













微軟開源的GraphRAG爆火,Github Star量破萬(wàn),生成式AI進(jìn)入知識(shí)圖譜時(shí)代?
LLM 很強(qiáng)大,但也存在一些明顯缺點(diǎn),比如幻覺(jué)問(wèn)題、可解釋性差、抓不住問(wèn)題重點(diǎn)、隱私和安全問(wèn)題等。檢索增強(qiáng)式生成(RAG)可大幅提升 LLM 的生成質(zhì)量和結(jié)果有用性。
本月初,微軟發(fā)布最強(qiáng) RAG 知識(shí)庫(kù)開源方案 GraphRAG,項(xiàng)目上線即爆火,現(xiàn)在星標(biāo)量已經(jīng)達(dá)到 10.5 k。

- 項(xiàng)目地址:https://github.com/microsoft/graphrag
- 官方文檔:https://microsoft.github.io/graphrag/
有人表示,它比普通的 RAG 更強(qiáng)大:

GraphRAG 使用 LLM 生成知識(shí)圖譜,在對(duì)復(fù)雜信息進(jìn)行文檔分析時(shí)可顯著提高問(wèn)答性能,尤其是在處理私有數(shù)據(jù)時(shí)。

GraphRAG 和傳統(tǒng) RAG 對(duì)比結(jié)果
現(xiàn)如今,RAG 是一種使用真實(shí)世界信息改進(jìn) LLM 輸出的技術(shù),是大多數(shù)基于 LLM 的工具的重要組成部分,一般而言,RAG 使用向量相似性作為搜索,稱之為 Baseline RAG(基準(zhǔn)RAG)。但 Baseline RAG 在某些情況下表現(xiàn)并不完美。例如:
- Baseline RAG 難以將各個(gè)點(diǎn)連接起來(lái)。當(dāng)回答問(wèn)題需要通過(guò)共享屬性遍歷不同的信息片段以提供新的綜合見(jiàn)解時(shí),就會(huì)發(fā)生這種情況;
- 當(dāng)被要求全面理解大型數(shù)據(jù)集甚至單個(gè)大型文檔中的總結(jié)語(yǔ)義概念時(shí),Baseline RAG 表現(xiàn)不佳。
微軟提出的 GraphRAG 利用 LLM 根據(jù)輸入的文本庫(kù)創(chuàng)建一個(gè)知識(shí)圖譜。這個(gè)圖譜結(jié)合社區(qū)摘要和圖機(jī)器學(xué)習(xí)的輸出,在查詢時(shí)增強(qiáng)提示。GraphRAG 在回答上述兩類問(wèn)題時(shí)顯示出顯著的改進(jìn),展現(xiàn)了在處理私有數(shù)據(jù)集上超越以往方法的性能。
不過(guò),隨著大家對(duì) GraphRAG 的深入了解,他們發(fā)現(xiàn)其原理和內(nèi)容真的讓人很難理解。

近日,Neo4j 公司 CTO Philip Rathle 發(fā)布了一篇標(biāo)題為《GraphRAG 宣言:將知識(shí)加入到生成式 AI 中》的博客文章,Rathle 用通俗易懂的語(yǔ)言詳細(xì)介紹了 GraphRAG 的原理、與傳統(tǒng) RAG 的區(qū)別、GraphRAG 的優(yōu)勢(shì)等。
他表示:「你的下一個(gè)生成式 AI 應(yīng)用很可能就會(huì)用上知識(shí)圖譜。」

Neo4j CTO Philip Rathle
下面來(lái)看這篇文章。
我們正在逐漸認(rèn)識(shí)到這一點(diǎn):要使用生成式 AI 做一些真正有意義的事情,你就不能只依靠自回歸 LLM 來(lái)幫你做決定。
我知道你在想什么:「用 RAG 呀。」或者微調(diào),又或者等待 GPT-5。
是的。基于向量的檢索增強(qiáng)式生成(RAG)和微調(diào)等技術(shù)能幫到你。而且它們也確實(shí)能足夠好地解決某些用例。但有一類用例卻會(huì)讓所有這些技術(shù)折戟沉沙。
針對(duì)很多問(wèn)題,基于向量的 RAG(以及微調(diào))的解決方法本質(zhì)上就是增大正確答案的概率。但是這兩種技術(shù)都無(wú)法提供正確答案的確定程度。它們通常缺乏背景信息,難以與你已經(jīng)知道的東西建立聯(lián)系。此外,這些工具也不會(huì)提供線索讓你了解特定決策的原因。
讓我們把視線轉(zhuǎn)回 2012 年,那時(shí)候谷歌推出了自己的第二代搜索引擎,并發(fā)布了一篇標(biāo)志性的博客文章《Introducing the Knowledge Graph: things, not strings》。他們發(fā)現(xiàn),如果在執(zhí)行各種字符串處理之外再使用知識(shí)圖譜來(lái)組織所有網(wǎng)頁(yè)中用字符串表示的事物,那么有可能為搜索帶來(lái)飛躍式的提升。
現(xiàn)在,生成式 AI 領(lǐng)域也出現(xiàn)了類似的模式。很多生成式 AI 項(xiàng)目都遇到了瓶頸,其生成結(jié)果的質(zhì)量受限于這一事實(shí):解決方案處理的是字符串,而非事物。
快進(jìn)到今天,前沿的 AI 工程師和學(xué)術(shù)研究者們重新發(fā)現(xiàn)了谷歌曾經(jīng)的發(fā)現(xiàn):打破這道瓶頸的秘訣就是知識(shí)圖譜。換句話說(shuō),就是將有關(guān)事物的知識(shí)引入到基于統(tǒng)計(jì)的文本技術(shù)中。其工作方式就類似于其它 RAG,只不過(guò)除了向量索引外還要調(diào)用知識(shí)圖譜。也就是:GraphRAG!(GraphRAG = 知識(shí)圖譜 + RAG)
本文的目標(biāo)是全面且易懂地介紹 GraphRAG。研究表明,如果將你的數(shù)據(jù)構(gòu)建成知識(shí)圖譜并通過(guò) RAG 來(lái)使用它,就能為你帶來(lái)多種強(qiáng)勁優(yōu)勢(shì)。有大量研究證明,相比于僅使用普通向量的 RAG,GraphRAG 能更好地回答你向 LLM 提出的大部分乃至全部問(wèn)題。
單這一項(xiàng)優(yōu)勢(shì),就足以極大地推動(dòng)人們采用 GraphRAG 了。
但還不止于此;由于在構(gòu)建應(yīng)用時(shí)數(shù)據(jù)是可見(jiàn)的,因此其開發(fā)起來(lái)也更簡(jiǎn)單。
GraphRAG 的第三個(gè)優(yōu)勢(shì)是人類和機(jī)器都能很好地理解圖譜并基于其執(zhí)行推理。因此,使用 GraphRAG 構(gòu)建應(yīng)用會(huì)更簡(jiǎn)單輕松,并得到更好的結(jié)果,同時(shí)還更便于解釋和審計(jì)(這對(duì)很多行業(yè)來(lái)說(shuō)至關(guān)重要)。
我相信 GraphRAG 將取代僅向量 RAG,成為大多數(shù)用例的默認(rèn) RAG 架構(gòu)。本文將解釋原因。
圖譜是什么?
首先我們必須闡明什么是圖譜。
圖譜,也就是 graph,也常被譯為「圖」,但也因此容易與 image 和 picture 等概念混淆。本文為方便區(qū)分,僅采用「圖譜」這一譯法。
圖譜大概長(zhǎng)這樣:

圖譜示例
盡管這張圖常作為知識(shí)圖譜的示例,但其出處和作者已經(jīng)不可考。
或這樣:

《權(quán)力的游戲》人物關(guān)系圖譜,來(lái)自 William Lyon
或這樣:

倫敦地鐵地圖。有趣小知識(shí):倫敦交通局前段時(shí)間部署了一個(gè)基于圖譜的數(shù)字孿生應(yīng)用,以提升事故響應(yīng)能力并減少擁堵。
換句話說(shuō),圖譜不是圖表。
這里我們就不過(guò)多糾結(jié)于定義問(wèn)題,就假設(shè)你已經(jīng)明白圖譜是什么了。
如果你理解上面幾張圖片,那么你也許能看出來(lái)可以如何查詢其底層的知識(shí)圖譜數(shù)據(jù)(存儲(chǔ)在圖譜數(shù)據(jù)庫(kù)中),并將其用作 RAG 工作流程的一部分。也就是 GraphRAG。
兩種呈現(xiàn)知識(shí)的形式:向量和圖譜
典型 RAG 的核心是向量搜索,也就是根據(jù)輸入的文本塊從候選的書面材料中找到并返回概念相似的文本。這種自動(dòng)化很好用,基本的搜索都大有用途。
但你每次執(zhí)行搜索時(shí),可能并未思考過(guò)向量是什么或者相似度計(jì)算是怎么實(shí)現(xiàn)的。下面我們來(lái)看看 Apple(蘋果)。它在人類視角、向量視角和圖譜視角下呈現(xiàn)出了不同的形式:

人類視角、向量視角和圖譜視角下的 Apple
在人類看來(lái),蘋果的表征很復(fù)雜并且是多維度的,其特征無(wú)法被完整地描述到紙面上。這里我們可以充滿詩(shī)意地想象這張紅彤彤的照片能夠在感知和概念上表示一個(gè)蘋果。
這個(gè)蘋果的向量表示是一個(gè)數(shù)組。向量的神奇之處在于它們各自以編碼形式捕獲了其對(duì)應(yīng)文本的本質(zhì)。但在 RAG 語(yǔ)境中,只有當(dāng)你需要確定一段文本與另一段文本的相似度時(shí),才需要向量。為此,只需簡(jiǎn)單地執(zhí)行相似度計(jì)算并檢查匹配程度。但是,如果你想理解向量?jī)?nèi)部的含義、了解文本中表示的事物、洞察其與更大規(guī)模語(yǔ)境的關(guān)系,那使用向量表示法就無(wú)能為力了。
相較之下,知識(shí)圖譜是以陳述式(declarative)的形式來(lái)表示世界 —— 用 AI 領(lǐng)域的術(shù)語(yǔ)來(lái)說(shuō),也就是符號(hào)式(symbolic)。因此,人類和機(jī)器都可以理解知識(shí)圖譜并基于其執(zhí)行推理。這很重要,我們后面還會(huì)提到。
此外,你還可以查詢、可視化、標(biāo)注、修改和延展知識(shí)圖譜。知識(shí)圖譜就是世界模型,能表示你當(dāng)前工作領(lǐng)域的世界。
GraphRAG 與 RAG
這兩者并不是競(jìng)爭(zhēng)關(guān)系。對(duì) RAG 來(lái)說(shuō),向量查詢和圖譜查詢都很有用。正如 LlamaIndex 的創(chuàng)始人 Jerry Liu 指出的那樣:思考 GraphRAG 時(shí),將向量囊括進(jìn)來(lái)會(huì)很有幫助。這不同于「僅向量 RAG」—— 完全基于文本嵌入之間的相似度。
根本上講,GraphRAG 就是一種 RAG,只是其檢索路徑包含知識(shí)圖譜。下面你會(huì)看到,GraphRAG 的核心模式非常簡(jiǎn)單。其架構(gòu)與使用向量的 RAG 一樣,但其中包含知識(shí)圖譜層。
GraphRAG 模式
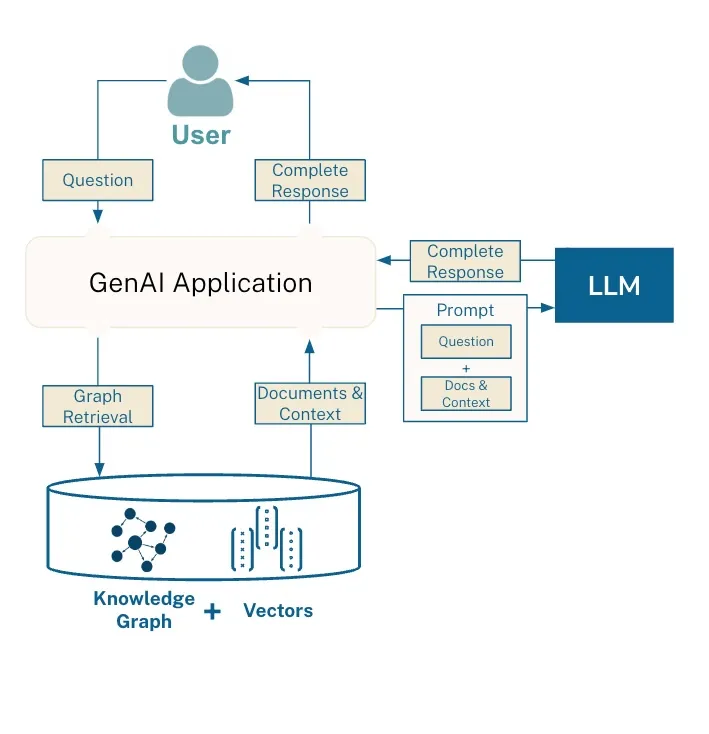
GraphRAG 的一種常用模式
可以看到,上圖中觸發(fā)了一次圖譜查詢。其可以選擇是否包含向量相似度組件。你可以選擇將圖譜和向量分開存儲(chǔ)在兩個(gè)不同的數(shù)據(jù)庫(kù)中,也可使用 Neo4j 等支持向量搜索的圖譜數(shù)據(jù)庫(kù)。
下面給出了一種使用 GraphRAG 的常用模式:
1. 執(zhí)行一次向量搜索或關(guān)鍵詞搜索,找到一組初始節(jié)點(diǎn);
2. 遍歷圖譜,帶回相關(guān)節(jié)點(diǎn)的信息;
3.(可選)使用 PageRank 等基于圖譜的排名算法對(duì)文檔進(jìn)行重新排名
用例不同,使用模式也會(huì)不一樣。和當(dāng)今 AI 領(lǐng)域的各個(gè)研究方向一樣,GraphRAG 也是一個(gè)研究豐富的領(lǐng)域,每周都有新發(fā)現(xiàn)涌現(xiàn)。
GraphRAG 的生命周期
使用 GraphRAG 的生成式 AI 也遵循其它任意 RAG 應(yīng)用的模式,一開始有一個(gè)「創(chuàng)建圖譜」步驟:

GraphRAG 的生命周期
創(chuàng)建圖譜類似于對(duì)文檔進(jìn)行分塊并將其加載到向量數(shù)據(jù)庫(kù)中。工具的發(fā)展進(jìn)步已經(jīng)讓圖譜創(chuàng)建變得相當(dāng)簡(jiǎn)單。這里有三個(gè)好消息:
1. 圖譜有很好的迭代性 —— 你可以從一個(gè)「最小可行圖譜」開始,然后基于其進(jìn)行延展。
2. 一旦將數(shù)據(jù)加入到了知識(shí)圖譜中,就能很輕松地演進(jìn)它。你可以添加更多類型的數(shù)據(jù),從而獲得并利用數(shù)據(jù)網(wǎng)絡(luò)效應(yīng)。你還可以提高數(shù)據(jù)的質(zhì)量,以提升應(yīng)用的價(jià)值。
3. 該領(lǐng)域發(fā)展迅速,這就意味著隨著工具愈發(fā)復(fù)雜精妙,圖譜創(chuàng)建只會(huì)越來(lái)越容易輕松。
在之前的圖片中加入圖譜創(chuàng)建步驟,可以得到如下所示的工作流程:

添加圖譜創(chuàng)建步驟
下面來(lái)看看 GraphRAG 能帶來(lái)什么好處。
為什么要使用 GraphRAG?
相較于僅向量 RAG,GraphRAG 的優(yōu)勢(shì)主要分為三大類:
1. 準(zhǔn)確度更高且答案更完整(運(yùn)行時(shí)間 / 生產(chǎn)優(yōu)勢(shì))
2. 一旦創(chuàng)建好知識(shí)圖譜,那么構(gòu)建和維護(hù) RAG 應(yīng)用都會(huì)更容易(開發(fā)時(shí)間優(yōu)勢(shì))
3. 可解釋性、可追溯性和訪問(wèn)控制方面都更好(治理優(yōu)勢(shì))
下面深入介紹這些優(yōu)勢(shì)。
1. 準(zhǔn)確度更高且答案更有用
GraphRAG 的第一個(gè)優(yōu)勢(shì)(也是最直接可見(jiàn)的優(yōu)勢(shì))是其響應(yīng)質(zhì)量更高。不管是學(xué)術(shù)界還是產(chǎn)業(yè)界,我們都能看到很多證據(jù)支持這一觀察。
比如這個(gè)來(lái)自數(shù)據(jù)目錄公司 Data.world 的示例。2023 年底,他們發(fā)布了一份研究報(bào)告,表明在 43 個(gè)業(yè)務(wù)問(wèn)題上,GraphRAG 可將 LLM 響應(yīng)的準(zhǔn)確度平均提升 3 倍。這項(xiàng)基準(zhǔn)評(píng)測(cè)研究給出了知識(shí)圖譜能大幅提升響應(yīng)準(zhǔn)確度的證據(jù)。

知識(shí)圖譜將 LLM 響應(yīng)的準(zhǔn)確度提升了 54.2 個(gè)百分點(diǎn),也就是大約提升了 3 倍
微軟也給出了一系列證據(jù),包括 2024 年 2 月的一篇研究博客《GraphRAG: Unlocking LLM discovery on narrative private data》以及相關(guān)的研究論文《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》和軟件:https://github.com/microsoft/graphrag(即上文開篇提到的 GraphRAG)。
其中,他們觀察到使用向量的基線 RAG 存在以下兩個(gè)問(wèn)題:
- 基線 RAG 難以將點(diǎn)連接起來(lái)。為了綜合不同的信息來(lái)獲得新見(jiàn)解,需要通過(guò)共享屬性遍歷不同的信息片段,這時(shí)候,基線 RAG 就難以將不同的信息片段連接起來(lái)。
- 當(dāng)被要求全面理解在大型數(shù)據(jù)集合甚至單個(gè)大型文檔上歸納總結(jié)的語(yǔ)義概念時(shí),基線 RAG 表現(xiàn)不佳。
微軟發(fā)現(xiàn):「通過(guò)使用 LLM 生成的知識(shí)圖譜,GraphRAG 可以大幅提升 RAG 的「檢索」部分,為上下文窗口填入相關(guān)性更高的內(nèi)容,從而得到更好的答案并獲取證據(jù)來(lái)源。」他們還發(fā)現(xiàn),相比于其它替代方法,GraphRAG 所需的 token 數(shù)量可以少 26% 到 97%,因此其不僅能給出更好的答案,而且成本更低,擴(kuò)展性也更好。
進(jìn)一步深入準(zhǔn)確度方面,我們知道答案正確固然重要,但答案也要有用才行。人們發(fā)現(xiàn),GraphRAG 不僅能讓答案更準(zhǔn)確,而且還能讓答案更豐富、更完整、更有用。
領(lǐng)英近期的論文《Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering》就是一個(gè)出色的范例,其中描述了 GraphRAG 對(duì)其客戶服務(wù)應(yīng)用的影響。GraphRAG 提升了其客戶服務(wù)答案的正確性和豐富度,也因此讓答案更加有用,還讓其客戶服務(wù)團(tuán)隊(duì)解決每個(gè)問(wèn)題的時(shí)間中位數(shù)降低了 28.6%。
Neo4j 的生成式 AI 研討會(huì)也有一個(gè)類似的例子。如下所示,這是針對(duì)一組 SEC 備案文件,「向量 + GraphRAG」與「僅向量」方法得到的答案:

「僅向量」與「向量 + GraphRAG」方法對(duì)比
請(qǐng)注意「描述可能受鋰短缺影響的公司的特征」與「列出可能受影響的具體公司」之間的區(qū)別。如果你是一位想要根據(jù)市場(chǎng)變化重新平衡投資組合的投資者,或一家想要根據(jù)自然災(zāi)害重新調(diào)整供應(yīng)鏈的公司,那么上圖右側(cè)的信息肯定比左側(cè)的重要得多。這里,這兩個(gè)答案都是準(zhǔn)確的。但右側(cè)答案明顯更有用。
Jesus Barrasa 的《Going Meta》節(jié)目第 23 期給出了另一個(gè)絕佳示例:從詞匯圖譜開始使用法律文件。
我們也時(shí)不時(shí)會(huì)看到來(lái)自學(xué)術(shù)界和產(chǎn)業(yè)界的新示例。比如 Lettria 的 Charles Borderie 就給出了一個(gè)「僅向量」與「向量 + GraphRAG」方法的對(duì)比示例;其中 GraphRAG 依托于一個(gè)基于 LLM 的文本到圖譜工作流程,將 10,000 篇金融文章整理成了一個(gè)知識(shí)圖譜:

僅檢索器方法與圖檢索器方法的對(duì)比
可以看到,相比于使用普通 RAG,使用 GraphRAG 不僅能提升答案的質(zhì)量,并且其答案的 token 數(shù)量也少了三分之一。
再舉一個(gè)來(lái)自 Writer 的例子。他們最近發(fā)布了一份基于 RobustQA 框架的 RAG 基準(zhǔn)評(píng)測(cè)報(bào)告,其中對(duì)比了他們的基于 GraphRAG 的方法與其它同類工具。GraphRAG 得到的分?jǐn)?shù)是 86%,明顯優(yōu)于其它方法(在 33% 到 76% 之間),同時(shí)還有相近或更好的延遲性能。

RAG 方法的準(zhǔn)確度和響應(yīng)時(shí)間評(píng)估結(jié)果
GraphRAG 正在給多種多樣的生成式 AI 應(yīng)用帶去助益。知識(shí)圖譜打開了讓生成式 AI 的結(jié)果更準(zhǔn)確和更有用的道路。
2. 數(shù)據(jù)理解得到提升,迭代速度更快
不管是概念上還是視覺(jué)上,知識(shí)圖譜都很直觀。探索知識(shí)圖譜往往能帶來(lái)新的見(jiàn)解。
很多知識(shí)圖譜用戶都分享了這樣的意外收獲:一旦投入心力完成了自己的知識(shí)圖譜,那么它就能以一種意想不到的方式幫助他們構(gòu)建和調(diào)試自己的生成式 AI 應(yīng)用。部分原因是如果能以圖譜的形式看待數(shù)據(jù),那便能看到這些應(yīng)用底層的數(shù)據(jù)呈現(xiàn)出了一副生動(dòng)的數(shù)據(jù)圖景。
圖譜能讓你追溯答案,找到數(shù)據(jù),并一路追溯其因果鏈。
我們來(lái)看看上面有關(guān)鋰短缺的例子。如果你可視化其向量,那么你會(huì)得到類似下圖的結(jié)果,只不過(guò)行列數(shù)量都更多。

