模型量化技術綜述:揭示大型語言模型壓縮的前沿技術
大型語言模型(LLMs)通常因為體積過大而無法在消費級硬件上運行。這些模型可能包含數十億個參數,通常需要配備大量顯存的GPU來加速推理過程。
因此越來越多的研究致力于通過改進訓練、使用適配器等方法來縮小這些模型的體積。在這一領域中,一個主要的技術被稱為量化。

在這篇文章中,我將在語言建模的背景下介紹量化,并逐一探討各個概念,探索各種方法論、用例以及量化背后的原理。
大型語言模型(LLMs)的問題
大型語言模型之所以得名,是因為它們包含的參數數量。這些模型通常擁有數十億個參數,存儲這些參數可能相當昂貴。
在推理過程中,激活值是輸入和權重的乘積,同樣可能非常龐大。

所以我們希望盡可能有效地表示數十億個數值,最小化存儲給定值所需的空間。
讓我們從頭開始,探索在優(yōu)化之前如何首先表示數值。
如何表示數值
在計算機科學中,一個給定的數值通常表示為浮點數(或稱為浮點),即帶有小數點的正數或負數。
這些數值由“位”或二進制數字表示。IEEE-754標準描述了如何使用位來表示一個值的三個功能之一:符號、指數或小數部分(或稱尾數)。

這三個方面一起可以用來計算給定一組位值的值:

我們用越多的位來表示一個值,它通常就越精確:

內存限制
可用的位數越多,能表示的數值范圍就越大。

可表示數字的區(qū)間被稱為動態(tài)范圍(dynamic range),而兩個相鄰數值之間的距離被稱為精度(precision)。

這些位的一個巧妙特性是,我們可以計算設備存儲給定值需要多少內存。由于一字節(jié)內存中有8位,我們可以為大多數形式的浮點表示創(chuàng)建一個基本公式。

實際上,在推理過程中,需要的(V)RAM量還與上下文大小和架構等因素有關。但是這部分影響比較小,我們暫時忽略不計。
現在假設我們有一個模型,包含700億個參數。大多數模型默認使用32位浮點數(通常稱為全精度)表示,僅加載模型就需要280GB的內存。

因此最小化表示模型參數的位數(包括在訓練期間)變得非常重要。但是隨著精度的降低,模型的準確性通常也會下降。所以我們希望在保持準確性的同時減少表示數值的位數……這就是量化的用武之地!
量化簡介
量化旨在將模型參數的精度從高位寬(如32位浮點數)降低到低位寬(如8位整數)。

