快速學習一個算法,卷積神經網絡
作者:程序員小寒
卷積神經網絡的核心思想是通過局部感知區域和權重共享來有效減少參數數量,同時保留空間信息。它通常由卷積層、池化層以及全連接層組成。
今天給大家分享一個超強的算法模型,卷積神經網絡
卷積神經網絡(CNN)是一種專門用于處理具有網格結構數據的神經網絡架構,最常見的應用領域是圖像處理。
與傳統的全連接神經網絡不同,CNN 通過局部感知和參數共享來有效地處理高維數據,使其在圖像分類、目標檢測、語義分割等任務中表現出色。
 圖片
圖片
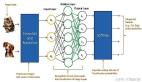
卷積神經網絡的基本結構
卷積神經網絡的核心思想是通過局部感知區域和權重共享來有效減少參數數量,同時保留空間信息。它通常由卷積層、池化層以及全連接層組成。
卷積層
卷積層是 CNN 的核心部分,用來提取輸入數據的局部特征。
卷積層通過多個卷積核對輸入進行卷積操作,生成特征圖(feature maps)。
如下圖所示,對于大小為 7x7x3 的輸入,應用兩個卷積核,每個卷積核通過對三個輸入通道進行卷積來提取不同的特征圖。
 圖片
圖片
卷積核是一組權重,它們通過滑動窗口的方式在輸入上進行卷積運算。
每個卷積核會與輸入的局部區域進行點積,生成一個值,這些值組成輸出特征圖。
 圖片
圖片
卷積層通常有三個重要參數
- 卷積核大小
通常為 3x3 或 5x5,它用來定義卷積核的尺寸。 - 步幅(Stride)
卷積核在輸入上滑動時的步長。
步幅越大,輸出特征圖的尺寸越小。 - 填充(Padding)為了保持輸出特征圖的大小,通常在輸入圖像邊界處填充0。這可以控制輸出的尺寸,并避免輸入尺寸縮小過快。
 圖片
圖片
池化層
池化層用于對卷積層輸出的特征圖進行下采樣,減少特征圖的尺寸,從而減少計算量和內存需求,同時提高模型的魯棒性。
池化層通常有最大池化(Max Pooling)和平均池化(Average Pooling)兩種。
- 最大池化(Max Pooling)
最大池化從一個池化窗口中選取最大值 - 平均池化(Average Pooling)
平均池化是對池化窗口中的元素求平均值
 圖片
圖片
全連接層
全連接層與普通的前饋神經網絡類似,是 CNN 的后幾層,它通常用在卷積層和池化層提取到的特征圖之后,用來進行分類或回歸任務。
全連接層的主要作用是對卷積層提取的特征進行進一步的組合和處理,從而輸出模型的最終預測結果。
 圖片
圖片
案例分享
以下是一個使用卷積神經網絡(CNN)進行手寫數字識別的案例代碼,基于經典的 MNIST 數據集。
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
train_images = train_images.reshape((train_images.shape[0], 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((test_images.shape[0], 28, 28, 1)).astype('float32') / 255
# 搭建 CNN 模型
model = models.Sequential()
# 第一層卷積層:卷積核大小為 3x3,輸出 32 個特征圖
model.add(layers.Conv2D(32, (3, 3), activatinotallow='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2))) # 2x2 最大池化層
# 第二層卷積層
model.add(layers.Conv2D(64, (3, 3), activatinotallow='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 第三層卷積層
model.add(layers.Conv2D(64, (3, 3), activatinotallow='relu'))
# 將特征圖展平
model.add(layers.Flatten())
# 全連接層
model.add(layers.Dense(64, activatinotallow='relu'))
model.add(layers.Dense(10, activatinotallow='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
history = model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f'\nTest accuracy: {test_acc}')
# 可視化訓練過程
plt.plot(history.history['accuracy'], label='Accuracy rate')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show() 圖片
圖片
責任編輯:武曉燕
來源:
程序員學長