讓玩家全程掌控游戲:自然語言指令驅動的游戲引擎到來了
對于每一位熱愛打游戲的人而言,都曾經想過這樣一個問題,「這游戲要是我來做就好了!」
可惜的是,游戲開發有很高的門檻,需要專業的編程技巧。
近日,來自上海交大的團隊開展了一個名為「Instruction-Driven Game Engine, IDGE」的項目,他們針對未來游戲的開發,提出了一個酷炫的新范式:利用自然語言指令開發游戲,玩家說怎么玩就怎么玩,讓 UGC 貫穿于游戲的每個角落。
IDGE 顧名思義,是一個指令驅動型的新概念「游戲引擎」,它能夠支持用戶輸入對游戲規則的自然語言描述,來自動生成一個「玩家專屬」的游戲。

- 論文:https://arxiv.org/abs/2404.00276
- 代碼:https://github.com/gingasan/idge
- Demo:https://www.bilibili.com/video/BV1dA4m1w7xr/?vd_source=e0570b35759018455d30551c1e16a676
- 論文標題:Instruction-Driven Game Engines on Large Language Models
概述
什么是 IDGE
游戲引擎是游戲開發的核心,傳統意義上的游戲引擎由復雜的編程語言驅動。這種壁壘阻礙了游戲愛好者實現他們開發游戲的夢想。
文中提出的指令驅動游戲引擎 IDGE,讓使用者只需提供一段自然語言的指令,就能設計出新的游戲,并基于該引擎進行游玩。這種指令作者稱之為「游戲劇本(Game Script)」,它詳細描繪了用戶想要的游戲的全貌。
從對話模型到游戲引擎
IDGE 是一個基于大語言模型(LLM)的神經引擎,如今的對話式大語言模型,如 ChatGPT,能夠通過一個 system prompt 來扮演各種角色,和用戶進行對話交互。
傳統的游戲引擎也可以被看作是一個精密版的交互系統。引擎根據玩家利用編程語言實現的游戲規則,在每次玩家進行了輸入以后,都會計算一次最新的游戲狀態,并且將最新狀態渲染成游戲畫面展示給玩家。對于 IDGE 來說,其主體流程與傳統游戲引擎類似,但游戲規則是用自然語言描述而不是用編程語言編程實現,游戲狀態的計算也由 LLM 推理得到。
以大家最熟悉的石頭剪刀布為例,對于 IDGE 而言,我們實現游戲的方式是給定一段游戲劇本作為 system prompt:
現在玩一個名為石頭剪刀布的游戲,兩位玩家同時發出代表游戲元素的動作;石頭、剪刀和布。游戲的結果由 3 個簡單的規則決定:石頭戰勝剪刀;剪刀戰勝布;布戰勝石頭。如果動作相同則進入下一輪游戲。
