一文帶你了解TiDB
一、簡(jiǎn)介
TiDB并不陌生,很多團(tuán)隊(duì)都在使用,我們?yōu)槭裁匆怯盟心男┨攸c(diǎn)呢?
TiDB 是一款開源分布式關(guān)系型數(shù)據(jù)庫(kù),可以同時(shí)支持在線事務(wù)處理與在線分析處理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式數(shù)據(jù)庫(kù)產(chǎn)品,具備水平擴(kuò)容或者縮容、金融級(jí)高可用、實(shí)時(shí) HTAP、云原生的分布式數(shù)據(jù)庫(kù)、兼容 MySQL 5.7 協(xié)議和 MySQL 生態(tài)等重要特性,支持在本地和云上部署。
從中可以看到TiDB有如下特性:
- 同時(shí)支持OLTP和OLAP
- 分布式數(shù)據(jù)庫(kù),金融級(jí)別高可用
- 完全兼容MySQL,無縫切換
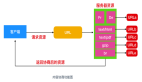
二、TiDB結(jié)構(gòu)介紹
整體架構(gòu)圖(以下用圖來自TiDB官方文檔&借鑒知乎)

2.1 TiDB Server
SQL 層,對(duì)外暴露 MySQL 協(xié)議的連接 endpoint,負(fù)責(zé)接受客戶端的連接,執(zhí)行鑒權(quán)、 SQL 解析和優(yōu)化,最終生成分布式執(zhí)行計(jì)劃。TiDB 層本身是無狀態(tài)的,實(shí)踐中可以啟動(dòng)多個(gè) TiDB 實(shí)例,通過負(fù)載均衡組件(如 LVS、HAProxy 或 F5)對(duì)外提供統(tǒng)一的接入地址,客戶端的連接可以均勻地分?jǐn)傇诙鄠€(gè) TiDB 實(shí)例上以達(dá)到負(fù)載均衡的效果。TiDB Server 本身并不存儲(chǔ)數(shù)據(jù),只是解析 SQL,將實(shí)際的數(shù)據(jù)讀取請(qǐng)求轉(zhuǎn)發(fā)給底層的存儲(chǔ)節(jié)點(diǎn) TiKV(或 TiFlash)。
2.2 PD (Placement Driver) Server
整個(gè) TiDB 集群的元信息管理模塊,負(fù)責(zé)存儲(chǔ)每個(gè) TiKV 節(jié)點(diǎn)實(shí)時(shí)的數(shù)據(jù)分布情況和集群的整體拓?fù)浣Y(jié)構(gòu),提供 TiDB Dashboard 管控界面,并為分布式事務(wù)分配事務(wù) ID。PD 不僅存儲(chǔ)元信息,同時(shí)還會(huì)根據(jù) TiKV 節(jié)點(diǎn)實(shí)時(shí)上報(bào)的數(shù)據(jù)分布狀態(tài),下發(fā)數(shù)據(jù)調(diào)度命令給具體的 TiKV 節(jié)點(diǎn),可以說是整個(gè)集群的“大腦”。此外,PD是無狀態(tài)的,通過raft一致性協(xié)議完成數(shù)據(jù)同步, 本身也是由至少 3 個(gè)節(jié)點(diǎn)構(gòu)成,擁有高可用的能力,建議部署奇數(shù)個(gè) PD 節(jié)點(diǎn)。
2.3 存儲(chǔ)節(jié)點(diǎn)(TiKV&TiFLASH)
- TiKV Server
TiDB的存儲(chǔ)方式皆為KV(key-value)存儲(chǔ),一切皆KV。
負(fù)責(zé)存儲(chǔ)數(shù)據(jù),從外部看 TiKV 是一個(gè)分布式的提供事務(wù)的 Key-Value 存儲(chǔ)引擎。存儲(chǔ)數(shù)據(jù)的基本單位是 Region,每個(gè) Region 負(fù)責(zé)存儲(chǔ)一個(gè) Key Range(從 StartKey 到 EndKey 的左閉右開區(qū)間)的數(shù)據(jù),每個(gè) TiKV 節(jié)點(diǎn)會(huì)負(fù)責(zé)多個(gè) Region。TiKV 的 API 在 KV 鍵值對(duì)層面提供對(duì)分布式事務(wù)的原生支持,默認(rèn)提供了 SI (Snapshot Isolation) 的隔離級(jí)別,這也是 TiDB 在 SQL 層面支持分布式事務(wù)的核心。TiDB 的 SQL 層做完 SQL 解析后,會(huì)將 SQL 的執(zhí)行計(jì)劃轉(zhuǎn)換為對(duì) TiKV API 的實(shí)際調(diào)用。所以,數(shù)據(jù)都存儲(chǔ)在 TiKV 中。另外,TiKV 中的數(shù)據(jù)都會(huì)自動(dòng)維護(hù)多副本(默認(rèn)為三副本),天然支持高可用和自動(dòng)故障轉(zhuǎn)移,副本質(zhì)檢也是通過raft協(xié)議維持?jǐn)?shù)據(jù)一致。