在減少表示原始參數的位數時,通常會有一些精度(細粒度)的損失。為了說明這種效應,我們可以拿任何一幅圖像,僅使用8種顏色來表示它。

放大部分看起來比原圖更“粗糙”,因為我們用更少的顏色來表示它。量化的主要目標是在盡可能保持原始參數的精度的同時,減少表示原始參數所需的位數(顏色)。
常見數據類型
首先讓我們來看看常見的數據類型以及使用它們替代32位(稱為全精度或FP32)表示的影響。
FP16
讓我們看一個從32位到16位(稱為半精度或FP16)浮點數的例子:
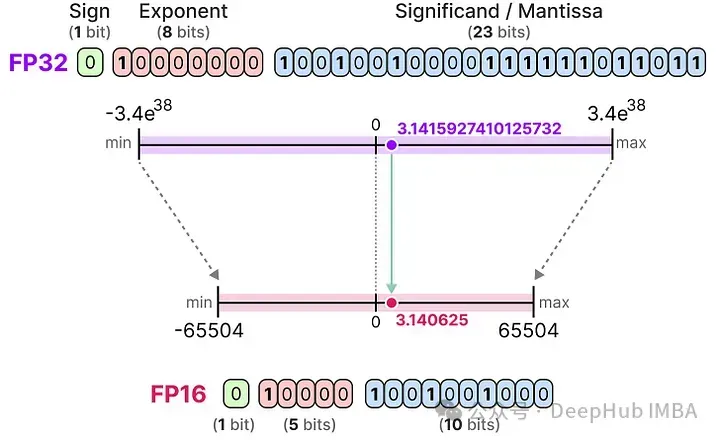
FP16能表示的數值范圍比FP32小很多。
BF16
為了獲得與原始FP32相似的數值范圍,后來又引入了一種名為bfloat 16的“截斷FP32”類型:
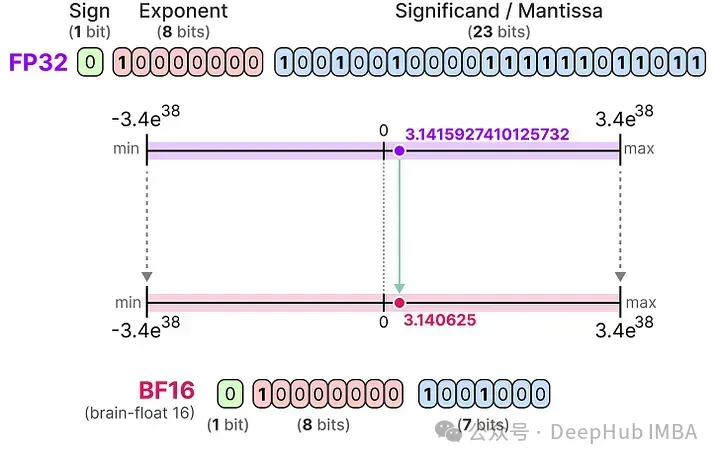
BF16使用與FP16相同的位數,但可以表示更廣泛的數值范圍,常用于深度學習應用中。
INT8
當我們進一步減少位數時,我們接近基于整數的表示而不是浮點表示。例如,從FP32轉換到只有8位的INT8,結果是原始位數的四分之一:
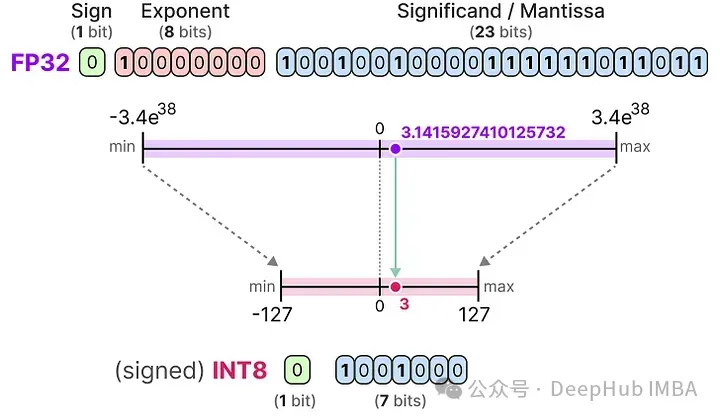
根據硬件不同,基于整數的計算可能比浮點計算更快,但這并不總是如此,使用更少的位進行計算通常會更快。每次減少位數時,都會執(zhí)行一個映射,將初始的FP32表示“壓縮”到較低的位數中。
在實際應用時我們不需要將整個FP32范圍[-3.4e38, 3.4e38]映射到INT8。我們只需要找到一種方法,將我們數據的范圍(模型的參數的最大值和最小值內)映射到INT8。
常見的壓縮/映射方法有對稱和非對稱量化,它們是線性映射的形式。
對稱量化
在對稱量化中,原始浮點值的范圍被映射到量化空間中以零為中心的對稱范圍。在之前的例子中,注意量化前后的范圍如何保持圍繞零對稱。
這意味著浮點空間中零的量化值在量化空間中恰好是零。
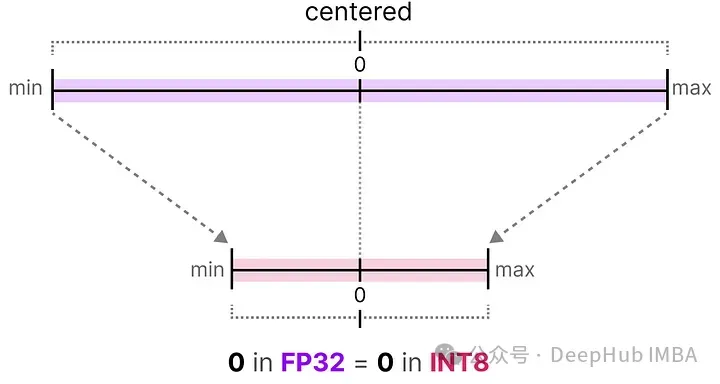
對稱量化的一個很好的例子被稱為絕對最大值(absmax)量化。
給定一系列值,我們取最大的絕對值(α)作為執(zhí)行線性映射的范圍。
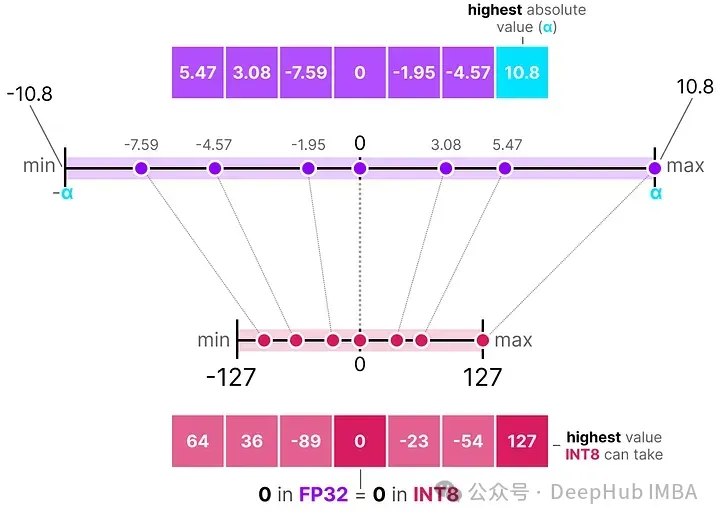
請注意,[-127, 127] 的值范圍代表受限范圍。不受限的范圍是 [-128, 127],這取決于量化方法。
由于這是一個以零為中心的線性映射,公式非常直接。
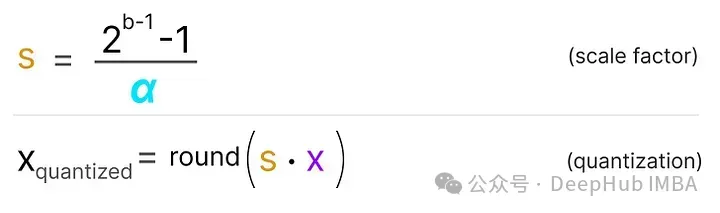
我們首先使用以下公式計算比例因子(*s*):
- b 是我們想要量化到的字節(jié)數(8),
- α 是最大的絕對值,
然后,我們使用 s 來量化輸入 x:
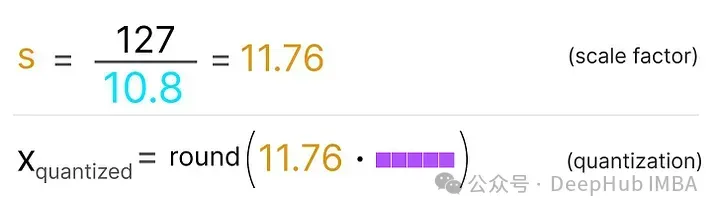
填入這些值會得到以下結果:
為了檢索原始的FP32值,我們可以使用先前計算的縮放因子(*s)來去量化量化值。