以下是一個實際游戲的例子:
IDGE:開始剪刀石頭布,請出示你的動作
- player 1:剪刀 | player 2:剪刀 (player 1 2 發出動作階段互相不可見)
IDGE:player 1 的動作是剪刀,player 2 的動作是剪刀,游戲繼續,請出示你的動作
- player 1:剪刀 | player 2:石頭 (player 1 2 發出動作階段互相不可見)
IDGE:player 1 的動作是剪刀,player 2 的動作是石頭,player 2 獲勝,游戲結束
穩定性和多樣性的雙重挑戰
乍一看,IDGE 的運作方式跟傳統的對話模型是一樣的,用戶皆以多輪對話的形式和模型進行互動。但是,作者認為 IDGE 相比于普通的對話模型,會遇到兩大挑戰。
- 首先是穩定性(Stability)。相比于聊天,在游戲中,任何一個小問題就有可能導致整個游戲發生錯亂,因此 IDGE 的預測追求 100% 的準確率。
- 其次是多樣性(Diversity)。玩家群體十分龐大,涵蓋不同年齡、性別、以及文化上的差異,它們對游戲的偏好截然不同,描述規則的語言也差異頗大。這意味著,IDGE 要理解高度多樣的用戶輸入,同時保證游戲運行的穩定。
如何建模游戲引擎的任務
文章中,作者基于對游戲的理解,提出了一種全新任務,稱為「Next State Prediction」。相比于自然語言,由一串字符(token)定義了一句完整的話,一局完整游戲由一系列游戲中狀態(in-game state)組成,這些狀態代表了游戲當前的所有信息。因此對于一個游戲引擎來說,它的任務就是,根據之前的游戲狀態,預測下一個游戲狀態。
然而一個游戲狀態序列相比于字符序列要大得多,這很可能造成輸入的溢出。針對這種情況,作者引入了獨立性假設,即某一時刻的游戲內狀態只和此前的 1 個有關,那么問題的求解就簡化成了:

其中 z 為游戲劇本,對于一整局游戲來說是全局變量,x_t 是 t 時刻的玩家輸入。
數據生成和數據定義
除了問題的建模,如何構造數據也是 IDGE 的核心問題。
本文以撲克牌游戲作為 IDGE 的第一個探索場景。在文中,作者通過一個撲克牌模擬程序,獲取了大量的游戲日志,由此作為 IDGE 的數據來源。
游戲劇本
作者制定了一個結構化的劇本模板,如下圖所示。通過填充相應的配置參數,表達不同的游戲。
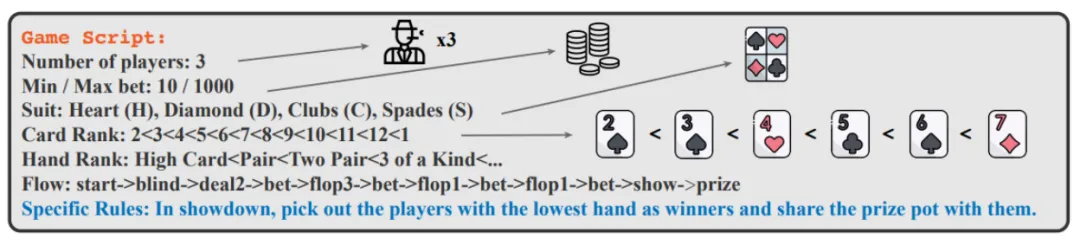
可以看到,劇本支持 7 種主要的參數:玩家人數、底注、初始籌碼、花色種類、單牌的大小排序、組合牌的大小排序、游戲流程。
