一文帶你了解大數據基石-Hadoop

當前的互聯網的時代,信息爆炸的年代,抓住了風口那么距離成功也就走了一半啦!這個風口如何抓住我不知道,但是如何分析用戶的喜好以及其他行為卻是唾手可得的,用戶的行為如何存儲如何分析就是本文的下面要講的知識點。
那么為什么要用到本文提到的hadoop組件,這里啰嗦兩句,因為信息爆炸必然會帶來海量的數據,那么單機服務器勢必會造成存儲以及計算瓶頸,那么hadoop組件就是在做這兩件事情的。
hadoop之分布式存儲HDFS
首先呢,這個HDFS的設計靈感來自google的GFS論文,設計的目的 就是應付海量的數據存儲(PB|TB)
HDFS有如下特點:
- HDFS適合處理大規模數據,如:TB和PB,可以處理百萬規模以上的文件數量,使用場景是一次寫入、多次讀取場景。
- HDFS將文件線性按字節切分成多個block塊進行存儲,每個block塊默認128M。
- 每個block塊默認有3個副本,提高容錯性,如果一個副本丟失不可用,后續可以自動恢復。
- HDFS適合大文件寫入,不適合大量小文件寫入,因為小文件多NameNode要使用更多內存來維護存儲文件目錄和block信息。此外,讀取大量小文件時,文件尋址時間要大于文件讀取時間,違反HDFS設計目標。
- HDFS不支持并發寫入數據,一個文件只能有一個寫,不能多個線程同時寫。
- HDFS數據寫入后不支持修改,只支持append追加。
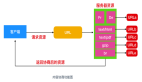
HDFS是一個主從(Master/Slaves)架構,由一個NameNode和一些DataNode組成,下圖是HDFS架構:

HDFS 架構圖
從上圖看NameNode節點存儲所有文件的與數據信息以及地址信息充當著目錄索引的作用,SecondaryNameNode 節點則可以認為是NameNode的預備節點,DataNode節點則負責著文件以及文件副本的保存,正是有著副本以及Secondary NameNode節點的存在,保障了整個系統的高可用,下面則有一個簡單的連接HDFS的例子。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class HdfsExample {
public static void main(String[] args) {
try {
// 創建Hadoop配置對象
Configuration conf = new Configuration();
// 獲取Hadoop文件系統實例
FileSystem fs = FileSystem.get(conf);
// 定義要操作的文件路徑
String hdfsPath = "/user/hadoop/sample.txt";
Path path = new Path(hdfsPath);
// 檢查文件是否存在
boolean exists = fs.exists(path);
System.out.println("文件是否存在:" + exists);
// 在HDFS上創建一個新文件
if (!exists) {
OutputStream os = fs.create(path);