- TiFlash
TiFlash 是一類特殊的存儲(chǔ)節(jié)點(diǎn)。和普通 TiKV 節(jié)點(diǎn)不一樣的是,在 TiFlash 內(nèi)部數(shù)據(jù)是以列式的形式進(jìn)行存儲(chǔ),主要的功能是為分析型即OLAP場(chǎng)景加速。一般TiDB作數(shù)據(jù)庫(kù)使用OLTP功能,無需部署該節(jié)點(diǎn)。

- TiDB與MySQL差異
截止到TiDB4.0版本,與MySQL有如下差異(圖片引自知乎)

三、TiDB存儲(chǔ)介紹
作為保存數(shù)據(jù)的系統(tǒng),首先要決定的是數(shù)據(jù)的存儲(chǔ)模型,也就是數(shù)據(jù)以什么樣的形式保存下來。TiKV 的選擇是 Key-Value 模型,并且提供有序遍歷方法。
TiKV 數(shù)據(jù)存儲(chǔ)的兩個(gè)關(guān)鍵點(diǎn):
這是一個(gè)巨大的 Map,也就是存儲(chǔ)的是 Key-Value Pairs(鍵值對(duì))
這個(gè) Map 中的 Key-Value pair 按照 Key 的二進(jìn)制順序有序,也就是可以 Seek 到某一個(gè) Key 的位置,然后不斷地調(diào)用 Next 方法以遞增的順序獲取比這個(gè) Key 大的 Key-Value。
3.1 持久化使用RocksDB
任何持久化的存儲(chǔ)引擎,數(shù)據(jù)終歸要保存在磁盤上,TiKV 也不例外。但是 TiKV 沒有選擇直接向磁盤上寫數(shù)據(jù),而是把數(shù)據(jù)保存在 RocksDB 中,具體的數(shù)據(jù)落地由 RocksDB 負(fù)責(zé)。這個(gè)選擇的原因是開發(fā)一個(gè)單機(jī)存儲(chǔ)引擎工作量很大,特別是要做一個(gè)高性能的單機(jī)引擎,需要做各種細(xì)致的優(yōu)化,而 RocksDB 是由 Facebook 開源的一個(gè)非常優(yōu)秀的單機(jī) KV 存儲(chǔ)引擎,可以滿足 TiKV 對(duì)單機(jī)引擎的各種要求。這里可以簡(jiǎn)單的認(rèn)為 RocksDB 是一個(gè)單機(jī)的持久化 Key-Value Map。
- Region
為了實(shí)現(xiàn)存儲(chǔ)的水平擴(kuò)展,數(shù)據(jù)將被分散在多臺(tái)機(jī)器上。對(duì)于一個(gè) KV 系統(tǒng),將數(shù)據(jù)分散在多臺(tái)機(jī)器上有兩種比較典型的方案:
Hash:按照 Key 做 Hash,根據(jù) Hash 值選擇對(duì)應(yīng)的存儲(chǔ)節(jié)點(diǎn)。
Range:按照 Key 分 Range,某一段連續(xù)的 Key 都保存在一個(gè)存儲(chǔ)節(jié)點(diǎn)上。
TiKV 選擇了第二種方式,將整個(gè) Key-Value 空間分成很多段,每一段是一系列連續(xù)的 Key,將每一段叫做一個(gè) Region,并且會(huì)盡量保持每個(gè) Region 中保存的數(shù)據(jù)不超過一定的大小,目前在 TiKV 中默認(rèn)是 96MB。每一個(gè) Region 都可以用 [StartKey,EndKey) 這樣一個(gè)左閉右開區(qū)間來描述。

將數(shù)據(jù)劃分成 Region 后,TiKV 將會(huì)做兩件重要的事情:
- 以 Region 為單位,將數(shù)據(jù)分散在集群中所有的節(jié)點(diǎn)上,并且盡量保證每個(gè)節(jié)點(diǎn)上服務(wù)的 Region 數(shù)量差不多。