除了結構化的描述,游戲劇本還包含了對某些特定游戲規則的自然語言描述,如上圖中的「Specific Rules」所示,這里的描述要求引擎把手牌最小的玩家視作為贏家,和傳統的德州撲克相反。自然語言的引入,大大增加了游戲劇本的多樣性。
游戲內狀態和玩家輸入
作者設計了一套簡潔高效的標準化語言,來表達撲克游戲中的每一個狀態,如下圖左側。
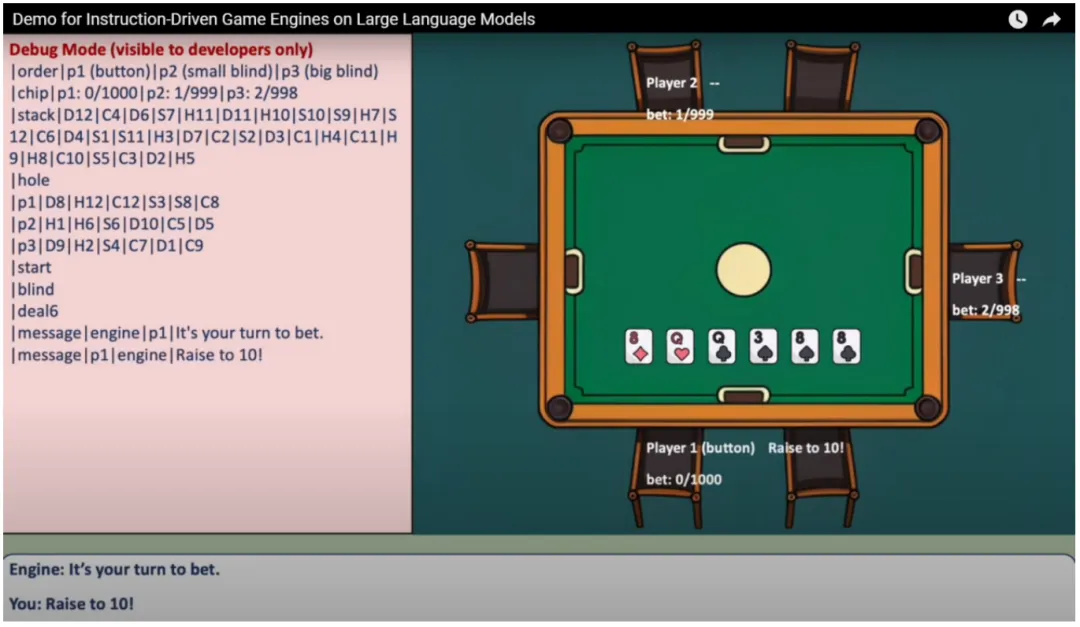
上圖為作者發布的游戲 Demo 的截圖。左側為實際游戲中引擎的游戲內狀態,右側為游戲界面。
如圖所示,作者所設計的語言以 "|" 作為分割符,可以說非常地簡潔了。
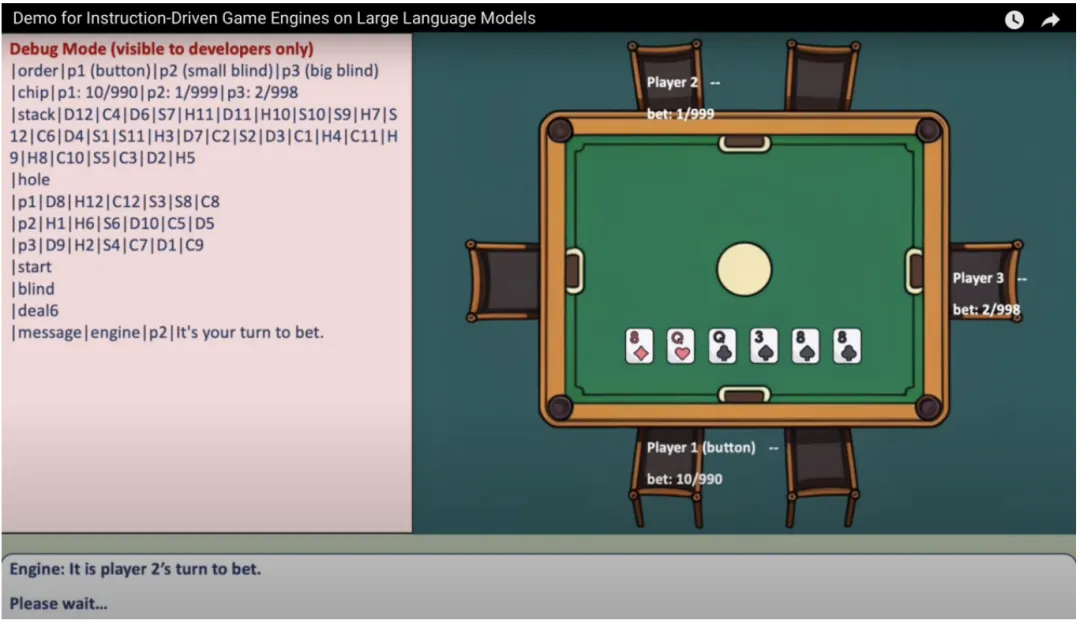
我們還可以看到,圖中里玩家 1 輸入了一條指令「Raise to 10!」,代表他要加注。因此下一個狀態則變為了下面一張圖,可以看到玩家 1 的籌碼發生了變化,由 「0/1000」變為了「10/990」。此時引擎的輸出也發生了變化,它讓玩家 2 進行下注。
數據效率
除了生成數據,作者還強調了數據的效率問題。由于模擬器是一局一局游戲生成的,那么會造成的結果是,一些出現概率較低的情況會更低,導致數據不平衡。作者提到,這是引擎(engine)相比于智能體(agent)的一個重大區別:智能體通常遵循一組特定的策略,而引擎則盡可能地保證對所有可能的策略都是無偏的。
一個直觀的例子就是撲克牌里的順子,正常來說它出現的情況遠遠低于對子。那么在這樣的數據上訓練得到的引擎,會在對子上過擬合,而在順子上欠擬合,即使訓練數據量非常大。
針對這個問題,作者給出了一個簡單的小技巧,即調整數據采樣的比例,讓所有情況盡可能地均衡。下圖左側為隨機采樣下各個牌組出現的頻率直方圖,對子和高牌要遠遠高于其它組合,而右側為均衡之后的直方圖。

訓練方法
為了使模型兼備穩定性和多樣性,作者提出了一種課程學習的方法。一次訓練分為三個階段。
預熱(Warmup)
一個游戲引擎涵蓋了多類型的任務,對于一個撲克引擎來說,它需要學會發牌、翻牌、換牌、下注等。一次性讓模型去學習大量的子任務,會帶來冷啟動問題。因此,作者提出了一個預學習過程,即讓模型先在一個稱為「核心集」(Core Set, CS)的指令微調數據集上進行預學習。核心集里包含了各種各樣的基本函數,為模型提供了一個良好的初始化。
作者提到,核心集的作用類似于傳統計算機系統的工具庫,為系統的上層功能提供支持。只不過不同的是,對于大語言模型來講,這些工具都以指令的形式存在。
標準(Standard)
預熱過后的第二階段,即讓模型在標準的引擎數據上進行微調。
多樣(Diverse)
