DriveWorld:一個預訓練模型大幅提升檢測+地圖+跟蹤+運動預測+Occ多個任務性能
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
寫在前面
以視覺為中心的自動駕駛技術近期因其較低的成本而引起了廣泛關注,而預訓練對于提取通用表示至關重要。然而,當前的以視覺為中心的預訓練通常依賴于2D或3D預訓練任務,忽視了自動駕駛作為4D場景理解任務的時序特征。這里通過引入一個基于世界模型的自動駕駛4D表示學習框架“DriveWorld”來解決這一挑戰,該框架能夠從多攝像頭駕駛視頻中以時空方式進行預訓練。具體來說,提出了一個用于時空建模的記憶狀態空間模型,它由一個動態記憶庫模塊組成,用于學習時間感知的潛在動態以預測未來變化,以及一個靜態場景傳播模塊,用于學習空間感知的潛在靜態以提供全面的場景上下文。此外,還引入了一個任務提示,以解耦用于各種下游任務的任務感知特征。實驗表明,DriveWorld在各種自動駕駛任務上取得了令人鼓舞的結果。當使用OpenScene數據集進行預訓練時,DriveWorld在3D檢測中實現了7.5%的mAP提升,在線地圖中的IoU提升了3.0%,多目標跟蹤中的AMOTA提升了5.0%,運動預測中的minADE降低了0.1m,占用預測中的IoU提升了3.0%,規劃中的平均L2誤差減少了0.34m。
領域背景
自動駕駛是一項復雜的任務,它依賴于全面的4D場景理解。這要求獲得一個穩健的時空表示,能夠處理涉及感知、預測和規劃的任務。由于自然場景的隨機性、環境的部分可觀察性以及下游任務的多樣性,學習時空表示極具挑戰性。預訓練在從大量數據中獲取通用表示方面起著關鍵作用,使得能夠構建出包含共同知識的基礎模型。然而,自動駕駛中時空表示學習的預訓練研究仍然相對有限。
我們的目標是利用世界模型來處理以視覺為中心的自動駕駛預訓練中的4D表示。世界模型在表示代理對其環境的時空知識方面表現出色。在強化學習中,DreamerV1、DreamerV2和DreamerV3利用世界模型將代理的經驗封裝在預測模型中,從而促進了廣泛行為的習得。MILE利用3D幾何作為歸納偏差,直接從專家演示的視頻中學習緊湊的潛在空間,以在CARLA模擬器中構建世界模型。ContextWM和SWIM利用豐富的野外視頻對世界模型進行預訓練,以增強下游視覺任務的高效學習。最近,GAIA-1和DriveDreamer構建了生成性的世界模型,利用視頻、文本和動作輸入,使用擴散模型創建逼真的駕駛場景。與上述關于世界模型的先前工作不同,本文的方法主要側重于利用世界模型學習自動駕駛預訓練中的4D表示。
駕駛本質上涉及與不確定性的斗爭。在模糊的自動駕駛場景中,存在兩種類型的不確定性:偶然不確定性,源于世界的隨機性;以及認知不確定性,源于不完美的知識或信息。如何利用過去的經驗來預測可能的未來狀態,并估計自動駕駛中缺失的世界狀態信息仍然是一個未解決的問題。本文探索了通過世界模型進行4D預訓練以處理偶然不確定性和認知不確定性。具體來說,設計了記憶狀態空間模型,從兩個方面減少自動駕駛中的不確定性。首先,為了處理偶然不確定性,我們提出了動態記憶庫模塊,用于學習時間感知的潛在動態以預測未來狀態。其次,為了緩解認知不確定性,我們提出了靜態場景傳播模塊,用于學習空間感知的潛在靜態特征,以提供全面的場景上下文。此外,引入了任務提示(Task Prompt),它利用語義線索作為提示,以自適應地調整特征提取網絡,以適應不同的下游駕駛任務。
為了驗證提出的4D預訓練方法的性能,在nuScenes訓練集和最近發布的大規模3D占用率數據集OpenScene上進行了預訓練,隨后在nuScenes訓練集上進行了微調。實驗結果表明,與2D ImageNet預訓練、3D占用率預訓練和知識蒸餾算法相比,4D預訓練方法具有顯著優勢。4D預訓練算法在以視覺為中心的自動駕駛任務中表現出極大的改進,包括3D檢測、多目標跟蹤、在線建圖、運動預測、占用率預測和規劃。
網絡結構
DriveWorld的總體框架如下所示,由于自動駕駛嚴重依賴于對4D場景的理解,方法首先涉及將多攝像頭圖像轉換為4D空間。在所提出的時空建模的記憶狀態空間模型中,有兩個基本組件:動態記憶庫,它學習時間感知的潛在動態以預測未來狀態;以及靜態場景傳播,它學習空間感知的潛在靜態特征以提供全面的場景上下文。這種配置有助于解碼器為當前和未來時間步重建3D占用和動作的任務。此外,基于預訓練的文本編碼器設計了任務prompt,以自適應地為各種任務解耦任務感知特征。
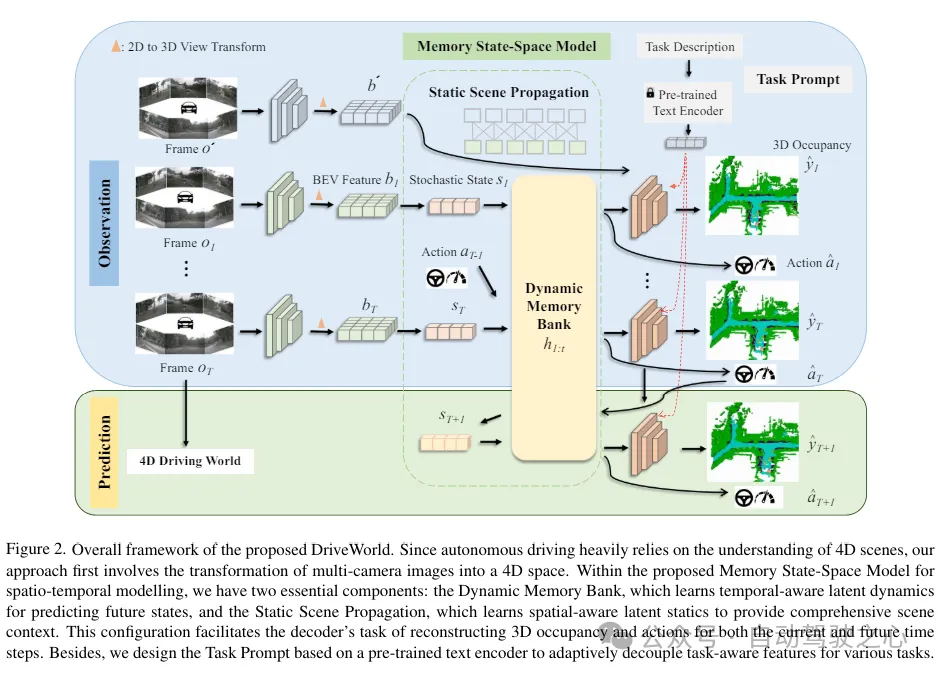
提出的記憶狀態空間模型(MSSM)的總體架構。MSSM將傳輸的信息分為兩類:時間感知信息和空間感知信息。動態記憶庫模塊利用運動感知層歸一化(MLN)來編碼時間感知屬性,并與動態更新的記憶庫進行信息交互。同時,靜態場景傳播模塊使用BEV特征來表示空間感知的潛在靜態信息,這些信息直接被傳送到解碼器。