向量可視化
而如果將數(shù)據(jù)轉(zhuǎn)換成圖譜,則你能以一種向量表示做不到的方式來(lái)理解它。
以下是 LlamaIndex 最近的網(wǎng)絡(luò)研討會(huì)上的一個(gè)例子,展示了他們使用「MENTIONS(提及)」關(guān)系提取向量化詞塊(詞匯圖譜)和 LLM 提取實(shí)體(領(lǐng)域圖譜)的圖譜并將兩者聯(lián)系起來(lái)的能力:

提取詞匯圖譜和領(lǐng)域圖譜
(也有很多使用 Langchain、Haystack 和 SpringAI 等工具的例子。)
你可以看到此圖中數(shù)據(jù)的豐富結(jié)構(gòu),也能想象其所能帶來(lái)的新的開發(fā)和調(diào)試可能性。其中,各個(gè)數(shù)據(jù)都有各自的值,而結(jié)構(gòu)本身也存儲(chǔ)和傳達(dá)了額外的含義,你可將其用于提升應(yīng)用的智能水平。
這不僅是可視化。這也是讓你的數(shù)據(jù)結(jié)構(gòu)能傳達(dá)和存儲(chǔ)意義。下面是一位來(lái)自一家著名金融科技公司的開發(fā)者的反應(yīng),當(dāng)時(shí)他們剛把知識(shí)圖譜引入 RAG 工作流程一周時(shí)間:

開發(fā)者對(duì) GraphRAG 的反應(yīng)
這位開發(fā)者的反應(yīng)非常符合「測(cè)試驅(qū)動(dòng)的開發(fā)」假設(shè),即驗(yàn)證(而非信任)答案是否正確。就我個(gè)人而言,如果讓我百分之百地將自主權(quán)交給決策完全不透明的 AI,我會(huì)感到毛骨悚然。更具體而言,就算你不是一個(gè) AI 末日論者,你也會(huì)同意:如果能不將與「Apple, Inc.」有關(guān)的詞塊或文檔映射到「Apple Corps」(這是兩家完全不一樣的公司),確實(shí)會(huì)大有價(jià)值。由于推動(dòng)生成式 AI 決策的最終還是數(shù)據(jù),因此可以說(shuō)評(píng)估和確保數(shù)據(jù)正確性才是最至關(guān)重要的。
3. 治理:可解釋性、安全及更多
生成式 AI 決策的影響越大,你就越需要說(shuō)服在決策出錯(cuò)時(shí)需要最終負(fù)責(zé)的人。這通常涉及到審計(jì)每個(gè)決策。這就需要可靠且重復(fù)的優(yōu)良決策記錄。但這還不夠。在采納或放棄一個(gè)決策時(shí),你還需要解釋其背后的原因。
LLM 本身沒(méi)法很好地做到這一點(diǎn)。是的,你可以參考用于得到該決策的文檔。但這些文檔并不能解釋這個(gè)決策本身 —— 更別說(shuō) LLM 還會(huì)編造參考來(lái)源。知識(shí)圖譜則完全在另一個(gè)層面上,能讓生成式 AI 的推理邏輯更加明晰,也更容易解釋輸入。
繼續(xù)來(lái)看上面的一個(gè)例子:Lettria 的 Charles 將從 10,000 篇金融文章提取出的實(shí)體載入到了一個(gè)知識(shí)圖譜中,并搭配一個(gè) LLM 來(lái)執(zhí)行 GraphRAG。我們看到這確實(shí)能提供更好的答案。我們來(lái)看看這些數(shù)據(jù):