最后一個階段也是最難的階段,模型需要超越標準數據中的結構化游戲劇本,學習理解自然語言描述的劇本。相對于人工標注大量的自然語言劇本,作者提出了一種簡單而高效的方法,稱為「片段重述」(Segment Rephrasing, SR)。具體來說,隨機采樣劇本的某些片段,用 GPT3.5 以自然語言將其重述。相比于結構化,經過重述后的游戲劇本會具有更加豐富的語言表達,更加難以理解。
這一個過程作者還利用了一個小技巧,即在經過重述后的數據上訓練的同時,采樣一定比例的標準化數據,目的是減輕模型的災難性遺忘。作者發現這有助于提高最終的穩定性。
以上三個階段,預熱、標準、多樣,對應了課程學習的三種難度等級。從訓練的角度來看,它對應著模型從標準化到指令化的遷移。
實驗結果
作者選擇了撲克牌作為測試的游戲,并設計了兩部分的實驗來驗證 IDGE 的性能。
模擬器數據
第一部分測試數據來自于撲克牌模擬器。作者借助模擬器,生成了一組測試集,涵蓋了總共 10 種撲克牌游戲的變體,分別是 Texas hold’em、5-card draw、Omaha、Short-deck hold’em、2-to-7 triple draw、A-to-5 triple draw、2-to-7 single draw、Badugi、Badeucey、以及 Badacey。
和常見的準確率不同的是,作者匯報的是每局游戲的成功率(sucess rate)。每一種類的游戲連續玩 20 局,如果一局游戲中引擎的預測全部正確,那么成功率就 + 1。結果如下:
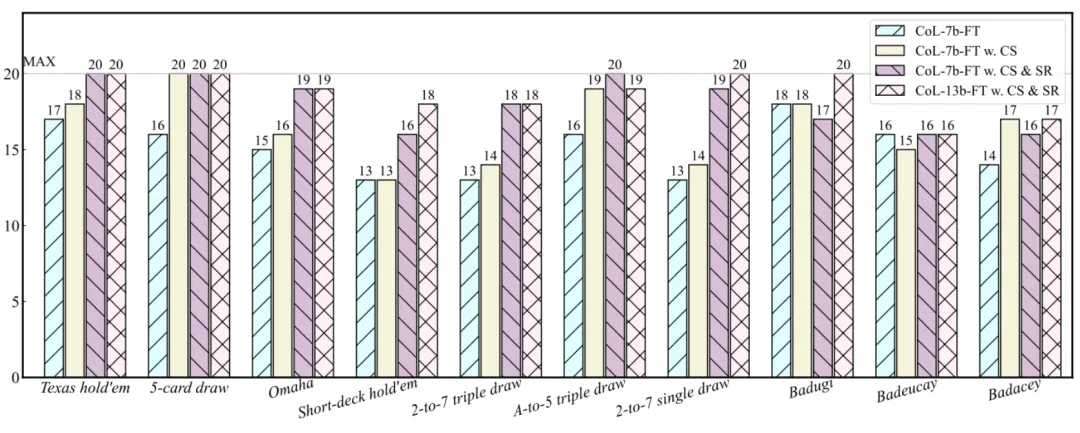
結果證明,核心集的預熱以及最后的重述,都十分利于模型的訓練。
值得注意的是,作者挑選的是 CodeLLaMA-7b/13b 來進行的實驗。他發現經過程序語言預訓練的模型表現要優于自然語言預訓練的模型。為此,他給出的解釋是:程序語言和 IDGE 的標準化數據類似,都是高度結構化的,因此 code-pre-trained LLMs 會更加擅長 IDGE。
作者還發現了一個有趣的現象,就是通過 prompt 驅動的 GPT3.5 和 GPT4 在這個任務上的成功率是 0。由此,作者做了進一步分析,將所有局的游戲狀態按照功能進行分類,得到了一個重組后測試集。
按照狀態分類后,各個模型的準確率如下:
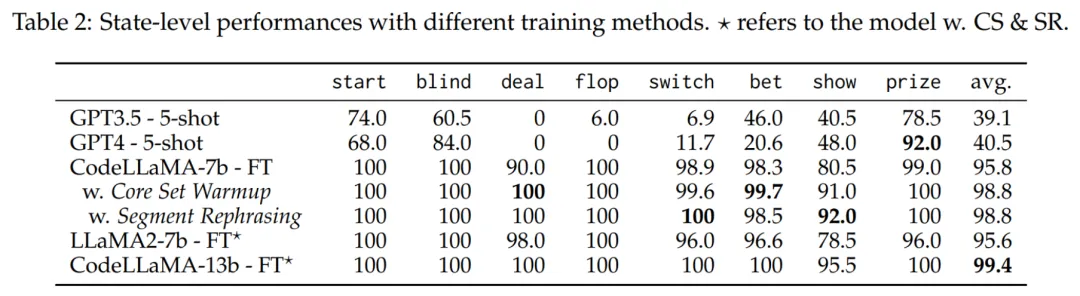
結果發現 GPT3.5/4 的數學能力表現出色(prize 指代的是計算獎池的功能)。但是,作者發現他們對牌的處理很差,例如在發牌(deal)上,準確率一直是 0。作者猜測,如今的大語言模型在訓練時很少會遇到引擎的高精度數據,因此表現不佳。這些子功能上的錯誤累計,最終會以木桶原理的方式影響引擎整體的性能。