應用量化和去量化的過程來檢索原始流程圖解,如下所示:
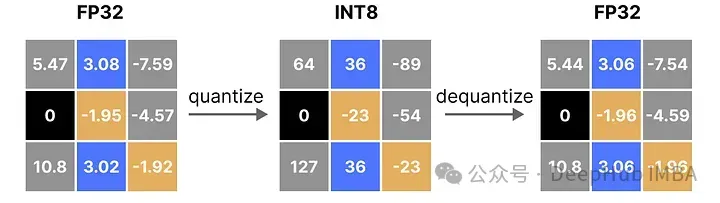
可以看到某些值,例如 3.08 和 3.02,在量化為 INT8 時被賦予了相同的值,即 36。這是因為將這些值反量化回 FP32 時,它們會失去一些精度,不再能夠被區(qū)分開來。
這通常被稱為量化誤差,我們可以通過找出原始值和反量化值之間的差異來計算這一誤差。

一般來說,比特數越低,我們的量化誤差就越大。
非對稱量化
與對稱量化不同的是,非對稱量化不是圍繞零對稱的。它將浮點范圍中的最小值(β)和最大值(α)映射到量化范圍的最小值和最大值。
我們將要探討的方法稱為零點量化。
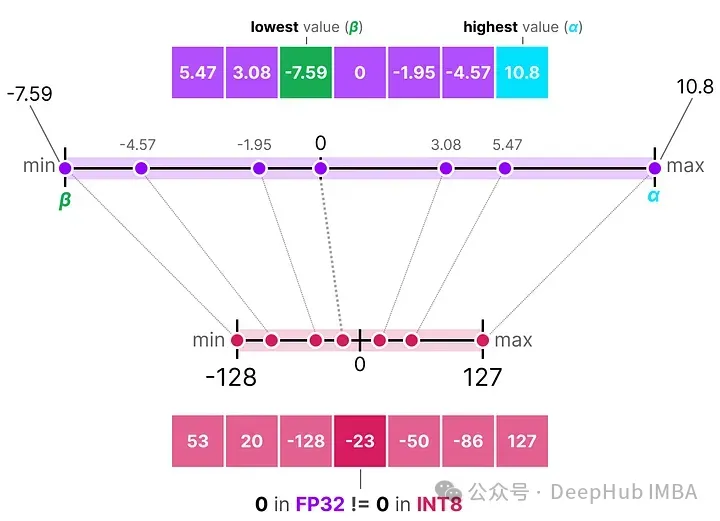
看到0的位置如何發(fā)生了變化嗎?這就是為什么它被稱為非對稱量化。在范圍[-7.59, 10.8]內,最小/最大值到0的距離是不同的。
由于其位置的偏移,我們必須為INT8范圍計算零點,才能執(zhí)行線性映射。像之前一樣也必須計算一個比例因子(s)。

由于需要計算INT8范圍內的零點(z)來移動權重,這個過程略顯復雜。
如之前所述,公式如下:

為了將從INT8量化的數據反量化回FP32,需要使用之前計算的比例因子(s)和零點(z)。

當把對稱和非對稱量化放在一起時,可以很快看到方法之間的區(qū)別:
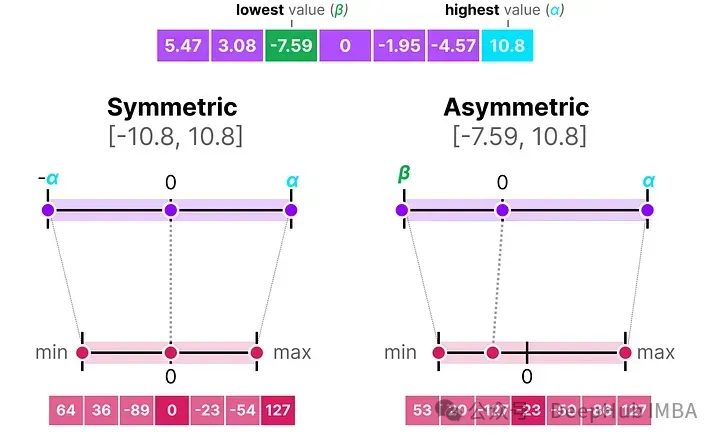
可以明顯的看到對稱量子化的零中心特性與非對稱量子化的偏移量。
范圍映射與裁剪
在之前的例子中,探討了如何將給定向量中的值范圍映射到較低位的表示。盡管這允許將向量值的完整范圍映射出來,但它帶來了一個主要的缺點,即異常值。
假設有一個向量,其值如下:

其中一個值比其他所有值都大得多,可以被認為是一個異常值。如果我們要映射這個向量的完整范圍,所有小的值都會被映射到相同的較低位表示,并且失去它們的區(qū)分因素:
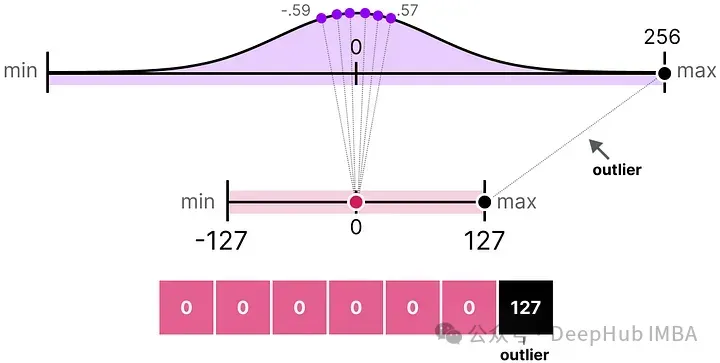
這就是我們之前使用的absmax方法。如果我們不應用裁剪,非對稱量化也會發(fā)生同樣的行為。
所以我們可以選擇裁剪某些值。裁剪涉及設置原始值的不同動態(tài)范圍,使得所有異常值獲得相同的值。
在下面的例子中,手動將動態(tài)范圍設置為[-5, 5],那么所有超出該范圍的值將被映射到-127或127,無論它們的實際值如何:

其主要優(yōu)點是顯著降低了“非異常值”的量化誤差。但是會導致離群值的量化誤差增大。
校準
上面展示了一種選擇[-5, 5]任意范圍的簡單方法。選擇這個范圍的過程被稱為校準,其目的是找到一個范圍,包括盡可能多的值,同時最小化量化誤差。
執(zhí)行這一校準步驟對所有類型的參數來說并不相同。
權重(和偏置)
我們可以將LLM的權重和偏置視為靜態(tài)值,因為在運行模型之前就已知這些值。例如,Llama 3的~20GB文件主要由其權重和偏置組成。
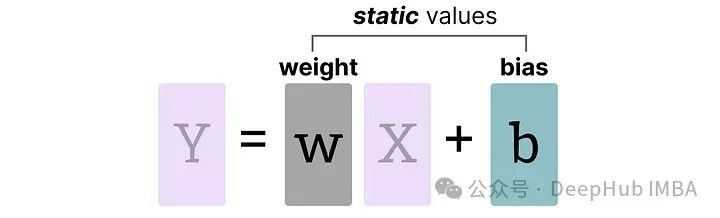
由于偏置的數量(百萬級)遠少于權重(十億級),偏置通常保持較高的精度(如INT16),量化的主要工作集中在權重上。
對于已知且固定的權重,可選擇范圍的校準技術包括:
- 手動選擇輸入范圍的百分位數
- 優(yōu)化原始權重和量化權重之間的均方誤差(MSE)
- 最小化原始值和量化值之間的熵(KL散度)

選擇一個百分位數會導致我們之前看到的類似裁剪行為。
激活
在LLM中持續(xù)更新的輸入通常被稱為“激活”。
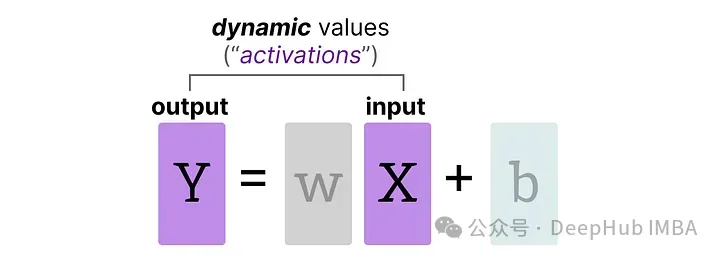
這些值被稱為激活,因為它們通常會通過某些激活函數,如sigmoid或relu。與權重不同,激活會隨著在推理過程中輸入模型的每個數據而變化,這使得準確量化它們變得具有挑戰(zhàn)性。由于這些值在每個隱藏層之后更新,所以只有在輸入數據通過模型時才能知道它們在推理過程中的狀態(tài)。
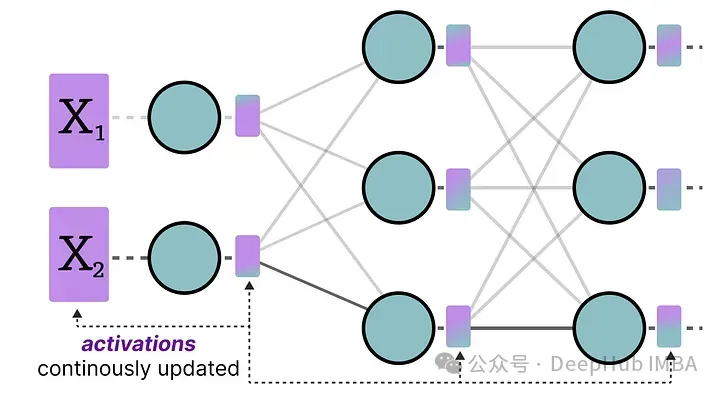
有兩種方法用于校準權重和激活的量化方法:
- 訓練后量化(PTQ)——在訓練之后進行量化
- 量化感知訓練(QAT)——在訓練/微調期間進行量化
訓練后量化
最有名的量化技術之一是訓練后量化(PTQ)。它涉及在訓練模型之后對模型的參數(包括權重和激活)進行量化。
權重的量化使用對稱量化或非對稱量化來執(zhí)行。但是,激活的量化需要推斷模型以獲取它們的潛在分布,因為我們不知道它們的范圍。
所以這里又引出了激活的量化的兩種形式:
動態(tài)量化
數據通過隱藏層后,其激活值被收集:
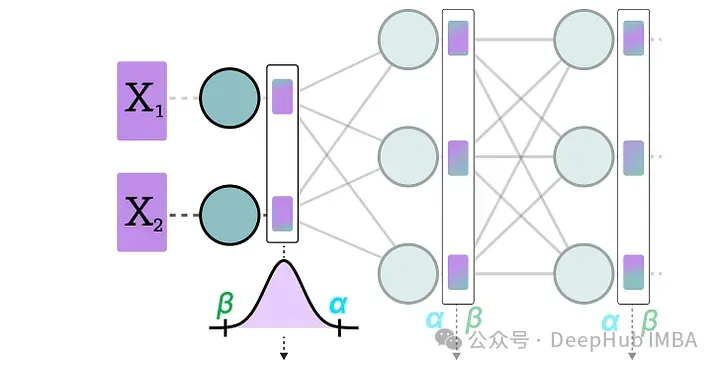
然后使用這些激活值的分布來計算量化輸出所需的零點(z)和比例因子(s)值:
每次數據通過新層時都會重復此過程。每一層都有其自己的z 和 s 值,因此具有不同的量化方案。
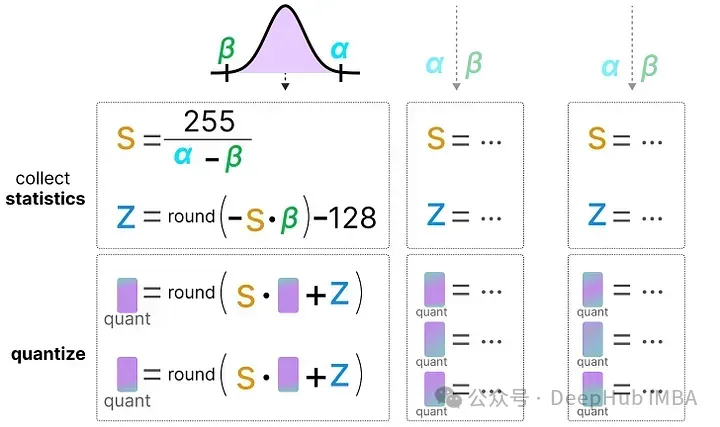
靜態(tài)量化
與動態(tài)量化不同,靜態(tài)量化不是在推理過程中,而是在之前計算零點(z)和比例因子(s)。
為了找到這些值,需要使用一個校準數據集,將其提供給模型以收集這些潛在的分布。
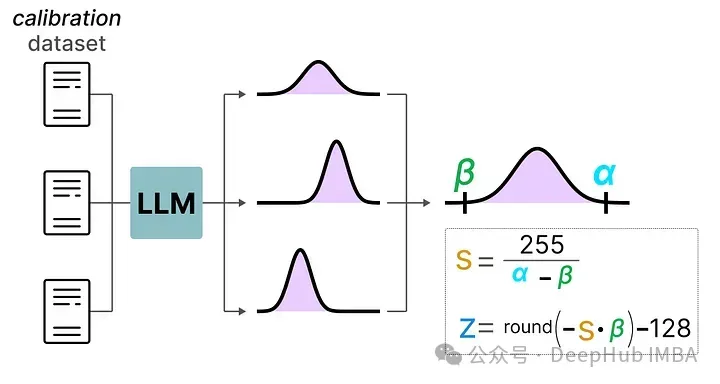
在收集了這些值之后,就可以計算推理過程中執(zhí)行量化所需的s 和 z 值。
在進行實際推理時,s 和 z 值不會重新計算,而是全局使用,量化所有激活。
通常,動態(tài)量化由于僅嘗試計算每個隱藏層的s 和 z 值,因此可能更準確。但是這會大大增加計算時間,因為需要計算這些值。
靜態(tài)量化的準確性雖然較低,但由于已經知道用于量化的s 和 z 值,因此速度更快,所以一般都會使用靜態(tài)量化。
4位量化
將量化位數降低到低于8位已被證明是一項艱巨的任務,因為每減少一位,量化誤差都會增加。但是有幾種靈巧的方法可以將位數減少到6位、4位,甚至2位(盡管通常不建議使用這些方法將位數降低到低于4位)。
這里將介紹在HuggingFace上常見的兩種方法:
GPTQ
GPTQ 是目前最著名的4位量化方法之一。
它使用非對稱量化,并且逐層進行,每層獨立處理完畢后再繼續(xù)到下一層:

在這個逐層量化過程中,它首先將層的權重轉換為逆-赫塞矩陣(Hessian)。赫塞矩陣是模型損失函數的二階導數,它告訴我們模型輸出對每個權重變化的敏感度。它本質上展示了每個權重在層中的(逆)重要性。
與赫塞矩陣中較小值相關聯的權重更為關鍵,因為這些權重的小變化可能會導致模型性能的顯著變化。
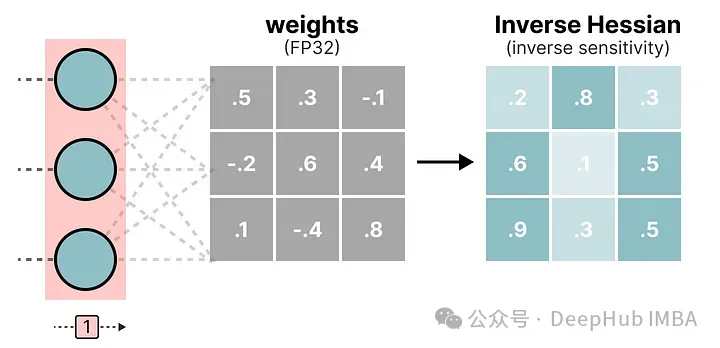
在逆-赫塞矩陣中,較低的值表示更“重要”的權重。我們對權重矩陣中的第一行的權重進行量化然后反量化:
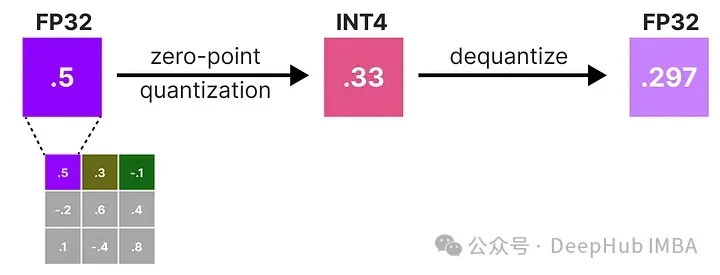
這個過程允許我們計算量化誤差(q),我們可以使用之前計算的逆赫塞(h_1)來加權這個量化誤差。
本質上是根據權重的重要性創(chuàng)建了一個加權量化誤差:
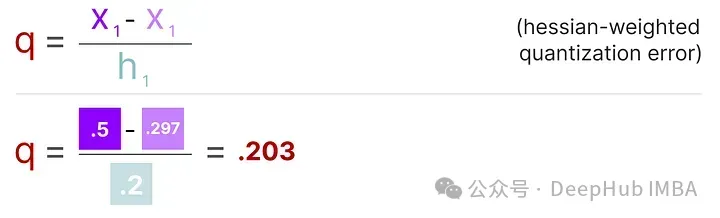
接下來需要將這個加權量化誤差重新分配到行中的其他權重上。這有助于維持網絡的整體功能和輸出。
例如,如果我們對第二個權重,即 .3(x_2)這樣做,我們會將量化誤差(q)乘以第二個權重的逆赫塞(h_2)

