一文帶你了解什么是數據挖掘
大數據時代已經來臨,利用網絡和生活中產生的大量數據發現問題并創造價值,使得數據挖掘成了一門新的學科和技術。那么什么是大數據挖掘,數據挖掘的過程是什么,以及它的具體算法又有哪些?今天這篇文章,將帶你一起了解數據挖掘的那些事兒。
01、首先,數據挖掘到底是什么?
官方的定義,數據挖掘(Data Mining)就是從大量的、不完全的、有噪聲的、模糊的、隨機的數據中提取隱含在其中的、人們事先不知道的、但又是潛在有用的信息和知識的過程。
通俗易懂的說,數據挖掘就是從大量的數據中,發現那些我們想要的“東西”。
02 這個“東西”具體指什么?
一種被稱為預測任務。
也就是說給了一定的目標屬性,讓去預測目標的另外一特定屬性。如果該屬性是離散的,通常稱之為‘分類’,而如果目標屬性是一個連續的值,則稱之為‘回歸’。
另一種被稱為描述任務。
這是指找出數據間潛在的聯系模式。比方說兩個數據存在強關聯的關系,像大數據分析發現的一個特點:買尿布的男性通常也會買點啤酒,那么商家根據這個可以將這兩種商品打包出售來提高業績。另外一個非常重要的就是聚類分析,這也是在日常數據挖掘中應用非常非常頻繁的一種分析,旨在發現緊密相關的觀測值組群,可以在沒有標簽的情況下將所有的數據分為合適的幾類來進行分析或者降維。
其他的描述任務還有異常檢測,其過程類似于聚類的反過程,聚類將相似的數據聚合在一起,而異常檢測將離群太遠的點給剔除出來。
03 數據挖掘的一般過程包括以下幾個方面:
- 數據預處理
- 數據挖掘
- 后處理
首先來說說數據預處理。之所以有這樣一個步驟,是因為通常的數據挖掘需要涉及相對較大的數據量,這些數據可能來源不一導致格式不同,可能有的數據還存在一些缺失值或者無效值,如果不經處理直接將這些‘臟’數據放到模型中去跑,非常容易導致模型計算的失敗或者可用性很差,所以數據預處理是數據挖掘過程中都不可或缺的一步。
至于數據挖掘和后處理相對來說就容易理解多了。完成了數據的預處理,我們通常進行特征構造,然后放到特定的模型中去計算,利用某種標準去評判不同模型或組合模型的表現,最后確定一個最合適的模型用于后處理。后處理的過程相當于已經發現了那個我們想要找到的結果,然后去應用它或者用合適的方式將其表示出來。
這里涉及到數據挖掘的一系列算法,主要分為分類算法,聚類算法和關聯規則三大類,這三類基本上涵蓋了目前商業市場對算法的所有需求。而這三類里,最為經典的則是下面這十大算法。
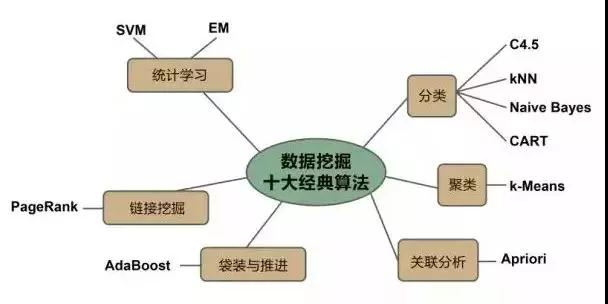
1、分類決策樹算法C4.5
C4.5,是機器學習算法中的一種分類決策樹算法,它是決策樹(決策樹,就是做決策的節點間的組織方式像一棵倒栽樹)核心算法ID3的改進算法。
2、K平均算法
K平均算法(k-means algorithm)是一個聚類算法,把n個分類對象根據它們的屬性分為k類(k
3、支持向量機算法
支持向量機(Support Vector Machine)算法,簡記為SVM,是一種監督式學習的方法,廣泛用于統計分類以及回歸分析中。
4、The Apriori algorithm
Apriori算法是一種最有影響的挖掘布爾關聯規則頻繁項集的算法,其核心是基于兩階段“頻繁項集”思想的遞推算法。其涉及到的關聯規則在分類上屬于單維、單層、布爾關聯規則。
5、最大期望(EM)算法
最大期望(EM,Expectation–Maximization)算法是在概率模型中尋找參數最大似然估計的算法,其中概率模型依賴于無法觀測的隱藏變量。最大期望經常用在機器學習和計算機視覺的數據集聚領域。
6、Page Rank算法
Page Rank根據網站的外部鏈接和內部鏈接的數量和質量,衡量網站的價值。
7、Ada Boost 迭代算法
Ada boost是一種迭代算法,其核心思想是針對同一個訓練集訓練不同的分類器(弱分類器),然后把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器)。
8、kNN 最近鄰分類算法
K最近鄰(k-Nearest Neighbor,KNN)分類算法,是一個理論上比較成熟的方法,也是最簡單的機器學習算法之一。該方法的思路是:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別。
9、Naive Bayes 樸素貝葉斯算法
Naive Bayes 算法通過某對象的先驗概率,利用貝葉斯公式計算出其后驗概率,并選擇具有最大后驗概率的類作為該對象所屬的類。樸素貝葉斯模型所需估計的參數很少,對缺失數據不太敏感,其算法也比較簡單。
10、CART: 分類與回歸樹算法。
分類與回歸樹算法(CART,Classification and Regression Trees)是分類數據挖掘算法的一種,有兩個關鍵的思想:第一個是關于遞歸地劃分自變量空間的想法;第二個想法是用驗證數據進行剪枝。
結語:
一入數據挖掘深似海,從此奮斗到天明。光是這十大算法,就夠你啃上好一段時間了......
但請不要恐慌,想想自己可以利用機器的力量、數學的力量理解世界的運行規律,去預測或者利用研究到的東西做一些有意思的事情,這也是一種不可多得的享受!
【本文為51CTO專欄作者“移動Labs”原創稿件,轉載請聯系原作者】