- 以 Region 為單位做 Raft 的復(fù)制和成員管理。
以 Region 為單位做數(shù)據(jù)的分散和復(fù)制,TiKV 就成為了一個(gè)分布式的具備一定容災(zāi)能力的 KeyValue 系統(tǒng),不用再擔(dān)心數(shù)據(jù)存不下,或者是磁盤故障丟失數(shù)據(jù)的問題。

3.2 TiDB索引介紹
- 表數(shù)據(jù)與key-value的映射
TiDB的存儲(chǔ)方式key-value的鍵值對(duì),為了方便查找在設(shè)計(jì)上做了如下優(yōu)化:
為同一張表設(shè)計(jì)一個(gè)表id,用TableID表示,整數(shù)且全局唯一
為每一張表的每一行設(shè)計(jì)一個(gè)行id,用RowId表示,整數(shù)且同一張表內(nèi)唯一。這里還有個(gè)小優(yōu)化,如果這張表有主鍵,則TiDB把主鍵作為RowId,否則自行分配一個(gè)。
映射結(jié)構(gòu)示例:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
其中,tablePrefix、recordPrefixSep都是固定的常量,為了在key空間內(nèi)區(qū)分其他數(shù)據(jù)。
- 索引與key-value的映射
TiDB索引支持主鍵索引(MySQL主鍵索引)和二級(jí)索引(MySQL平臺(tái)非聚簇索引,分唯一索引和非唯一索引),它和表與key-value的映射方式相似,也會(huì)分配一個(gè)全局唯一整數(shù)索引id,使用IndexId表示。
對(duì)于主鍵索引和唯一索引,由于列的數(shù)據(jù)是唯一的,因此對(duì)應(yīng)的key-value的結(jié)構(gòu)如下:
Key:tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue Value:RowID
其中indexedColumnsValue表示查詢列的值,最終是列值對(duì)應(yīng)一個(gè)RowId
對(duì)于非唯一索引,由于列的數(shù)據(jù)不唯一,一個(gè)鍵值可能對(duì)應(yīng)多行,需要根據(jù)鍵值范圍查詢對(duì)應(yīng)的 RowID。因此,按照如下規(guī)則編碼成 (Key, Value) 鍵值對(duì):
Key:tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID} Value:null
這里需要注意的是,value是null,并不是RowID,而RowID是拼接在key的結(jié)尾的。這里為什么不把value設(shè)計(jì)為RowID呢?猜測(cè)是因?yàn)閗ey是不能夠重復(fù)的,要全局唯一,而且要均勻分布在TiKV的各個(gè)節(jié)點(diǎn),只能把RowID拼接在key的結(jié)尾處,而且查詢的時(shí)候是根據(jù)鍵值RowID前面的范圍來查詢。
- 索引示例
上述所有編碼規(guī)則中的 tablePrefix、recordPrefixSep? 和 indexPrefixSep 都是字符串常量,用于在 Key 空間內(nèi)區(qū)分其他數(shù)據(jù),定義如下:
另外請(qǐng)注意,上述方案中,無論是表數(shù)據(jù)還是索引數(shù)據(jù)的 Key 編碼方案,一個(gè)表內(nèi)所有的行都有相同的 Key 前綴,一個(gè)索引的所有數(shù)據(jù)也都有相同的前綴。這樣具有相同的前綴的數(shù)據(jù),在 TiKV 的 Key 空間內(nèi),是排列在一起的。因此只要小心地設(shè)計(jì)后綴部分的編碼方案,保證編碼前和編碼后的比較關(guān)系不變,就可以將表數(shù)據(jù)或者索引數(shù)據(jù)有序地保存在 TiKV 中。采用這種編碼后,一個(gè)表的所有行數(shù)據(jù)會(huì)按照 RowID? 順序地排列在 TiKV 的 Key 空間中,某一個(gè)索引的數(shù)據(jù)也會(huì)按照索引數(shù)據(jù)的具體的值(編碼方案中的 indexedColumnsValue)順序地排列在 Key 空間內(nèi)。