將從 10,000 篇金融文章提取出的實(shí)體載入知識(shí)圖譜
首先,將數(shù)據(jù)看作圖譜。另外,我們也可以導(dǎo)覽和查詢這些數(shù)據(jù),還能隨時(shí)修正和更新它們。其治理優(yōu)勢(shì)在于:查看和審計(jì)這些數(shù)據(jù)的「世界模型」變得簡(jiǎn)單了很多。相較于使用同一數(shù)據(jù)的向量版本,使用圖譜讓最終負(fù)責(zé)人更可能理解決策背后的原因。
在確保質(zhì)量方面,如果能將數(shù)據(jù)放在知識(shí)圖譜中,則就能更輕松地找到其中的錯(cuò)誤和意外并且追溯它們的源頭。你還能在圖譜中獲取來(lái)源和置信度信息,然后將其用于計(jì)算以及解釋。而使用同樣數(shù)據(jù)的僅向量版本根本就無(wú)法做到這一點(diǎn),正如我們之前討論的那樣,一般人(甚至不一般的人)都很難理解向量化的數(shù)據(jù)。
知識(shí)圖譜還可以顯著增強(qiáng)安全性和隱私性。
在構(gòu)建原型設(shè)計(jì)時(shí),安全性和隱私性通常不是很重要,但如果要將其打造成產(chǎn)品,那這就至關(guān)重要了。在銀行或醫(yī)療等受監(jiān)管的行業(yè),任何員工的數(shù)據(jù)訪問(wèn)權(quán)限都取決于其工作崗位。
不管是 LLM 還是向量數(shù)據(jù)庫(kù),都沒(méi)有很好的方法來(lái)限制數(shù)據(jù)的訪問(wèn)范圍。知識(shí)圖譜卻能提供很好的解決方案,通過(guò)權(quán)限控制來(lái)規(guī)范參與者可訪問(wèn)數(shù)據(jù)庫(kù)的范圍,不讓他們看到不允許他們看的數(shù)據(jù)。下面是一個(gè)可在知識(shí)圖譜中實(shí)現(xiàn)細(xì)粒度權(quán)限控制的簡(jiǎn)單安全策略:
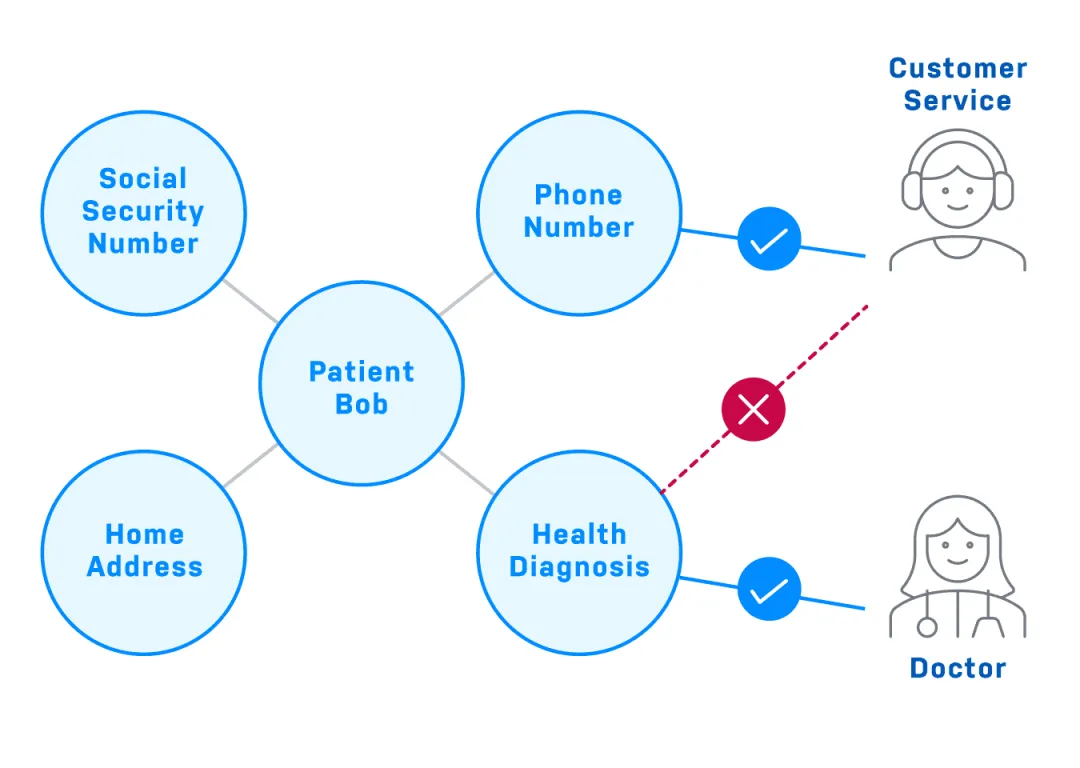
可在知識(shí)圖譜中實(shí)現(xiàn)的一種簡(jiǎn)單安全策略
創(chuàng)建知識(shí)圖譜
構(gòu)建知識(shí)圖譜需要什么?第一步是了解兩種與生成式 AI 應(yīng)用最相關(guān)的圖譜。
領(lǐng)域圖譜(domain graph)表示的是與當(dāng)前應(yīng)用相關(guān)的世界模型。這里有一個(gè)簡(jiǎn)單示例:

領(lǐng)域圖譜
詞匯圖譜(lexical graph)則是文檔結(jié)構(gòu)的圖譜。最基本的詞匯圖譜由詞塊構(gòu)成的節(jié)點(diǎn)組成:

詞匯圖譜
人們往往會(huì)對(duì)其進(jìn)行擴(kuò)展,以包含詞塊、文檔對(duì)象(比如表格)、章節(jié)、段落、頁(yè)碼、文檔名稱或編號(hào)、文集、來(lái)源等之間的關(guān)系。你還可以將領(lǐng)域圖譜和詞匯圖譜組合到一起,如下所示:

將領(lǐng)域?qū)雍驮~匯層組合起來(lái)
詞匯圖譜的創(chuàng)建很簡(jiǎn)單,主要就是簡(jiǎn)單的解析和分塊。至于領(lǐng)域圖譜,則根據(jù)數(shù)據(jù)來(lái)源(來(lái)自結(jié)構(gòu)化數(shù)據(jù)源還是非結(jié)構(gòu)化數(shù)據(jù)源或者兩種來(lái)源都有)的不同,有不同的創(chuàng)建路徑。幸運(yùn)的是,從非結(jié)構(gòu)化數(shù)據(jù)源創(chuàng)建知識(shí)圖譜的工具正在飛速發(fā)展。
舉個(gè)例子,新的 Neo4j Knowledge Graph Builder 可以使用 PDF 文檔、網(wǎng)頁(yè)、YouTube 視頻、維基百科文章來(lái)自動(dòng)創(chuàng)建知識(shí)圖譜。整個(gè)過(guò)程非常簡(jiǎn)單,點(diǎn)幾下按鈕即可,然后你就能可視化和查詢你輸入的文本的領(lǐng)域和詞匯圖譜。這個(gè)工具很強(qiáng)大,也很有趣,能極大降低創(chuàng)建知識(shí)圖譜的門檻。
至于結(jié)構(gòu)化數(shù)據(jù)(比如你的公司存儲(chǔ)的有關(guān)客戶、產(chǎn)品、地理位置等的結(jié)構(gòu)化數(shù)據(jù)),則能直接映射成知識(shí)圖譜。舉個(gè)例子,對(duì)于最常見(jiàn)的存儲(chǔ)在關(guān)系數(shù)據(jù)庫(kù)中的結(jié)構(gòu)化數(shù)據(jù),可以使用一些標(biāo)準(zhǔn)工具基于經(jīng)過(guò)驗(yàn)證的可靠規(guī)則將關(guān)系映射成圖譜。
使用知識(shí)圖譜
有了知識(shí)圖譜后,就可以做 GraphRAG 了,為此有很多框架可選,比如 LlamaIndex Property Graph Index、Langchain 整合的 Neo4j 以及 Haystack 整合的版本。這個(gè)領(lǐng)域發(fā)展很快,但現(xiàn)在編程方法正在變得非常簡(jiǎn)單。
在圖譜創(chuàng)建方面也是如此,現(xiàn)在已經(jīng)出現(xiàn)了 Neo4j Importer(可通過(guò)圖形化界面將表格數(shù)據(jù)導(dǎo)入和映射為圖譜)和前面提到的 Neo4j Knowledge Graph Builder 等工具。下圖總結(jié)了構(gòu)建知識(shí)圖譜的步驟。

自動(dòng)構(gòu)建用于生成式 AI 的知識(shí)圖譜
使用知識(shí)圖譜還能將人類語(yǔ)言的問(wèn)題映射成圖譜數(shù)據(jù)庫(kù)查詢。Neo4j 發(fā)布了一款開源工具 NeoConverse,可幫助使用自然語(yǔ)言來(lái)查詢知識(shí)圖譜:https://neo4j.com/labs/genai-ecosystem/neoconverse/
雖然開始使用圖譜時(shí)確實(shí)需要花一番功夫來(lái)學(xué)習(xí),但好消息是隨著工具的發(fā)展,這會(huì)越來(lái)越簡(jiǎn)單。
總結(jié):GraphRAG 是 RAG 的必定未來(lái)
LLM 固有的基于詞的計(jì)算和語(yǔ)言技能加上基于向量的 RAG 能帶來(lái)非常好的結(jié)果。為了穩(wěn)定地得到好結(jié)果,就必須超越字符串層面,構(gòu)建詞模型之上的世界模型。同樣地,谷歌發(fā)現(xiàn)為了掌握搜索能力,他們就必須超越單純的文本分析,繪制出字符串所代表的事物之間的關(guān)系。我們開始看到 AI 世界也正在出現(xiàn)同樣的模式。這個(gè)模式就是 GraphRAG。
技術(shù)的發(fā)展曲線呈現(xiàn)出 S 型:一項(xiàng)技術(shù)達(dá)到頂峰后,另一項(xiàng)技術(shù)便會(huì)推動(dòng)進(jìn)步并超越前者。隨著生成式 AI 的發(fā)展,相關(guān)應(yīng)用的要求也會(huì)提升 —— 從高質(zhì)量答案到可解釋性再到對(duì)數(shù)據(jù)訪問(wèn)權(quán)限的細(xì)粒度控制以及隱私和安全,知識(shí)圖譜的價(jià)值也會(huì)隨之愈發(fā)凸顯。

生成式 AI 的進(jìn)化
你的下一個(gè)生成式 AI 應(yīng)用很可能就會(huì)用上知識(shí)圖譜。


























