













3DGStream:快速訓練,200 FPS實時渲染逼真場景!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
從多視角視頻構建動態場景的照片逼真的自由視角視頻(FVV)仍然是一項具有挑戰性的工作。盡管當前的神經渲染技術取得了顯著的進步,但這些方法通常需要完整的視頻序列來進行離線訓練,并且無法實時渲染。為了解決這些限制,本文引入了3DGStream,這是一種專為真實世界動態場景的高效FVV流式傳輸而設計的方法。提出的方法在12秒內實現了快速的動態全幀重建,并以200 FPS的速度實現了實時渲染。具體來說,我們使用3D高斯(3DG)來表示場景。與直接優化每幀3DG的簡單方法不同,我們使用了一個緊湊的神經變換緩存(NTC)來對3DG的平移和旋轉進行建模,顯著減少了每個FVV幀所需的訓練時間和存儲。此外,還提出了一種自適應的3DG添加策略來處理動態場景中的新興目標。實驗表明,與現有技術相比,3DGStream在渲染速度、圖像質量、訓練時間和模型存儲方面具有競爭力。
論文鏈接:https://arxiv.org/pdf/2403.01444.pdf
論文名稱:3DGStream: On-the-fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos
代碼鏈接:https://sjojok.github.io/3dgstream/
3DGStream能夠以百萬像素的分辨率實時渲染照片逼真的FVV,具有異常快速的每幀訓練速度和有限的模型存儲要求。如圖1和圖2所示,與每幀從頭開始訓練的靜態重建方法和需要在完整視頻序列上進行離線訓練的動態重建方法相比,我們的方法在訓練速度和渲染速度方面都很出色,在圖像質量和模型存儲方面保持了競爭優勢。此外,我們的方法在所有相關方面都優于StreamRF,這是一種處理完全相同任務的最先進技術。


3DGStream方法一覽
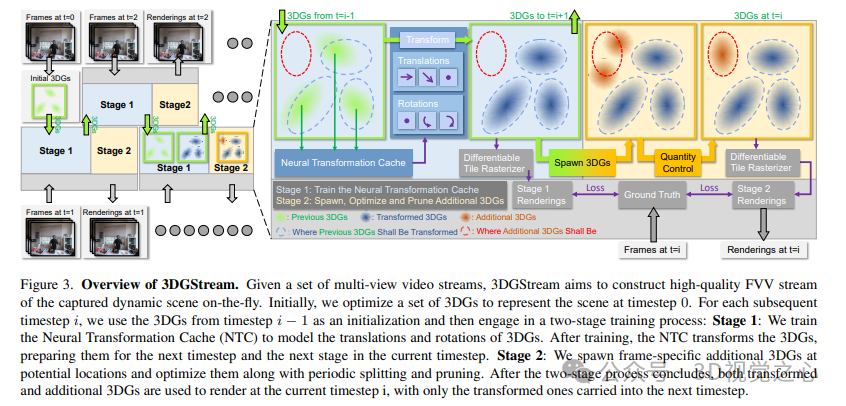
如下所示,給定一組多視角視頻流,3DGStream旨在構建動態場景的高質量FVV流。最初,優化一組3DG來表示時間步長為0的場景。對于隨后的每個時間步長i,使用時間步長i?1中的3DG作為初始化,然后進行兩階段的訓練過程:第1階段:訓練神經變換緩存(NTC)來對3DG的平移和旋轉進行建模。訓練結束后,NTC轉換3DG,為下一個時間步長和當前時間步長的下一階段做好準備。第二階段:在潛在位置生成特定于幀的附加3DG,并通過周期性拆分和修剪對其進行優化。在兩階段過程結束后,變換后的3DG和附加的3DG都被用于在當前時間步長i進行渲染,只有變換后的3D被帶入下一個時間步長。
實驗結果對比
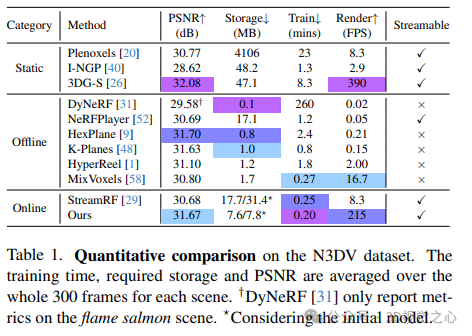
論文在兩個真實世界的動態場景數據集上進行了實驗:N3DV數據集和Meet Room數據集。N3DV數據集上的定量比較。訓練時間、所需存儲和PSNR在每個場景的整個300幀上取平均值。
Meet Room dataset性能對比:


3DG-S在初始幀上的質量對于3DGStream至關重要。因此,我們繼承了3DGS的局限性,例如對初始點云的高度依賴性。如圖7所示,由于COLMAP無法重建遠處的景觀,在窗口之外存在明顯的偽影。因此,我們的方法將直接受益于未來對3DG-S的增強。此外,為了高效的訓練,我們限制了訓練迭代次數。

主要結論
3DGStream是一種高效的自由視點視頻流的新方法。基于3DG-S,利用有效的神經變換緩存來捕捉目標的運動。此外,還提出了一種自適應3DG添加策略,以準確地對動態場景中的新興目標進行建模。3DGStream的兩級pipeline實現了視頻流中動態場景的實時重建。在確保照片逼真的圖像質量的同時,3DGStream以百萬像素的分辨率和適度的存儲空間實現了實時訓練(每幀約10秒)和實時渲染(約200FPS)。大量實驗證明了3DGStream的效率和有效性!


























