













中國科學院團隊首篇LLM模型壓縮綜述:細聊剪枝、知識蒸餾、量化技術
近來,大型語言模型(LLM)在各種任務中表現出色。然而,即便有卓越的任務處理能力,LLM 卻面臨著巨大的挑戰,這些挑戰源于其巨大的規模和計算需求。舉個例子,GPT-175B 版本具有驚人的 1750 億參數,至少需要 320GB(使用 1024 的倍數)的半精度(FP16)格式存儲。此外,部署此模型進行推理還需要至少五個 A100 GPU,每個 GPU 具有 80GB 的內存,這樣才能有效地保證運行。
為了解決這些問題,當下一種被稱為模型壓縮的方法可以成為解決方案。模型壓縮可以將大型、資源密集型模型轉換為適合存儲在受限移動設備上的緊湊版本。此外它可以優化模型,以最小的延遲更快地執行,或實現這些目標之間的平衡。
除了技術方面之外,LLM 還引發了關于環境和倫理問題的討論。這些模型給發展中國家的工程師和研究人員帶來了重大挑戰,在這些國家,有限資源可能會成為獲得模型所需基本硬件的阻力。LLM 的大量能源消耗會加劇碳排放,人工智能研究與可持續發展也是非常重要的一個問題。解決這些挑戰的一個可能的解決方案是利用模型壓縮技術,在不顯著影響性能的情況下具有減少碳排放的潛力。通過它,人類可以解決環境問題,增強人工智能的可訪問性,并促進 LLM 部署中的包容性。
本文中,來自中國科學院信息工程研究所、人大高瓴人工智能學院的研究者闡述了最近在專門為 LLM 量身定制的模型壓縮技術領域取得的進展。本文對方法、指標和基準進行詳盡的調查,并進行了分類。

論文地址:https://arxiv.org/pdf/2308.07633.pdf
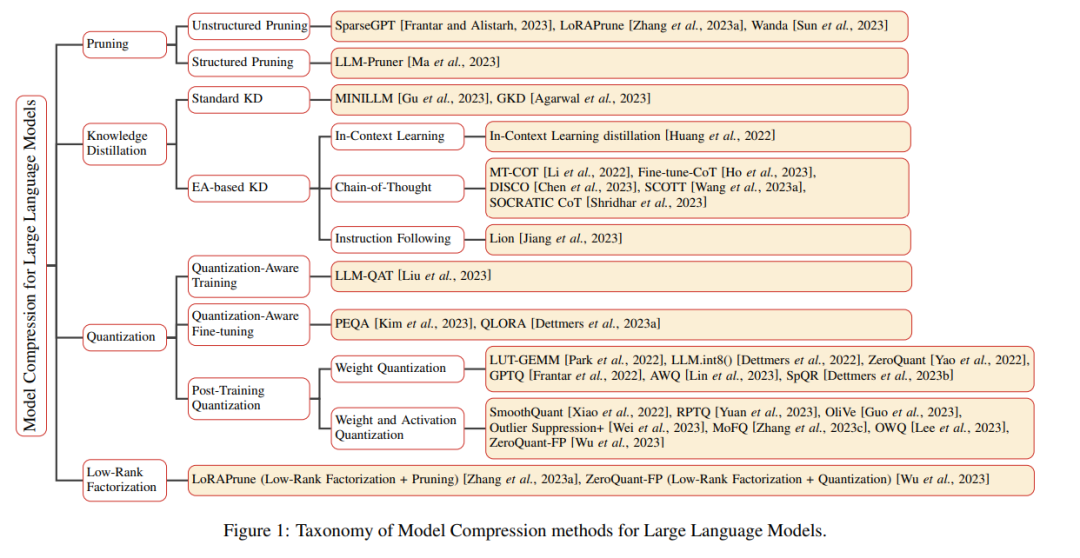
如下圖 1 所示,本文提出的分類法為理解 LLM 的模型壓縮方法提供了一個完整的結構化框架。這一探索包括對已有成熟技術的透徹剖析,包括但不限于剪枝、知識蒸餾、量化和低秩因子分解。此外,本文揭示了當前的挑戰,并展望了這一發展領域未來潛在的研究軌跡。
