DeepMind新方法:訓(xùn)練時間減少13倍,算力降低90%
大幅節(jié)省算力資源,又又又有新解了!!
DeepMind團隊提出了一種新的數(shù)據(jù)篩選方法JEST——
將AI訓(xùn)練時間減少13倍,并將算力需求降低90%。

簡單來說,JEST是一種用于聯(lián)合選擇最佳數(shù)據(jù)批次進行訓(xùn)練的方法。
它就像一個智能的圖書管理員,在一大堆書(數(shù)據(jù))中挑選出最適合當(dāng)前讀者(模型)閱讀的幾本書(數(shù)據(jù)批次)。
這樣做可以讓讀者更快地學(xué)到知識(訓(xùn)練模型),還能節(jié)省時間(減少迭代次數(shù))和精力(減少計算量)。
研究顯示,JEST大幅加速了大規(guī)模多模態(tài)預(yù)訓(xùn)練,與之前的最先進水平(SigLIP)相比,迭代次數(shù)和浮點運算次數(shù)減少了10倍。

對于上述結(jié)果,有網(wǎng)友驚呼:
新研究將成為AI訓(xùn)練的游戲規(guī)則改變者!

還有人點出了關(guān)鍵:
對于擔(dān)心人工智能需求過高的電網(wǎng)來說,這可能是個極好的消息!

那么,新方法究竟是如何運作的?接下來一起看團隊成員相關(guān)揭秘。
揭秘新方法JEST
首先,現(xiàn)有的大規(guī)模預(yù)訓(xùn)練數(shù)據(jù)篩選方法速度慢、成本高,并且沒有考慮到批次組成或訓(xùn)練過程中數(shù)據(jù)相關(guān)性的變化,這限制了多模態(tài)學(xué)習(xí)中的效率提升。
因此,DeepMind團隊研究了聯(lián)合選擇數(shù)據(jù)批次而非單個樣本是否能夠加速多模態(tài)學(xué)習(xí)。
研究得出了3個結(jié)論:
- 挑選好的數(shù)據(jù)批次比單獨挑選數(shù)據(jù)點更為有效
- 在線模型近似可用于更高效地過濾數(shù)據(jù)
- 可以引導(dǎo)小型高質(zhì)量數(shù)據(jù)集以利用更大的非精選數(shù)據(jù)集
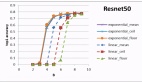
基于上述,JEST能夠在僅使用10%的FLOP預(yù)算的情況下超越之前的最先進水平。

這一結(jié)果是如何實現(xiàn)的呢?
據(jù)團隊介紹,他們在之前的工作中已展示了,對最好的50%數(shù)據(jù)進行訓(xùn)練如何顯著提高FLOP效率。

而現(xiàn)在,新研究證明過濾更多數(shù)據(jù)(高達90%)可以產(chǎn)生更好的性能。
這里有三個關(guān)鍵:
- 選擇好的批次 > 選擇稍微好的數(shù)據(jù)點
- 調(diào)整默認的ADAM超參數(shù)
- 非常高質(zhì)量(但很小)的參考數(shù)據(jù)集
具體而言,JEST是從一個更大的候選數(shù)據(jù)集中選擇最佳的訓(xùn)練數(shù)據(jù)批次。
在數(shù)據(jù)選擇標準上,JEST借鑒了之前關(guān)于RHO損失的研究,并結(jié)合了學(xué)習(xí)模型和預(yù)訓(xùn)練參考模型的損失來評估數(shù)據(jù)點的可學(xué)習(xí)性。JEST選擇那些對于預(yù)訓(xùn)練模型來說較容易,但對于當(dāng)前學(xué)習(xí)模型來說較難的數(shù)據(jù)點,以此提高訓(xùn)練效率和效果。

成員Nikhil進一步解釋了多模態(tài)對比學(xué)習(xí)的過程,即通過最大化文本和圖像嵌入的對齊性,同時最小化不相關(guān)數(shù)據(jù)之間的對齊性,來提高模型的性能。
利用這一點,團隊采用一種基于阻塞吉布斯采樣的迭代方法,逐步構(gòu)建批次,每次迭代中根據(jù)條件可學(xué)習(xí)性評分選擇新的樣本子集。