我們也可以對給定行中的第三個權重進行相同的處理:
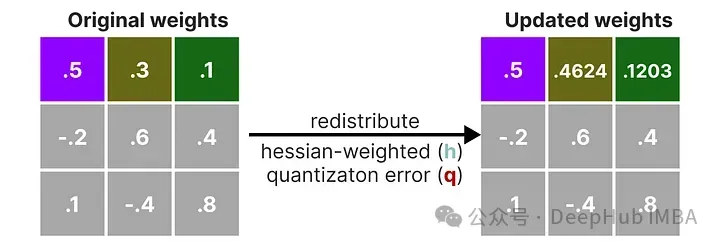
我們重復這個過程,將加權量化誤差重新分配,直到所有值都被量化。
這個方法之所以行之有效,是因為權重通常是相互關聯的。所以當一個權重發(fā)生量化誤差時,相關的權重會相應地更新(通過逆赫塞)。
GGUF
雖然GPTQ是一個在GPU上運行完整LLM的出色量化方法,但我們可能沒有那么強大的GPU。所以可以使用GGUF將LLM的任何層卸載到CPU上。這可以在VRAM不足的情況下同時使用CPU和GPU。
GGUF的量化方法經常更新,可能取決于位量化的級別。我們這里總結一般的原則。
首先,給定層的權重被分割成包含一組“子”塊的“超級”塊。從這些塊中,我們提取比例因子(s)和alpha(α):
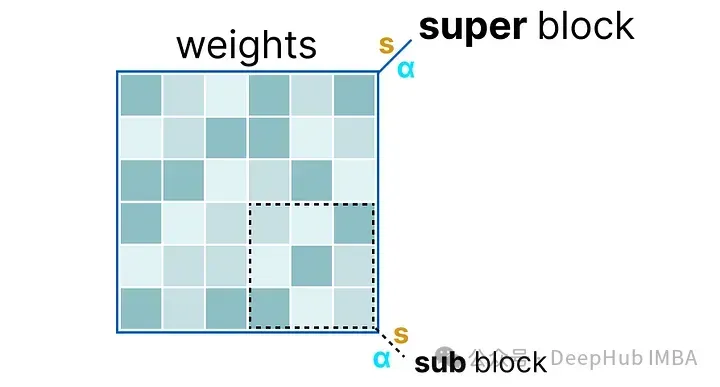
為了量化給定的“子”塊,可以使用之前使用過的absmax量化。記住它將給定的權重乘以比例因子(s):

比例因子是使用“子”塊的信息計算的,但使用“超級”塊的信息量化,后者擁有自己的比例因子:

這種塊量化使用“超級”塊的比例因子(s_super)來量化“子”塊的比例因子(s_sub)。每個比例因子的量化級別可能不同,“超級”塊通常具有比“子”塊的比例因子更高的精度。
我們介紹幾個常用的量化級別(2位、4位和6位):
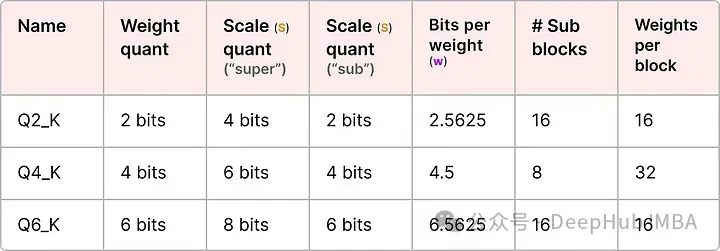
根據量化類型,可能需要一個額外的最小值(m)來調整零點。這些與比例因子(s)一樣被量化。
量化感知訓練
上面我們已經介紹了如何在訓練之后量化一個模型。這種方法的一個缺點是,量化并不考慮實際的訓練過程。
而量化感知訓練(QAT)與訓練后量化(PTQ)在模型訓練完成之后進行量化不同,QAT旨在在訓練期間學習量化過程。

QAT通常比PTQ更精確,因為量化過程已在訓練中被考慮。其工作原理如下:
在訓練過程中,引入所謂的“假”量化。這是一個首先將權重量化為例如INT4,然后再反量化回FP32的過程:

這個過程允許模型在訓練、損失計算和權重更新過程中考慮量化過程。QAT試圖探索損失中的“寬”極小值以最小化量化誤差,因為“窄”極小值往往會導致較大的量化誤差。

例如,假設我們在反向傳播過程中沒有考慮量化。根據梯度下降選擇損失最小的權重。如果它處于“窄”極小值,那將引入更大的量化誤差。
如果我們考慮量化,將在一個“寬”極小值中選擇一個不同的更新權重,其量化誤差將大大降低。
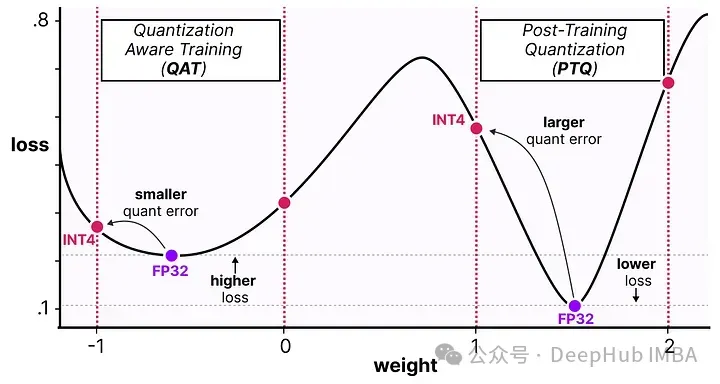
所以盡管PTQ在高精度(例如FP32)中有更低的損失,但QAT在低精度(例如INT4)中會獲得更低的損失
1位大型語言模型的時代:BitNet
正如我們之前看到的,量化到4位已經相當小了,但如果我們進一步減少呢?
這就是BitNet的用武之地,它使用-1或1來表示模型權重的單一位。它通過將量化過程直接注入到Transformer 架構中實現這一點。
Transformer 架構是大多數LLM的基礎,它由涉及線性層的計算組成:
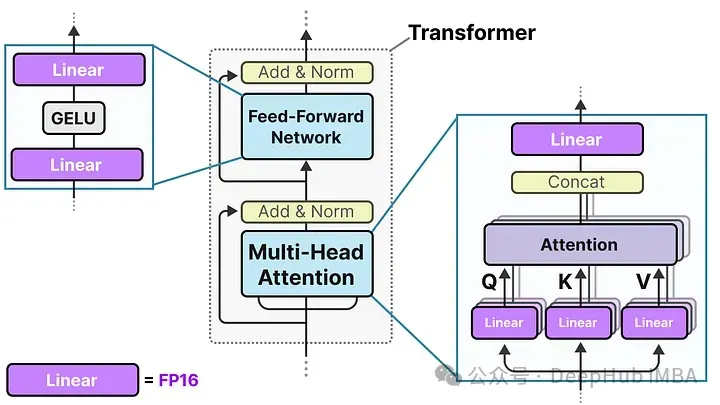
這些線性層通常用更高的精度表示,如FP16,并且是大多數權重所在的地方。
而BitNet用它們稱為BitLinear的東西替換了這些線性層:
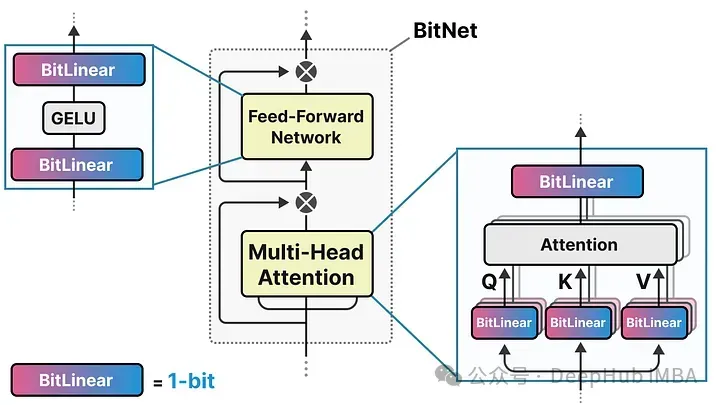
BitLinear層的工作方式與普通線性層相同,根據權重乘以激活來計算輸出。但是BitLinear層使用1位來表示模型的權重,并使用INT8來表示激活:
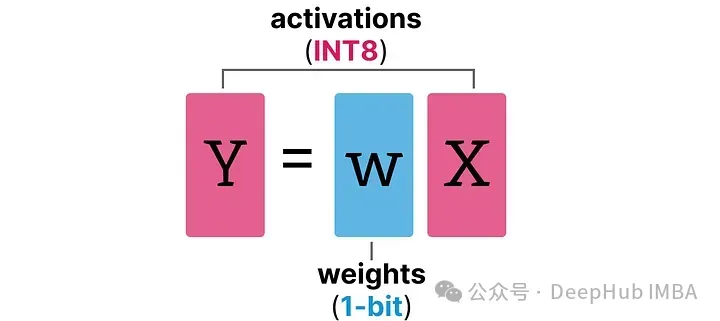
BitLinear層,如量化感知訓練(QAT),在訓練期間執(zhí)行一種“假”量化形式,以分析權重和激活量化的效果:
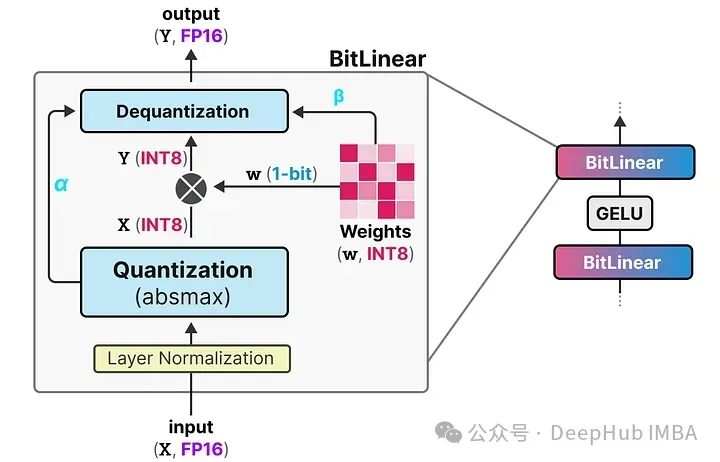
這種方法顯著減少了模型的存儲和計算需求,使得在資源受限的環(huán)境中部署大型語言模型變得可行。同時,通過這種極端的量化方法,BitNet在維持性能的同時大幅降低了能耗和運行成本
在論文中,他們使用γ而不是α,但由于我們在這個示例中使用了a,所以我繼續(xù)使用這個名詞。另外,請β與我們在零點量化中使用的不同,是平均絕對值。
下面我們看看他是如何工作的
權重量化
在訓練過程中,權重存儲在INT8中,然后使用一種稱為符號函數的基本策略,將其量化為1位。
它將權重的分布移動到以0為中心,然后將0左邊的所有值賦值為-1,右邊的所有值賦值為1:
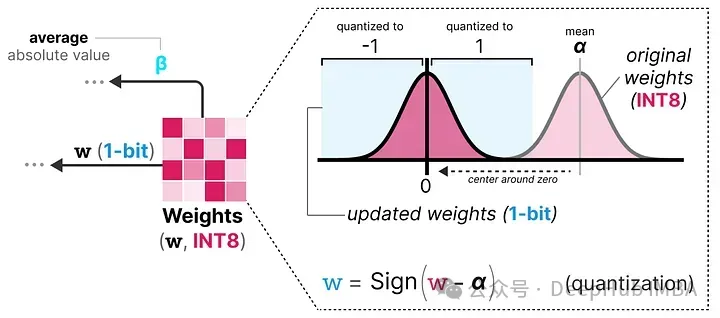
此外,它還跟蹤一個值 β(平均絕對值),因為稍后將用它進行去量化。
激活量化
為了量化激活值,BitLinear使用absmax量化將激活值從FP16轉換為INT8,因為在矩陣乘法(×)中它們需要更高的精度。