玩家手寫數據
為了進一步驗證引擎在真實場景下的表現,作者團隊邀請了幾名真人玩家,讓他們自行發揮創意,每人用自然語言編寫一個新的游戲規則。
總共產出了如下 5 個劇本:

可以看到,從劇本 1 到劇本 5 的難度逐漸提升。劇本 5 非常具有挑戰性,定義了一個全新的 6 牌游戲,隨即新出現了兩個全新的 6 牌組合,三對(Three Pair)以及大葫蘆(Big House)。
在用戶為 IDGE 編寫游戲劇本時,還能夠通過手寫幾個樣例,來提高引擎對劇本理解的準確性。表現如下:

可以看到,對于劇本 1 至劇本 4,模型在零樣本或少樣本,能夠取得非常不錯的成績。
然而對于劇本 5,模型顯得理解起來出現了困難。對于這種情況,作者給出的解決方法是,用戶自適應!具體來說,在用戶游玩 IDGE 的時候,若發現模型給出錯誤解,手動糾正結果再送給模型。此時模型會收到一對「好」和「壞」的樣本,作者利用 DPO 進一步更新模型的參數。用戶可以持續進行這一過程,直到引擎性能令其滿意為止。
從結果來看,對于劇本 4,引擎需要 8 個樣本,在測試集上達到 100% 的準確率。而對于劇本 5,引擎收集了 23 個樣本后,達到 100% 的準確率。
這提供了給了游戲制作者和玩家們一個全新的思路:根據玩家自己的游戲反饋,定制一個私有化可定制的的個人游戲引擎!
總結與展望
本文基于大語言模型提出了一種全新的游戲引擎概念,Instruction-Driven Game Engine, IDGE。作者將游戲引擎定義為了一種自回歸式的狀態預測,Next State Prediction,并且提出了一種課程學習的訓練過程。同時,作者還提出了 IDGE 的一種可能的應用形態,自適應型的個人游戲引擎,這或將成為未來聯結游戲開發者和玩家之間的全新閉環。
作者相信這種游戲引擎適用于所有類型的游戲,但是,目前大規模應用 IDGE 還有以下限制:
- 推理延遲:大語言模型的推理很緩慢,導致目前的 IDGE 不適合于實時類的游戲,例如 RTS。
- 上下文窗口:當游戲變得更加復雜,一個游戲狀態會帶來大量的字符數,以此來滿足獨立性假設,這將對大語言模型的長期理解能力和 KV 緩存帶來挑戰。
- 游戲數據的缺乏:目前大部分商業游戲的數據都是私有化的,為此,作者將研究重點放在了撲克牌上。
作者們還相信,關于推理延遲和上下文窗口的瓶頸漸漸會隨著 LLM 相關技術的突破而被解決;而關于游戲數據的問題,作者呼吁更多公司開放游戲 API 來方便促進 AI 研究。