通過一個(gè)簡(jiǎn)單的例子,來理解 TiDB 的 Key-Value 映射關(guān)系。假設(shè) TiDB 中有如下這個(gè)表:
假設(shè)該表中有4行數(shù)據(jù):
首先每行數(shù)據(jù)都會(huì)映射為一個(gè) (Key, Value) 鍵值對(duì),同時(shí)該表有一個(gè) int? 類型的主鍵,所以 RowID? 的值即為該主鍵的值。假設(shè)該表的 TableID 為 10,則其存儲(chǔ)在 TiKV 上的表數(shù)據(jù)為:
除了主鍵外,該表還有一個(gè)非唯一的普通二級(jí)索引 idxAge?,假設(shè)這個(gè)索引的 IndexID 為 1,則其存儲(chǔ)在 TiKV 上的索引數(shù)據(jù)為:
四、TiDB執(zhí)行計(jì)劃查看
4.1 概覽
由于TiDB除了協(xié)議上與MySQL兼容之外,其余的林林總總都有著自己獨(dú)特的實(shí)現(xiàn),尤其是最核心的存儲(chǔ)實(shí)現(xiàn)方式更是天差地別,因此查看執(zhí)行計(jì)劃也是完全不一樣的,以一個(gè)簡(jiǎn)單SQL為例來解析說明TiDB執(zhí)行計(jì)劃的含義。
SQL:

執(zhí)行計(jì)劃(SQL1):

執(zhí)行計(jì)劃(SQL3):

首先,create_time列上加了普通二級(jí)索引。先介紹各個(gè)列的含義:
- id 為算子名,或執(zhí)行 SQL 語句需要執(zhí)行的子任務(wù)。
- estRows 為顯示 TiDB 預(yù)計(jì)會(huì)處理的行數(shù)。該預(yù)估數(shù)可能基于字典信息(例如訪問方法基于主鍵或唯一鍵),或基于 CMSketch 或直方圖等統(tǒng)計(jì)信息估算而來(說了這么多,其實(shí)就是和MySQL執(zhí)行計(jì)劃的rows類似)。
- task 顯示算子在執(zhí)行語句時(shí)的所在位置。
- access object 顯示被訪問的表、分區(qū)和索引。顯示的索引為部分索引。以上示例中 TiDB 使用了 a 列的索引。尤其是在有組合索引的情況下,該字段顯示的信息很有參考意義。
- operator info 顯示訪問表、分區(qū)和索引的其他信息。
4.2 詳細(xì)介紹
4.2.1 算子
算子是為返回查詢結(jié)果而執(zhí)行的特定步驟。真正執(zhí)行掃表(讀盤或者讀 TiKV Block Cache)操作的算子有如下幾類:
- TableFullScan:全表掃描。
- TableRangeScan:帶有范圍的表數(shù)據(jù)掃描。
- TableRowIDScan:根據(jù)上層傳遞下來的 RowID 掃描表數(shù)據(jù)。時(shí)常在索引讀操作后檢索符合條件的行。
- IndexFullScan:另一種“全表掃描”,掃的是索引數(shù)據(jù),不是表數(shù)據(jù)。
- IndexRangeScan:帶有范圍的索引數(shù)據(jù)掃描操作。
TiDB 會(huì)匯聚 TiKV/TiFlash 上掃描的數(shù)據(jù)或者計(jì)算結(jié)果,這種“數(shù)據(jù)匯聚”算子目前有如下幾類:
- TableReader:將 TiKV 上底層掃表算子 TableFullScan 或 TableRangeScan 得到的數(shù)據(jù)進(jìn)行匯總。
- IndexReader:將 TiKV 上底層掃表算子 IndexFullScan 或 IndexRangeScan 得到的數(shù)據(jù)進(jìn)行匯總。
- IndexLookUp:先匯總 Build 端 TiKV 掃描上來的 RowID,再去 Probe 端上根據(jù)這些RowID? 精確地讀取 TiKV 上的數(shù)據(jù)。Build 端是IndexFullScan? 或IndexRangeScan? 類型的算子,Probe 端是TableRowIDScan 類型的算子。
- IndexMerge:和IndexLookupReader? 類似,可以看做是它的擴(kuò)展,可以同時(shí)讀取多個(gè)索引的數(shù)據(jù),有多個(gè) Build 端,一個(gè) Probe 端。執(zhí)行過程也很類似,先匯總所有 Build 端 TiKV 掃描上來的 RowID,再去 Probe 端上根據(jù)這些 RowID 精確地讀取 TiKV 上的數(shù)據(jù)。Build 端是IndexFullScan? 或IndexRangeScan? 類型的算子,Probe 端是TableRowIDScan 類型的算子。