與單獨選擇數(shù)據(jù)相比,新方法在過濾更多數(shù)據(jù)時持續(xù)改進。包括使用僅基于預(yù)訓(xùn)練的參考模型來評分數(shù)據(jù)也是如此,即CLIPScore,這是離線基礎(chǔ)數(shù)據(jù)集篩選的流行基線。

不過,過濾更多數(shù)據(jù)會增加浮點運算次數(shù)(FLOPs),因為評分需要學(xué)習(xí)者和參考模型進行推理傳遞。
對此,團隊在數(shù)據(jù)集中緩存了預(yù)訓(xùn)練的參考模型分數(shù),他們采用了FlexiViT架構(gòu)進行低分辨率評分,并在多種分辨率下進行了訓(xùn)練。

這一研究證明了:
多分辨率訓(xùn)練對于協(xié)調(diào)評分和學(xué)習(xí)者模型至關(guān)重要
另外,研究強調(diào)了使用高質(zhì)量的精選數(shù)據(jù)集來訓(xùn)練參考模型的重要性,這有助于優(yōu)化大規(guī)模預(yù)訓(xùn)練的數(shù)據(jù)分布,從而提升模型的泛化能力。

總而言之,相關(guān)變體JEST++和FlexiJEST++的性能顯著優(yōu)于許多其他先前的SOTA模型,同時使用的計算量更少。

針對大家可能的疑問:
為什么不只在用于參考模型的精選數(shù)據(jù)集上進行訓(xùn)練呢?
團隊預(yù)先解釋,相關(guān)結(jié)果表明精選的參考模型是專家型模型(在某些任務(wù)上表現(xiàn)良好)。JEST++利用專家型參考模型,將其轉(zhuǎn)化為通用模型,在所有基準測試中都取得了改進。

最后,研究發(fā)現(xiàn)JEST++最終可以通過消除對預(yù)訓(xùn)練數(shù)據(jù)集的任何篩選需求來簡化數(shù)據(jù)管理流程。
通過使用預(yù)訓(xùn)練參考模型,在未經(jīng)篩選(原始)的網(wǎng)絡(luò)規(guī)模數(shù)據(jù)上進行訓(xùn)練,性能幾乎沒有下降。

來自DeepMind
上述研究由來自DeepMind的4位成員共同完成。
Talfan Evans,至今在DeepMind工作3年多,是機器學(xué)習(xí)團隊的一名研究科學(xué)家,近期研究方向是大規(guī)模模型數(shù)據(jù)訓(xùn)練和任務(wù)對齊。曾就讀于倫敦帝國理工學(xué)院戴森機器人實驗室(空間/視覺感知系統(tǒng)中的實時分布式推理)。

高級研究員Olivier Hénaff,至今在DeepMind工作5年多,專注于了解生物和人工智能的基本原理。在DeepMind一直研究自監(jiān)督算法,近期對視覺表征如何構(gòu)建我們的記憶、實現(xiàn)靈活的感知推理和長視頻理解感興趣。曾就讀于美國紐約大學(xué)神經(jīng)科學(xué)中心博士和法國巴黎綜合理工學(xué)院碩士(數(shù)學(xué))。

研究科學(xué)家Nikhil Parthasarathy,至今在DeepMind工作5年多,負責(zé)建立視覺感知模型,研究方向涵蓋表示學(xué)習(xí)、計算機視覺、計算神經(jīng)科學(xué)和視覺感知。曾就讀于紐約大學(xué)博士,斯坦福大學(xué)本碩。

研究工程師Hamza Merzic,2018年加入DeepMind,研究領(lǐng)域包括主動學(xué)習(xí)、視覺想象、表征學(xué)習(xí)、強化學(xué)習(xí)、深度學(xué)習(xí)和機器人技術(shù)。他是瑞士聯(lián)邦理工學(xué)院的碩士生,并在2023年至今期間擔(dān)任博士生導(dǎo)師。

目前相關(guān)論文已公開,感興趣可以進一步了解。