMTransformer 對(duì)象。
documents = [Document(page_cnotallow=text)]
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(documents)創(chuàng)建知識(shí)圖譜的時(shí)候,最好提供一個(gè)要提取的實(shí)體和關(guān)系列表,否則LLM可能會(huì)將所有內(nèi)容標(biāo)識(shí)為實(shí)體或關(guān)系。llm_transformer_filtered = LLMGraphTransformer(llm=llm,allowed_nodes=["Person", "Country", "Organization"],allowed_relatinotallow=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"],)graph_documents_filtered = llm_transformer_filtered.convert_to_graph_documents(documents)
我們可以使用 Networkx Graph 工具包將上面標(biāo)識(shí)的節(jié)點(diǎn)和邊進(jìn)行可視化,當(dāng)然生產(chǎn)環(huán)境中一般會(huì)存入圖數(shù)據(jù)庫(kù)。
graph = NetworkxEntityGraph()
# 增加節(jié)點(diǎn)
for node in graph_documents_filtered[0].nodes:
graph.add_node(node.id)
# 增加邊
for edge in graph_documents_filtered[0].relationships:
graph._graph.add_edge(
edge.source.id,
edge.target.id,
relatinotallow=edge.type,
)現(xiàn)在,我們可以創(chuàng)建一個(gè) GraphQAChain,它將幫助我們與知識(shí)庫(kù)進(jìn)行交互。
chain = GraphQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True
)最后,就可以使用Query 調(diào)用 chain 的對(duì)象了。question = """my question xxxx"""chain.run(question)
5.2 基于GraphIndexCreator 的GraphRAG實(shí)現(xiàn)
在 LangChain 使用 GraphIndexCreator,它與上述方法非常相似。
from langchain.indexes import GraphIndexCreator
from langchain.chains import GraphQAChain
index_creator = GraphIndexCreator(llm=llm)
with open("/home/abel/sample.txt") as f:
all_text = f.read()
text = "\n".join(all_text.split("\n\n"))
graph = index_creator.from_text(text)
chain = GraphQAChain.from_llm(llm, graph=graph, verbose=True)
chain.run("my question xxxx ?")兩種方法都很容易實(shí)現(xiàn)。這些示例使用非常小的數(shù)據(jù)集。如果您使用大型數(shù)據(jù)集,知識(shí)圖譜的創(chuàng)建可能會(huì)導(dǎo)致大量token 成本。
5.3 知識(shí)圖譜作為檢索工具
特殊地,使用知識(shí)圖譜作為 RAG 的檢索部分有三種方法:
- 基于向量的檢索: 向量化知識(shí)圖譜并將其存儲(chǔ)在向量數(shù)據(jù)庫(kù)中。然后對(duì)提示詞進(jìn)行向量化,則可以在向量數(shù)據(jù)庫(kù)中找到與提示符最相似的向量。由于這些向量對(duì)應(yīng)于圖中的實(shí)體,因此可以在給定自然語(yǔ)言提示詞的情況下返回圖中最“相關(guān)”的實(shí)體。注意,可以在沒(méi)有知識(shí)圖譜的情況下進(jìn)行基于向量的檢索。這實(shí)際上是 RAG 最初的實(shí)現(xiàn)方式,有時(shí)稱為基本RAG。您將向量化 SQL 數(shù)據(jù)庫(kù)或內(nèi)容,并在查詢時(shí)檢索它。
- 提示詞查詢檢索: 使用 LLM 編寫(xiě) SPARQL 或 Cypher 查詢,使用對(duì)知識(shí)圖譜的查詢,然后使用返回的結(jié)果來(lái)增強(qiáng)提示詞。
- 混合方式(Vector + SPARQL) : 可以以各種有趣的方式組合以上這兩種方法。
總之,有很多方法可以將矢量數(shù)據(jù)庫(kù)和知識(shí)圖譜結(jié)合起來(lái)用于搜索、相似性和 RAG。
6.小結(jié)
GraphRAG 代表了檢索增強(qiáng)生成領(lǐng)域的一項(xiàng)重要進(jìn)步。通過(guò)利用知識(shí)圖譜的力量,GraphRAG克服了傳統(tǒng)RAG模型的局限性,為復(fù)雜查詢提供更準(zhǔn)確、相關(guān)和全面的響應(yīng)。
在GraphRAG中,結(jié)構(gòu)化的知識(shí)表示使系統(tǒng)能夠理解不同信息片段之間的語(yǔ)義上下文和關(guān)系,從而輕松處理復(fù)雜的多主題查詢。此外,GraphRAG的高效處理能力使其成為實(shí)際應(yīng)用程序中的實(shí)用解決方案,特別是在速度和準(zhǔn)確性至關(guān)重要的場(chǎng)景中。
GraphRAG已在各個(gè)領(lǐng)域被證明是有效的,包括醫(yī)療保健和銀行業(yè),能夠提供有價(jià)值的見(jiàn)解并支持決策過(guò)程。其不斷學(xué)習(xí)和擴(kuò)展知識(shí)的能力,使其成為一個(gè)多功能工具,能夠適應(yīng)新的信息和不斷變化的領(lǐng)域。