研究者還倡導社區合作,為 LLM 建立一個具有生態意識、包羅萬象、可持續的未來鋪平道路。值得注意的是,本文是專門針對 LLM 的模型壓縮領域的首篇綜述。
方法論
剪枝
剪枝是一種強大的技術,通過刪除不必要的或冗余組件來減少模型的大小或復雜性。眾所周知,有許多冗余參數對模型性能幾乎沒有影響,因此在直接剪掉這些冗余參數后,模型性能不會收到太多影響。同時,剪枝可以在模型存儲、內存效率和計算效率等方面更加友好。
剪枝可以分為非結構化剪枝和結構化剪枝,二者的主要區別在于剪枝目標和由此產生的網絡結構。結構化剪枝剪掉基于特定規則的連接或分層結構,同時保留整體網絡結構。非結構化剪枝針對單個參數,會導致不規則的稀疏結構。最近的研究工作致力于將 LLM 與剪枝技術相結合,旨在解決與 LLM 相關的大規模和計算成本。
知識蒸餾
知識蒸餾(KD)是一種實用的機器學習技術,旨在提高模型性能和泛化能力。該技術將知識從被稱為教師模型的復雜模型轉移到被稱為學生模型的更簡單模型。KD 背后的核心思想是從教師模型的全面知識中轉化出更精簡、更有效的代表。本文概述了使用 LLM 作為教師模型的蒸餾方法。
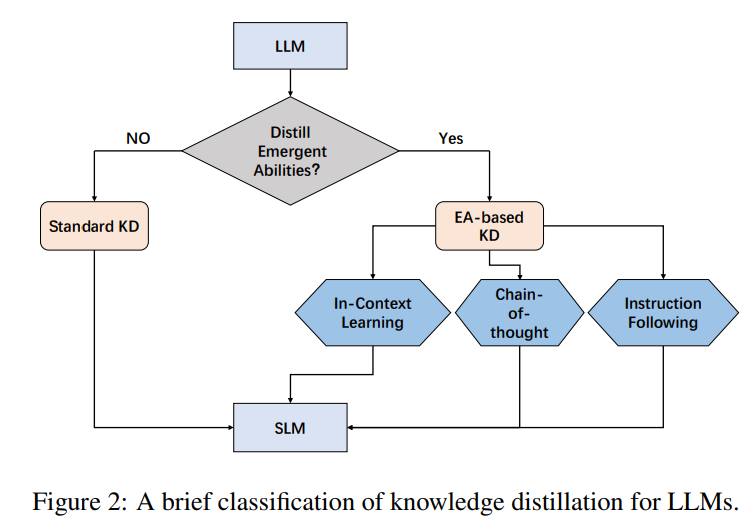
研究者根據這些方法是否側重于將 LLM 的涌現能力(EA)蒸餾到小模型(SLM)進行分類。因此,這些方法被分為兩類:標準 KD 和基于 EA 的 KD。對于視覺表示任務,嚇圖 2 提供了 LLM 知識蒸餾的簡要分類。
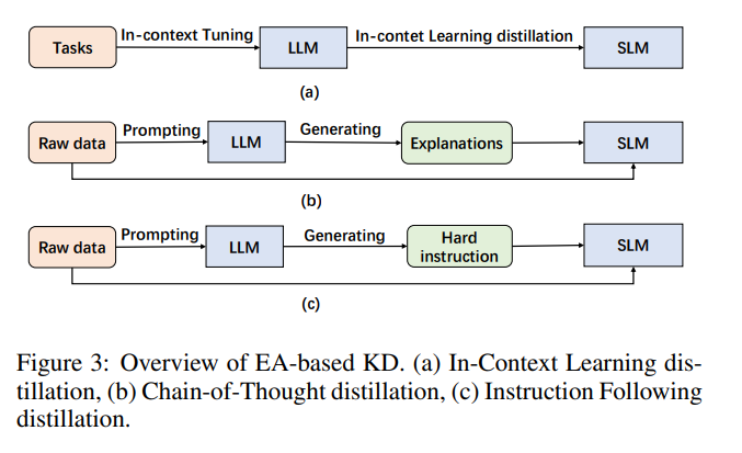
下圖 3 為基于 EA 的蒸餾概覽。
量化
在模型壓縮領域,量化已成為一種被廣泛接受的技術,以緩解深度學習模型的存儲和計算開銷。雖然傳統上使用浮點數表示權重,但量化將它們轉換為整數或其他離散形式。這種轉換大大降低了存儲需求和計算復雜性。雖然會出現一些固有的精度損失,但精巧的量化技術可以在精度下降最小的情況下實現實質性模型壓縮。
量化可以分為三種主要方法:量化感知訓練(QAT)、量化感知微調(QAF)以及訓練后量化(PTQ)。這些方法的主要區別在于何時應用量化來壓縮模型。QAT 在模型的訓練過程中采用量化,QAF 在預訓練模型的微調階段應用量化,PTQ 在模型完成訓練后對其進行量化。