- 算子的執(zhí)行順序
算子的結(jié)構(gòu)是樹狀的,但在查詢執(zhí)行過程中,并不嚴(yán)格要求子節(jié)點(diǎn)任務(wù)在父節(jié)點(diǎn)之前完成。TiDB 支持同一查詢內(nèi)的并行處理,即子節(jié)點(diǎn)“流入”父節(jié)點(diǎn)。父節(jié)點(diǎn)、子節(jié)點(diǎn)和同級(jí)節(jié)點(diǎn)可能并行執(zhí)行查詢的一部分。
在SQL1示例中,│ └─IndexFullScan_15 算子為 idx_create_time(create_time) 索引中掃描并降序排序取出RowID,├─Limit_17(Build)算子拿出前10個(gè)RowID,└─TableRowIDScan_16(Probe) 算子隨后拿上面返回的RowID從表中檢索出數(shù)據(jù)。
Build 總是先于 Probe 執(zhí)行,并且 Build 總是出現(xiàn)在 Probe 前面。即如果一個(gè)算子有多個(gè)子節(jié)點(diǎn),子節(jié)點(diǎn) ID 后面有 Build 關(guān)鍵字的算子總是先于有 Probe 關(guān)鍵字的算子執(zhí)行。TiDB 在展現(xiàn)執(zhí)行計(jì)劃的時(shí)候,Build 端總是第一個(gè)出現(xiàn),接著才是 Probe 端。
- 范圍查詢
在 WHERE/HAVING/ON? 條件中,TiDB 優(yōu)化器會(huì)分析主鍵或索引鍵的查詢返回。如數(shù)字、日期類型的比較符,如大于、小于、等于以及大于等于、小于等于,字符類型的 LIKE 符號(hào)等。
若要使用索引,條件必須是 "Sargable" (Search ARGument ABLE) 的。例如條件 YEAR(date_column) < 1992? 不能使用索引,但 date_column < '1992-01-01 就可以使用索引。
推薦使用同一類型的數(shù)據(jù)以及同一類型的字符串和排序規(guī)則進(jìn)行比較,以避免引入額外的 cast 操作而導(dǎo)致不能利用索引。
可以在范圍查詢條件中使用 AND?(求交集)和 OR?(求并集)進(jìn)行組合。對(duì)于多維組合索引,可以對(duì)多個(gè)列使用條件。例如對(duì)組合索引 (a, b, c):
- 當(dāng) a? 為等值查詢時(shí),可以繼續(xù)求 b 的查詢范圍。
- 當(dāng) b? 也為等值查詢時(shí),可以繼續(xù)求 c 的查詢范圍。
- 反之,如果 a? 為非等值查詢,則只能求 a 的范圍。
4.2.2 task簡(jiǎn)介
目前 TiDB 的計(jì)算任務(wù)分為兩種不同的 task:cop task 和 root task。Cop task 是指使用 TiKV 中的 Coprocessor 執(zhí)行的計(jì)算任務(wù),root task 是指在 TiDB 中執(zhí)行的計(jì)算任務(wù)。
SQL 優(yōu)化的目標(biāo)之一是將計(jì)算盡可能地下推到 TiKV 中執(zhí)行。TiKV 中的 Coprocessor 能支持大部分 SQL 內(nèi)建函數(shù)(包括聚合函數(shù)和標(biāo)量函數(shù))、SQL LIMIT 操作、索引掃描和表掃描。但是,所有的 Join 操作都只能作為 root task 在 TiDB 上執(zhí)行。
4.2.3 operator info簡(jiǎn)介
EXPLAIN? 返回結(jié)果中 operator info? 列可顯示諸如條件下推等信息。本文以上示例中,operator info 結(jié)果各字段解釋如下:
- range: [1,1]? 表示查詢的 WHERE? 字句 (a = 1?) 被下推到了 TiKV,對(duì)應(yīng)的 task 為 cop[tikv]。