此外,它還跟蹤了 α(絕對值),因為稍后將用它進行去量化。
去量化
上面跟蹤了 α(激活值的最大絕對值) 和 β(權重的平均絕對值),這些值將幫助我們將激活值反量化回FP16。
輸出激活值使用 {α, γ} 重新縮放,以將其反量化到原始精度:
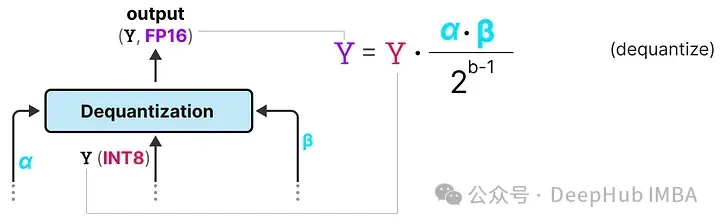
這個過程相對簡單,并允許模型僅用兩個值表示,要么是 -1,要么是 1。使用這種方法,作者觀察到隨著模型大小的增長,1位和FP16訓練之間的性能差距變得越來越小。
并且作者發(fā)現,這僅適用于較大的模型(>30B 參數),而在較小的模型中,差距仍然相當大。
所有大型語言模型都可以變?yōu)?.58位
BitNet 1.58b 被引入以改進之前提到的擴展問題。在這種新方法中,每個權重不再只是 -1 或 1,而是還可以取 0 作為值,使其變成 三元。僅添加 0 極大地改進了BitNet,并且允許更快的計算。
0的力量
那么,為什么添加0是如此重要的改進呢?
這與矩陣乘法有關!
首先,讓我們回顧一般的矩陣乘法是如何工作的。在計算輸出時,將一個權重矩陣乘以一個輸入向量。下面可視化了第一層權重矩陣的第一次乘法:

這種乘法涉及兩個動作,即乘輸入和單個權重,然后將它們加在一起。
BitNet 1.58b 通過使用三元權重基本上可以避免乘法操作,因為三元權重本質上告訴你以下信息:
- 1 — 我想添加這個值
- 0 — 我不需要這個值
- -1 — 我想減去這個值
所以如果權重量化到1.58位,只需要進行加法操作:
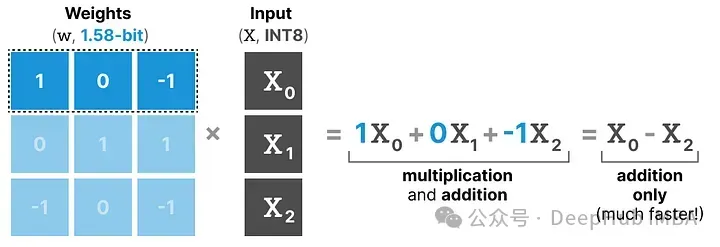
這不僅可以顯著加速計算,還允許進行特征過濾。
通過將給定的權重設置為0,就可以忽略它,而不是像1位表示那樣要么添加要么減去權重。
量化
為了進行權重量化,BitNet 1.58b 使用了 absmean 量化,這是我們之前看到的 absmax 量化的一個變種。
它簡單地壓縮權重的分布,并使用絕對平均值(α)來量化值。然后這些值被四舍五入為 -1、0 或 1:
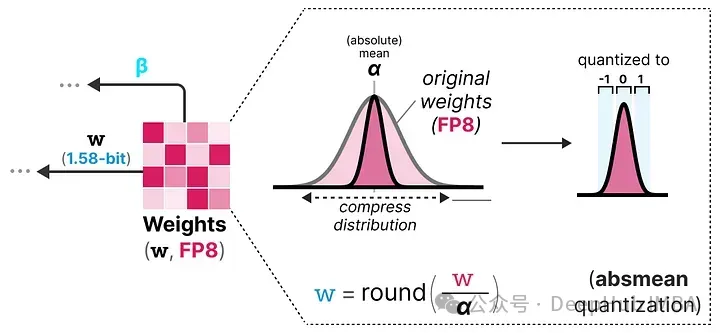
與BitNet相比,激活量化基本相同,但是激活不再縮放到范圍 [0, 2??1],而是使用 absmax 量化 縮放到 [-2??1, 2??1]。
所以1.58位量化主要需要兩個技巧:
- 添加 0 創(chuàng)建三元表示 [-1, 0, 1]
- absmean 量化 用于權重
這樣就得到了輕量級模型,因為它們只需要1.58位的計算效率!
總結
本文深入探討了量化技術在大型語言模型(LLMs)中的應用,特別介紹了幾種量化方法,包括訓練后量化(PTQ)、量化感知訓練(QAT)、GPTQ、GGUF和BitNet。量化技術通過減少模型的參數精度來降低存儲和計算需求,從而使模型能在資源受限的環(huán)境中高效運行。
PTQ和QAT分別在訓練后和訓練過程中實施量化,以優(yōu)化模型性能和減小量化誤差。GPTQ和GGUF則是針對特定硬件環(huán)境優(yōu)化的量化策略,如使用GPU或CPU。特別值得一提的是BitNet和其進階版本BitNet 1.58b,它們通過將模型權重量化到極低的位數(如1位和1.58位),顯著提升了計算效率并降低了模型體積。
希望這篇文章能讓你更好地理解量化、GPTQ、GGUF和BitNet的潛力。誰知道將來模型會變得多小呢?