雖然通過世界模型設計的預訓練任務使得時空表示的學習成為可能,但不同的下游任務側重于不同的信息。例如,3D檢測任務強調當前的空間感知信息,而未來預測任務則優先考慮時間感知信息。過分關注未來的信息,如車輛未來的位置,可能會對3D檢測任務產生不利影響。為了緩解這個問題,受到少樣本圖像識別中語義提示和多任務學習中視覺示例驅動的提示的啟發,引入了“任務提示”的概念,為不同的頭提供特定的線索,以指導它們提取任務感知特征。認識到不同任務之間存在的語義聯系,利用大型語言模型來構建這些任務提示。
損失函數
DriveWorld的預訓練目標涉及最小化后驗和先驗狀態分布之間的差異(即Kullback-Leibler(KL)散度),以及最小化與過去和未來3D占用,即CrossEntropy損失(CE)和L1損失。這里描述了模型在T個時間步上觀察輸入,然后預測未來L步的3D占用和動作。DriveWorld的總損失函數是:

實驗對比分析
數據集。在自動駕駛數據集nuScenes 和最大規模的3D占用數據集OpenScene 上進行預訓練,并在nuScenes上進行微調。評估設置與UniAD 相同。
預訓練。與BEVFormer 和UniAD 一致,使用ResNet101-DCN 作為基礎骨干網絡。對于3D占用預測,設置了16 × 200 × 200的體素大小。學習率設置為2×10?4。默認情況下,預訓練階段包含24個epoch。
微調。在微調階段,保留用于生成BEV特征的預訓練編碼器,并對下游任務進行微調。對于3D檢測任務,我們使用了BEVFormer 框架,微調其參數而不凍結編碼器,并進行了24個epoch的訓練。對于其他自動駕駛任務,我們使用了UniAD 框架,并將我們微調后的BEVFormer權重加載到UniAD中,對所有任務遵循標準的20個epoch的訓練協議。對于UniAD,我們遵循其實驗設置,這包括在第一階段訓練6個epoch,在第二階段訓練20個epoch。實驗使用8個NVIDIA Tesla A100 GPU進行。

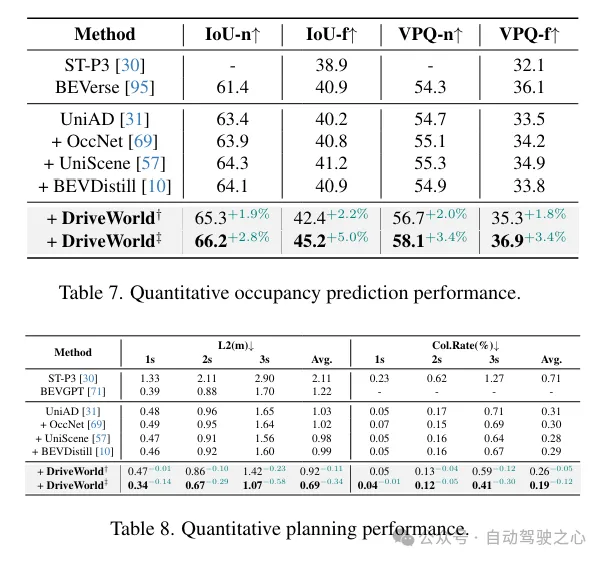
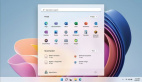
Occ任務和BEV-OD任務上的提升一覽:

更多目標跟蹤和規劃任務性能提升一覽: