多步時間序列預(yù)測策略實戰(zhàn)
從數(shù)據(jù)科學(xué)的技術(shù)角度來看,預(yù)測單步和預(yù)測多步有很大區(qū)別,后者更難。預(yù)測多個時期需要全面了解長期模式和依賴關(guān)系。它具有前瞻性,需要模型來捕捉一段時間內(nèi)錯綜復(fù)雜的動態(tài)變化。
多步預(yù)測的策略通常有兩種,即單不預(yù)測策略和遞歸預(yù)測策略。時序基礎(chǔ)模型 ARIMA 是單步預(yù)測模型。那么如何實現(xiàn)多步驟預(yù)測?也許一種方法是遞歸使用同一模型。從模型中得到一個周期的預(yù)測結(jié)果,作為預(yù)測下一個周期的輸入。然后,將第二期的預(yù)測作為預(yù)測第三期的輸入。可以通過使用前一期的預(yù)測結(jié)果來遍歷所有時期。這正是遞歸預(yù)測或迭代預(yù)測策略的作用。圖(A)顯示模型首先產(chǎn) ,然后 成為同一模型的輸入,產(chǎn)
:遞歸預(yù)測策略") 圖(A):遞歸預(yù)測策略
圖(A):遞歸預(yù)測策略
在"基于樹的時間序列預(yù)測實戰(zhàn)"中,我們學(xué)會了將單變量時間序列表述為基于樹的建模問題。我們可以將一個時期的值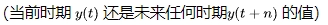 作為樹狀模型的目標(biāo),得出一個無偏值。若我們建立n個模型,每個模型都能預(yù)測第 n 個時期,我們可以將它們的預(yù)測結(jié)果結(jié)合起來,這就是直接預(yù)測策略。這個方法成功的原因在于,針對單一目標(biāo)的樹狀模型通常是有效的,而且不同的模型可以捕捉到隨時間變化的復(fù)雜動態(tài)。其他替代策略也存在,但主要是這兩種方法的衍生。
作為樹狀模型的目標(biāo),得出一個無偏值。若我們建立n個模型,每個模型都能預(yù)測第 n 個時期,我們可以將它們的預(yù)測結(jié)果結(jié)合起來,這就是直接預(yù)測策略。這個方法成功的原因在于,針對單一目標(biāo)的樹狀模型通常是有效的,而且不同的模型可以捕捉到隨時間變化的復(fù)雜動態(tài)。其他替代策略也存在,但主要是這兩種方法的衍生。
:直接預(yù)測策略") 圖(B):直接預(yù)測策略
圖(B):直接預(yù)測策略
兩種主要策略是:
- 遞歸預(yù)測
- n步直接預(yù)測
這兩種方法需要耗費大量時間進(jìn)行數(shù)據(jù)重組和模型迭代。遞歸策略已經(jīng)納入經(jīng)典 Python 庫 "statsmodels"中,而我將采用開源 Python 庫 "Sktime",該庫使遞歸和直接預(yù)測方法變得更加簡單。Sktime 封裝了多種工具,包括 "statsmodels",并提供了統(tǒng)一的 API,可用于時間序列預(yù)測、分類、聚類和異常檢測(Markus等人,2019,2020)
接下來云朵君和大家一起學(xué)習(xí)如何思考產(chǎn)生多步預(yù)測的策略、多步預(yù)測的代碼以及評估。
- 多步預(yù)測的遞歸策略
- n 個周期、n 個模型的直接預(yù)測策略
- 使用 ARIMA 的遞歸策略
安裝 sktime 庫和 lightGBM 庫。
!pip install sktime
!pip install lightgbm遞歸預(yù)測
遞歸策略中,先對前一步進(jìn)行預(yù)測,然后用這些預(yù)測作為輸入,對未來的時間步驟進(jìn)行迭代預(yù)測。整個過程中只使用一個模型,生成一個預(yù)測,并將其輸入到模型中生成下一個預(yù)測,如此循環(huán)。步驟如下:
- 建模:訓(xùn)練一個時間序列預(yù)測模型,預(yù)測一步前瞻。可以使用傳統(tǒng)的時間序列模型(如ARIMA)、指數(shù)平滑模型或機器學(xué)習(xí)模型(如lightGBM)。
- 生成第一次預(yù)測:利用歷史數(shù)據(jù),使用已訓(xùn)練的模型預(yù)測下一個時間步驟。
- 將預(yù)測值作為下一次預(yù)測模型的輸入:將預(yù)測值添加到歷史數(shù)據(jù)中,創(chuàng)建更新的時間序列。
- 迭代預(yù)測:使用更新后的時間序列作為模型的輸入數(shù)據(jù),重復(fù)上述過程。在每次迭代中,模型考慮之前的預(yù)測值,進(jìn)行多步驟預(yù)測。繼續(xù)迭代預(yù)測過程,直到達(dá)到期望的未來步數(shù)。
一個可以發(fā)現(xiàn)的問題是,隨著時間推移,預(yù)測的準(zhǔn)確性會下降,初期預(yù)測的誤差會在后期積累。只要模型足夠復(fù)雜,能夠捕捉到錯綜復(fù)雜的模式,這種情況似乎是可以接受的。
加載電力消耗數(shù)據(jù),數(shù)據(jù)說明可以在"基于樹模型的時間序列預(yù)測實戰(zhàn)"中找到。
%matplotlib inline
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