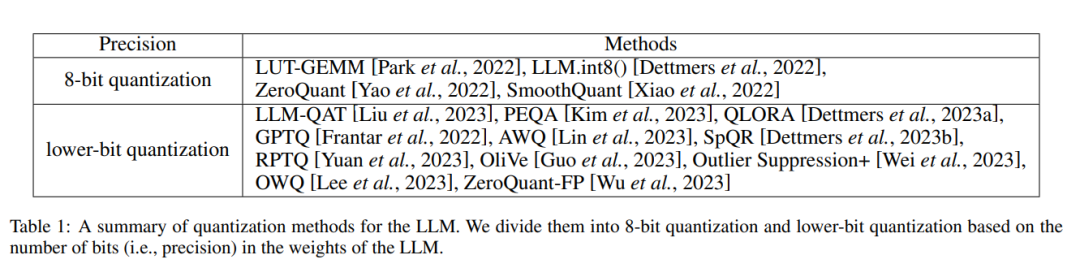
最近的研究致力于利用量化來壓縮 LLM,產生了驚人的結果。這些工作主要可以分為上述三種方法:量化感知訓練、量化感知微調和訓練后量化。此外,下表 1 是應用于 LLM 的量化方法的匯總。該表根據 LLM 權重中的位數(精度)將這些工作分為 8 位量化和低位量化。
低秩分解
低秩分解是一種模型壓縮技術,旨在通過將給定的權重矩陣分解為兩個或更多具有明顯較低維度的較小矩陣來近似給定的矩陣。低秩分解背后的核心思想是將大權重矩陣 W 分解為兩個矩陣 U 和 V,使得 W ≈ UV,其中 U 是 m×k 矩陣,V 是 k×n 矩陣,k 比 m 和 n 小得多。U 和 V 的乘積近似于原始權重矩陣,參數數量和計算開銷大幅減少。
在 LLM 研究領域,低秩分解被廣泛采用,以有效地微調 LLM,例如 LORA 及其變體。本文專注于這些使用低秩分解來壓縮 LLM 的工作。在 LLM 的模型壓縮領域,研究者經常將多種技術與低秩分解相結合,包括剪枝、量化等,例如 LoRAPrune 和 ZeroQuantFP,在保持性能的同時實現更有效的壓縮。
隨著該領域研究的繼續,在應用低秩分解來壓縮 LLM 方面可能會有進一步發展,但仍然需要進行探索和實驗,以充分利用 LLM 的潛力。
度量和基準
度量
LLM 的推理效率可以使用各種指標來衡量。這些指標考慮了性能的不同方面,通常與全面評估 LLM 的準確性和零樣本學習能力一起呈現。
這些指標包括如下:
- 參數規模
- 模型規模
- 壓縮比
- 推理時間
- 浮點運算(FLOP)
基準
基準旨在與未壓縮的 LLM 相比,衡量壓縮 LLM 的有效性、效率和準確性。這些基準通常由不同的任務和數據集組成,涵蓋了一系列自然語言處理挑戰。常用基準包括但不限于 HULK 和 ELUE。
最后研究者認為未來應在以下幾個方面進一步探索,包括
- 專業的基準測試
- 性能規模的權衡
- 動態 LLM 壓縮
- 可解釋性
更多細節請參閱原論文。




