System.out.println("文件創建成功");
os.close();
}
// 將本地文件上傳到HDFS
String localFilePath = "/path/to/local/file.txt";
Path localPath = new Path(localFilePath);
fs.copyFromLocalFile(localPath, path);
System.out.println("文件上傳成功");
// 從HDFS中讀取文件內容
InputStream is = fs.open(path);
byte[] buffer = new byte[1024];
int bytesRead = is.read(buffer);
while (bytesRead > 0) {
System.out.println(new String(buffer, 0, bytesRead));
bytesRead = is.read(buffer);
}
is.close();
// 刪除HDFS上的文件
boolean deleted = fs.delete(path, false);
System.out.println("文件是否刪除成功:" + deleted);
// 關閉Hadoop文件系統實例
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}hadoop之分布式計算之MapReduce
此功能的靈感同樣是來自google的同名論文(牛逼的永遠是寫論文的呀)。
此功能模塊的牛逼之處就在于它的編程思想,那么就已worldcount實例簡單講下。
假設現在有兩個文件,數據如下,假如我們要讀取文件中的數據進行wordcount統計,那么需要進 行如下步驟。
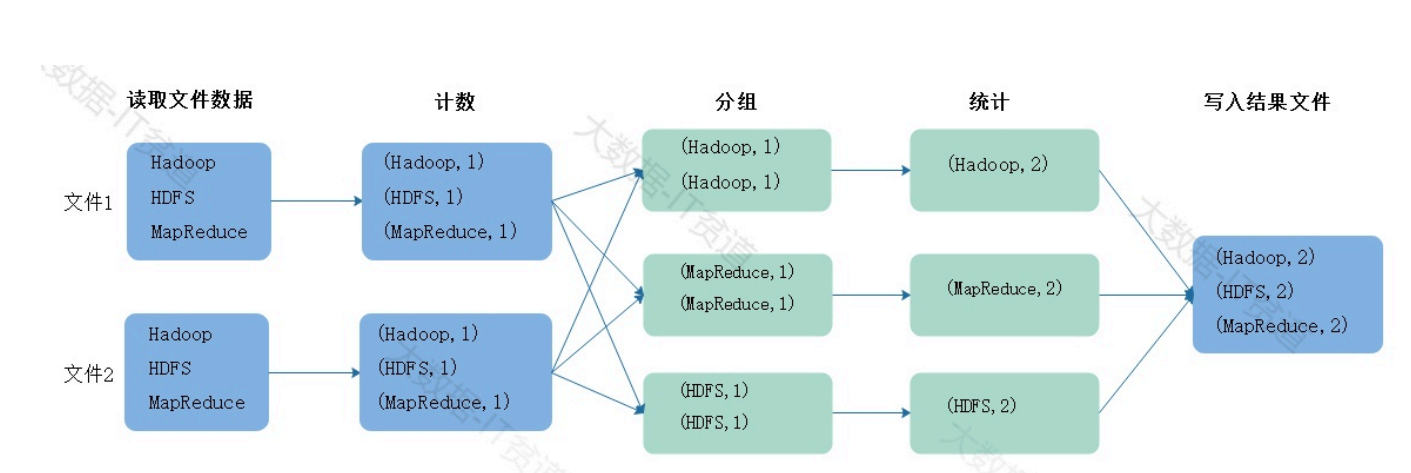
以上過程演示的就是MapReduce處理數據的大體流程,MapReduce模型由兩個主要階段組成: Map階段和Reduce階段:
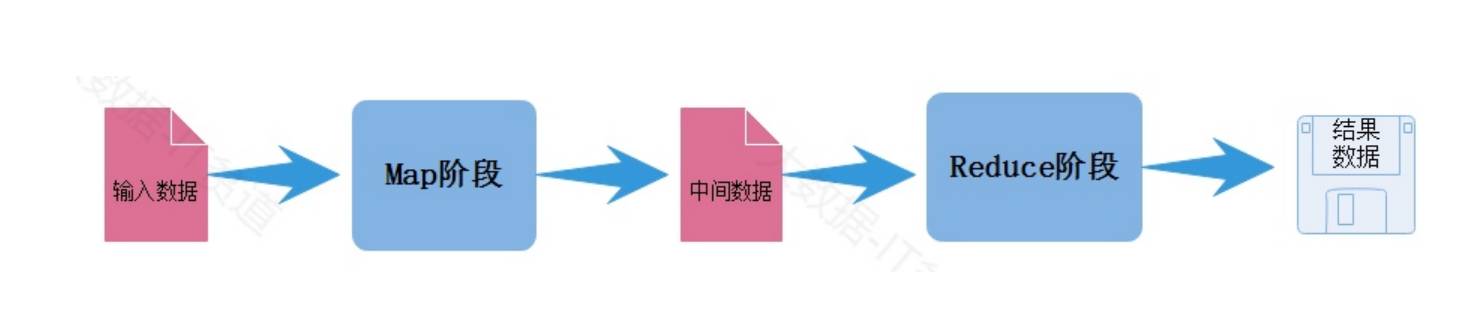
Map階段:
在Map階段中,輸入數據被分割成若干個獨立的塊,并由多個Mapper任務并行處理,每個Mapper 任務都會執行用戶定義的map函數,將輸入數據轉換成一系列鍵-值對的形式(Key-Value Pairs), 這些鍵-值對被中間存儲,以供Reduce階段使用。 Map階段主要是對數據進行映射變換,讀取一條數據可以返回一條或者多條K,V格式數據。
Reduce階段:
在Reduce階段中,所有具有相同鍵的鍵-值對會被分配到同一個Reducer任務上,Reducer任務會執 行用戶定義的reduce函數,對相同鍵的值進行聚合、匯總或其他操作,生成最終的輸出結果, Reduce階段也可以由多個Reduce Task并行執行。 Reduce階段主要對相同key的數據進行聚合,最終對相同key的數據生成一個結果,最終寫出到磁盤 文件中。
下面就是一個簡單的MapReduce代碼示例:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}