data = pd.read_csv('/electric_consumption.csv', index_col='Date')
data.index = pd.to_datetime(data.index)
data = data.sort_index() # Make sure the data are sorted
data.index = pd.PeriodIndex(data.index, freq='H') # Make sure the Index is sktime format
data.index我唯一想指出的是使用 pd.PeriodIndex() 使索引符合 sktime 格式。
 圖片
圖片
從 Pandas DataFrame 中提取一個序列。Pandas 系列保留了 sktime 所需的索引。
y = data['Consumption']
# Train and test split
cuttime = int(len(y)*0.9) # Take 90% for training
train = y[0:cuttime]
test = y[cuttime::]
y 圖片
圖片
我們計劃使用遞歸預(yù)測方法并建立一個 lightGBM 模型,使用與"基于樹的時間序列預(yù)測教程"相同的超參數(shù)。此外,Python Notebook 中還有一個未顯示的 GBM 模型示例供你嘗試其他模型。
import lightgbm as lgb
from sktime.forecasting.compose import make_reduction
lgb_regressor = lgb.LGBMRegressor(num_leaves = 10,
learning_rate = 0.02,
feature_fraction = 0.8,
max_depth = 5,
verbose = 0,
num_boost_round = 15000,
nthread = -1
)
lgb_forecaster = make_reduction(lgb_regressor, window_length=30, strategy="recursive")
lgb_forecaster.fit(train)我們只指定了 "遞歸" 作為策略超參數(shù)值,稍后會采用 "直接" 預(yù)測方法。
下一步,我們需要生成一個未來周期的數(shù)字列表。我設(shè)置未來期限 (fh) 為 100 期,即 [1,2,...,100]。然后生成這 100 期的預(yù)測。
vlen = 100
fh = list(range(1, vlen,1))
y_test_pred = lgb_forecaster.predict(fh= fh)
y_test_pred與測試數(shù)據(jù)中的實際值相比,預(yù)測結(jié)果如何?讓我們將 100 期的實際值和預(yù)測值進(jìn)行匹配并繪制成圖。
from sktime.utils.plotting import plot_series
actual = test[test.index<=y_test_pred.index.max()]
plot_series(actual, y_test_pred, labels=['Actual', 'Predicted'])
plt.show()我使用的函數(shù) plot_series() 只是 matplotlib 函數(shù)的封裝。
:使用 LightGBM 的遞歸策略") 圖 (A):使用 LightGBM 的遞歸策略
圖 (A):使用 LightGBM 的遞歸策略
常見的評估指標(biāo)包括平均絕對百分比誤差(MAPE)和對稱MAPE。在sktime中,可以通過控制超參數(shù)來簡化這一操作。
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
print('%.16f' % mean_absolute_percentage_error(actual, y_test_pred, symmetric=False))
print('%.16f' % mean_absolute_percentage_error(actual, y_test_pred, symmetric=True))結(jié)果如下。稍后我們將把這兩個數(shù)字與直接預(yù)測法中的數(shù)字進(jìn)行比較。
- MAPE: 0.0546382493115653
- sMAPE: 0.0547477326419614
太好了,我們成功地使用遞歸法建立了多重預(yù)測。接下來,讓我們學(xué)習(xí)直接預(yù)測策略。
n步直接預(yù)測
了解了遞歸預(yù)測策略后,我們來考慮一下直接預(yù)測策略。我們將建立多個單獨的模型,每個模型負(fù)責(zé)預(yù)測特定的未來時段。盡管建立許多模型會耗費一些時間,但這是機器的事情,而不是我的大腦時間。在利用 CPU 能力的同時。
接下來是整個過程的步驟:
- 模型訓(xùn)練:為每個未來時間步訓(xùn)練一個獨立的模型。例如,如果要預(yù)測未來 100 個時間段,就需要訓(xùn)練 100 個單獨的模型,每個模型負(fù)責(zé)預(yù)測各自時間步的值。
- 預(yù)測:使用每個訓(xùn)練好的模型獨立生成特定時間的預(yù)測值。這些模型可以并行運行,因為它們的預(yù)測并不相互依賴。
- 合并預(yù)測:只需將這些預(yù)測連接起來即可。
這種直接預(yù)測策略的優(yōu)勢之一是能夠捕捉每個預(yù)測范圍內(nèi)的特定模式。每個模型都可以針對其負(fù)責(zé)的時間步長進(jìn)行優(yōu)化,從而提高準(zhǔn)確性。
我們將使用與回歸器相同的 LightGBM,并使用 make_reduction(),唯一的區(qū)別是超參數(shù)是 direct 而不是 recursive。
from sktime.forecasting.compose import make_reduction
import lightgbm as lgb
lgb_regressor = lgb.LGBMRegressor(num_leaves = 10,
learning_rate = 0.02,
feature_fraction = 0.8,
max_depth = 5,
verbose = 0,
num_boost_round = 15000,
nthread = -1
)
lgb_forecaster = make_reduction(lgb_regressor, window_length=30, strategy="direct")我們將使用 100 個周期[1,2,...,100]的列表來預(yù)測范圍 (fh)。每個周期會建立一個 LightGBM 模型,總共會有 100 個模型。盡管構(gòu)建這么多 LightGBM 模型可能會花費很多時間,但我只演示 100 個周期的原因。
vlen = 100
fh=list(range(1, vlen,1))
lgb_forecaster.fit(train, fh = fh)
y_test_pred = lgb_forecaster.predict(fh=fh)
y_test_pred將繪制測試數(shù)據(jù)中的實際值與預(yù)測值的對比圖。
from sktime.utils.plotting import plot_series
plot_series(actual, y_test_pred, labels=["Actual", "Prediction"], x_label='Date', y_label='Consumption');這是因為每個預(yù)測都來自一個獨立的模型,有自己的特點。
:使用 LightGBM 的直接預(yù)測策略") 圖 (B):使用 LightGBM 的直接預(yù)測策略
圖 (B):使用 LightGBM 的直接預(yù)測策略
回顧一下評估指標(biāo):
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
print('%.16f' % mean_absolute_percentage_error(actual, y_test_pred, symmetric=False))
print('%.16f' % mean_absolute_percentage_error(actual, y_test_pred, symmetric=True))MAPE 和 sMAPE 與遞歸法的結(jié)果非常接近。
- MAPE: 0.0556899099509884
- sMAPE: 0.0564747643400997
Make_reduction()
LightGBM模型是一個監(jiān)督學(xué)習(xí)模型,需要包含x和y的數(shù)據(jù)幀來進(jìn)行模型訓(xùn)練。make_reduction()函數(shù)可以將單變量時間序列轉(zhuǎn)化為數(shù)據(jù)幀。該函數(shù)有兩個主要參數(shù),即strategy("遞歸"或"直接")和window_length(滑動窗口長度)。滑動窗口與單變量時間序列一起移動,創(chuàng)建樣本,窗口中的值就是x值。遞歸策略和直接策略將在接下來進(jìn)行解釋。
遞歸策略
遞歸策略中,滑動窗口前的值即為目標(biāo)值,圖(D)滑動 14 窗口,生成了 6 個樣本的數(shù)據(jù)幀,其中藍(lán)色的 y 值為目標(biāo)值,該數(shù)據(jù)幀用于訓(xùn)練模型。
:遞歸策略的 Make_reduction()") 圖 (D):遞歸策略的 Make_reduction()
圖 (D):遞歸策略的 Make_reduction()
直接預(yù)測策略
直接預(yù)測策略為每個未來目標(biāo)期建立一個模型。假設(shè)目標(biāo)值是 t+3 的值。圖(D)滑動 14 窗口,生成一個包含 4 個樣本的數(shù)據(jù)幀。目標(biāo)值是 t+3 中的 y 值。該數(shù)據(jù)幀用于訓(xùn)練預(yù)測 t+3 的 y 值的模型。
:針對 y_t+3 的直接策略 Make_reduction()") 圖 (E):針對 y_t+3 的直接策略 Make_reduction()
圖 (E):針對 y_t+3 的直接策略 Make_reduction()
目標(biāo)是預(yù)測 t+4 中的值。圖 (D) 滑動了 14 個窗口并生成了一個包含 3 個樣本的數(shù)據(jù)幀,用于訓(xùn)練預(yù)測 t+4 中 y 值的模型。
:針對 y_t+4 的直接策略 Mak") 圖(F):針對 y_t+4 的直接策略 Mak
圖(F):針對 y_t+4 的直接策略 Mak
使用 ARIMA 進(jìn)行多步預(yù)測
Sktime可以使用Python庫pmdarima進(jìn)行ARIMA并提供多步預(yù)測。Sktime本身不提供多步預(yù)測,但是pmdarima庫可以進(jìn)行多步預(yù)測。一旦建立了ARIMA模型,它會對預(yù)測范圍內(nèi)的每個時間點進(jìn)行提前一步預(yù)測,并且采用遞歸策略生成預(yù)測值。
!pip install pmdarima函數(shù) temporal_train_test_split()。
首先將數(shù)據(jù)分成訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)。
from sktime.forecasting.model_selection import temporal_train_test_split
train, test = temporal_train_test_split(y, train_size = 0.9)以下代碼將建立模型并提供預(yù)測。注意該代碼沒有使用 Sktime 的 make_reduction() 函數(shù)。這是因為多步預(yù)測是由 AutoARIMA 模型提供的。
from sktime.forecasting.arima import AutoARIMA
arima_model = AutoARIMA(sp=12, suppress_warnings=True)
arima_model.fit(train)
# Future horizon
vlen = 100
fh=list(range(1, vlen,1))
# Predictions
pred = arima_model.predict(fh)
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
print('%.16f' % mean_absolute_percentage_error(test, pred, symmetric=False))Sktime 簡介
Sktime是一個開源的Python庫,集成了許多預(yù)測工具,包括時間序列預(yù)測、分類、聚類和異常檢測的工具和算法。它提供了一系列主要功能,包括時間序列數(shù)據(jù)預(yù)處理、時間序列預(yù)測、時間序列分類和聚類,以及時間序列注釋。
- 時間序列數(shù)據(jù)預(yù)處理:包括缺失值處理、歸因和轉(zhuǎn)換。
- 時間序列預(yù)測:它包括常見的時間序列建模算法,我將在下一段列出。
- 時間序列分類和聚類:它包括時間序列 k-nearest neighbors (k-NN) 等分類模型和時間序列 k-means 等聚類模型。
- 時間序列注釋:它允許對時間序列數(shù)據(jù)進(jìn)行標(biāo)注和注釋,這對異常檢測和事件檢測等任務(wù)非常有用。
Sktime包括一些常見的時間序列建模算法,如指數(shù)平滑 (ES)、經(jīng)典自回歸綜合移動平均 (ARIMA) 和季節(jié)性 ARIMA (SARIMA) 模型,以及向量自回歸(VAR)、向量誤差修正模型(VECM)、結(jié)構(gòu)時間序列(STS)模型等結(jié)構(gòu)模型。此外,它還可以處理神經(jīng)網(wǎng)絡(luò)模型,包括時間卷積神經(jīng)網(wǎng)絡(luò)(CNN)、全連接神經(jīng)網(wǎng)絡(luò)(FCN)、長短期記憶全卷積網(wǎng)絡(luò)(LSTM-FCN)、多尺度注意力卷積神經(jīng)網(wǎng)絡(luò)(MACNN)、時間遞歸神經(jīng)網(wǎng)絡(luò)(RNN)和時間卷積神經(jīng)網(wǎng)絡(luò)(CNN)。
結(jié)論
本章介紹了單步預(yù)測到多步預(yù)測的建模策略,包括遞歸預(yù)測和 n 期直接預(yù)測兩種方法。我們還學(xué)習(xí)了 Python 軟件包 "sktime",它支持輕松執(zhí)行這兩種策略。除了演示的 LightGBM 模型外,我們也可以使用其他模型,如 ARIMA、線性回歸、GBM 或 XGB 作為回歸因子。