- keep order:false? 表示該查詢的語義不需要 TiKV 按順序返回結(jié)果。如果查詢指定了排序(例如 SELECT * FROM t WHERE a = 1 ORDER BY id?),該字段的返回結(jié)果為 keep order:true。
- stats:pseudo? 表示 estRows? 顯示的預(yù)估數(shù)可能不準(zhǔn)確。TiDB 定期在后臺(tái)更新統(tǒng)計(jì)信息。也可以通過執(zhí)行 ANALYZE TABLE t 來手動(dòng)更新統(tǒng)計(jì)信息。
EXPLAIN? 執(zhí)行后,不同算子返回不同的信息。你可以使用 Optimizer Hints 來控制優(yōu)化器的行為,以此控制物理算子的選擇。例如 /*+ HASH_JOIN(t1, t2) */ 表示優(yōu)化器將使用 Hash Join 算法。
4.2.4 索引總結(jié)
SQL1中的執(zhí)行計(jì)劃:
- 算子│ └─IndexFullScan_15在TiKV操作掃描索引idx_create_time(create_time)并降序排序(operator info表明)
- 算子├─Limit_17(Build)獲取前10條(根據(jù)operator info的offset:0, count:10得知)數(shù)據(jù)的RowID
- 算子└─TableRowIDScan_16(Probe)在TiKV根據(jù)上面拿到的RowID去表中查詢數(shù)據(jù)
- 算子IndexLookUp_18在TiDB匯總結(jié)果├─Limit_17(Build)上的RowID,之后使用RowID從算子└─TableRowIDScan_16(Probe)精確查找數(shù)據(jù)
其實(shí)IndexLookUp_18這個(gè)算子作用就是匯聚作用,匯總從TableRowIDScan或TableRangeScan和 IndexFullScan 或 IndexRangeScan的數(shù)據(jù)。
SQL3中的執(zhí)行計(jì)劃:
- 算子└─IndexFullScan_19在TiKV從索引create_time索引降序排序讀取10條RowID
- 算子└─IndexReader_21在TiDB匯總數(shù)據(jù)直接返回,無需再去讀表,因?yàn)镾ELECT的字段就是索引上的
- 算子Limit_10為根算子,把結(jié)果返回客戶端
寫在最后,以上是執(zhí)行計(jì)劃,是相對(duì)粗略的結(jié)果,如果要獲取詳細(xì)的結(jié)果(帶有性能、執(zhí)行時(shí)間等),需要查看性能分析結(jié)果,方法為SQL語句前加上EXPLAIN ANALYZE,以下為SQL1的性能分析示例:

分析結(jié)果:


由于execution_info信息比較長(zhǎng),分開兩次截取。性能分析計(jì)劃相比執(zhí)行計(jì)劃多出了actRows和execution_info兩個(gè)比較重要需要常去關(guān)注的信息。actRows為實(shí)際掃描行數(shù),execution_info表明了各種執(zhí)行的細(xì)節(jié)。
五、總結(jié)
TiDB目前的使用還是很廣泛的,在很多家知名企業(yè)都有著非常成功的實(shí)踐。本文介紹了TiDB的架構(gòu)、使用的場(chǎng)景、與MySQL的兼容性、數(shù)據(jù)以及索引的存儲(chǔ)原理、執(zhí)行計(jì)劃的查看,基本涵蓋了TiDB使用的所有基礎(chǔ)性東西。當(dāng)然TiDB的復(fù)雜度遠(yuǎn)遠(yuǎn)高于文中所介紹的,其內(nèi)部的設(shè)計(jì)以及各種實(shí)現(xiàn)是相當(dāng)復(fù)雜的,非常值得細(xì)究。
通過本篇文章的介紹,希望讀者對(duì)TiDB有一個(gè)大致的了解,可以擴(kuò)充知識(shí)點(diǎn)。總結(jié)一句話,MySQL可以無縫切換到TiDB,但僅限于查詢使用,事務(wù)支持上兩者其實(shí)還有著細(xì)微的差別,并不建議從業(yè)務(wù)上直接完全替換。
參考文獻(xiàn):
TiDB 簡(jiǎn)介 | PingCAP Docs https://docs.pingcap.com/zh/tidb/stable/overview
TiDB介紹 - 知乎https://zhuanlan.zhihu.com/p/494715695