













怒斥Sora之后,LeCun放出「視覺世界模型」論文,揭示AI學(xué)習(xí)物理世界的關(guān)鍵?
Sora 的發(fā)布讓整個 AI 領(lǐng)域為之狂歡,但 LeCun 是個例外。
面對 OpenAI 源源不斷放出的 Sora 生成視頻,LeCun 熱衷于尋找其中的失誤:

歸根結(jié)底,LeCun 針對的不是 Sora,而是 OpenAI 從 ChatGPT 到 Sora 一致采用的自回歸生成式路線。
LeCun 一直認(rèn)為, GPT 系列 LLM 模型所依賴的自回歸學(xué)習(xí)范式對世界的理解非常膚淺,遠遠比不上真正的「世界模型」。
所以,一遇到「Sora 是世界模型」的說法,LeCun 就有些坐不住:「僅僅根據(jù) prompt 生成逼真視頻并不能代表一個模型理解了物理世界,生成視頻的過程與基于世界模型的因果預(yù)測完全不同。」

那么,面對視覺任務(wù),世界模型如何獲得自回歸模型一般的性能?
最近,Lecun 發(fā)布了自己關(guān)于「世界模型」的新論文《在視覺表征學(xué)習(xí)中學(xué)習(xí)和利用世界模型》,剛好解釋了這個問題。

- 論文標(biāo)題:Learning and Leveraging World Models in Visual Representation Learning
- 論文鏈接:https://arxiv.org/pdf/2403.00504.pdf
通過以往 LeCun 對世界模型的介紹,我們知道,JEPA(Joint Embedding Predictive Architecture,聯(lián)合嵌入預(yù)測架構(gòu))相比于重建像素的生成式架構(gòu)(如變分自編碼器)、掩碼自編碼器、去噪自編碼器,更能產(chǎn)生優(yōu)秀的視覺輸入表達。
2023 年 6 月,Meta 推出了首個基于 LeCun 世界模型概念的 AI 模型,名為圖像聯(lián)合嵌入預(yù)測架構(gòu)(I-JEPA),能夠通過創(chuàng)建外部世界的內(nèi)部模型來學(xué)習(xí), 比較圖像的抽象表征(而不是比較像素本身)。今年,在 Sora 發(fā)布的第二天,Meta 又推出了 AI 視頻模型 V-JEPA,可根據(jù)信號的損壞或轉(zhuǎn)換版本來預(yù)測信號的表征,讓機器通過觀察了解世界的運作方式。
而最新這項研究揭示了利用世界模型進行表征學(xué)習(xí)的另一個關(guān)鍵方面:賦予世界模型的容量直接影響所學(xué)表征的抽象程度。
直觀地說,如果預(yù)測器是身份,網(wǎng)絡(luò)將捕捉到高級語義信息,因為它只會學(xué)習(xí)編碼輸入 y 及其變換 x 之間的共同點。另一方面,由于預(yù)測器的容量更大,可以有效反轉(zhuǎn)變換的效果,編碼器的輸出可以保留更多關(guān)于輸入的信息。
這兩個理念是等變表征學(xué)習(xí)的核心,能有效應(yīng)用變換的預(yù)測器是等變的,而不能有效應(yīng)用變換的預(yù)測器是不變的。研究者發(fā)現(xiàn),對變換不變的世界模型在線性評估中表現(xiàn)更好,而等變的世界模型與更好的世界模型微調(diào)相關(guān)。這就在易適應(yīng)性和原始性能之間做出了權(quán)衡。因此,通過學(xué)習(xí)世界模型來學(xué)習(xí)表征,能靈活掌握表征的屬性,從而使其成為一個極具吸引力的表征學(xué)習(xí)框架。
接下來,我們來看一些具體的研究細(xì)節(jié)。
方法
圖像世界模型(Image World Models,IWM)采用 JEPA 的框架,類似于 I-JEPA。該框架中的預(yù)測器是世界模型的實例化。研究者認(rèn)為,如果一個世界模型能夠在潛在空間中應(yīng)用變換,從而學(xué)習(xí)等變表征,那么它就是有能力的。研究者將有能力的世界模型為等變( equivariant ),稱能力較差的世界模型為不變( invariant )。
使用 JEPA 的一個吸引人之處在于,使用對比方法學(xué)習(xí)等變表征的方法通常需要依賴于不變性損失來提高表征質(zhì)量,無論是顯式的還是隱式的。而 JEPA 的方法則不存在這一缺點,因為表征的語義方面是通過潛在空間的修補學(xué)習(xí)的。在潛空間中工作還能讓網(wǎng)絡(luò)去除不必要的信息或難以預(yù)測的信息。這就使得 JEPA 方案很有吸引力,因為對于重建方法來說,重建的質(zhì)量不一定與表征質(zhì)量相關(guān)。
要訓(xùn)練 IWM,第一步是從圖像 I 生成源視圖和目標(biāo)視圖(圖 2 中分別為 x 和 y)。

研究者將 a_x→y 表示為從 x 到 y 的變換參數(shù),即初始變換過程的逆轉(zhuǎn)。它包含了 x 與 y 之間顏色抖動差異的信息,以及是否應(yīng)用了每種破壞性增強的信息。
通過 p_? 進行世界建模。然后分別通過編碼器 f_θ 和它的指數(shù)移動平均
得到源和目標(biāo)。這樣就有了  和
和  。使用 EMA 網(wǎng)絡(luò)對避免解決方案崩潰至關(guān)重要。為了給作為世界模型的預(yù)測器設(shè)置條件,它被輸入了關(guān)于目標(biāo)的幾何信息,以掩碼 token 的形式以及 a_x→y。研究者將這些掩碼 token 稱為 m_a,它們對應(yīng)于
。使用 EMA 網(wǎng)絡(luò)對避免解決方案崩潰至關(guān)重要。為了給作為世界模型的預(yù)測器設(shè)置條件,它被輸入了關(guān)于目標(biāo)的幾何信息,以掩碼 token 的形式以及 a_x→y。研究者將這些掩碼 token 稱為 m_a,它們對應(yīng)于  中的位置。
中的位置。
然后,預(yù)測器 p_? 將嵌入的源補丁 x_c、變換參數(shù) a_x→y 和遮罩令牌 m_a 作為輸入。其目標(biāo)是匹配 p_?(z_x, a_x→y, m_a) =  到 z_y。損失。使用的損失函數(shù)是預(yù)測
到 z_y。損失。使用的損失函數(shù)是預(yù)測  及其目標(biāo) z_y 之間的平方 L2 距離:
及其目標(biāo) z_y 之間的平方 L2 距離:

學(xué)習(xí)用于表征學(xué)習(xí)的圖像世界模型
如前所述,學(xué)習(xí)等差數(shù)列表征和學(xué)習(xí)世界模型是密切相關(guān)的問題。因此,可以借用等差數(shù)學(xué)文獻中的指標(biāo)來評估訓(xùn)練好的世界模型的質(zhì)量。研究者使用的主要指標(biāo)是平均互斥等級(MRR)。
為了計算它,研究者生成了一組增強目標(biāo)圖像(實際為 256 幅)。他們通過預(yù)測器輸入干凈圖像的表征,目的是預(yù)測目標(biāo)圖像。然后計算預(yù)測結(jié)果與增強表征庫之間的距離,從中得出目標(biāo)圖像在該 NN 圖中的等級。通過對多個圖像和變換的倒數(shù)等級進行平均,就可以得到 MRR,從而了解世界模型的質(zhì)量。MRR 接近 1 意味著世界模型能夠應(yīng)用變換,相反,MRR 接近 0 則意味著世界模型不能應(yīng)用變換。
為了構(gòu)建性能良好的 IWM,研究者分離出三個關(guān)鍵方面:預(yù)測器對變換(或操作)的條件限制、控制變換的復(fù)雜性以及控制預(yù)測器的容量。如果對其中任何一個環(huán)節(jié)處理不當(dāng),都會導(dǎo)致表征不穩(wěn)定。
如表 1 所示,不進行調(diào)節(jié)會導(dǎo)致世界模型無法應(yīng)用變換,而使用序列軸或特征軸進行調(diào)節(jié)則會導(dǎo)致良好的世界模型。研究者在實踐中使用了特征調(diào)節(jié),因為它能帶來更高的下游性能。

如表 2 所示,增強越強,學(xué)習(xí)強世界模型就越容易。在更廣泛的增強方案中,這一趨勢仍在繼續(xù)。

如果變換很復(fù)雜,預(yù)測器就需要更大的能力來應(yīng)用它,意味著能力成為了學(xué)習(xí)圖像世界模型的關(guān)鍵因素。如上表 2 ,深度預(yù)測器意味著能在更廣泛的增強上學(xué)習(xí)到強大的世界模型,這也是 IWM 取得成功的關(guān)鍵。因此,預(yù)測能力是強大世界模型的關(guān)鍵組成部分。
與計算 MRR 的方法相同,我們可以將預(yù)測的表征與變換圖像庫進行比較,并查看與預(yù)測最近鄰的圖像。如圖 1 所示,IWM 學(xué)習(xí)到的世界模型能夠正確應(yīng)用潛空間中的變換。不過,可以看到灰度反轉(zhuǎn)時存在一些誤差,因為灰度無法正確反轉(zhuǎn)。
以下可視化效果有助于強化 IWM 能夠為圖像轉(zhuǎn)換學(xué)習(xí)強大的世界模型這一事實。

利用世界模型完成下游任務(wù)
論文還探討了如何使用世界模型完成下游任務(wù)。
在圖像上學(xué)習(xí)的世界模型的局限性在于,它們所解決的任務(wù)與大多數(shù)下游任務(wù)并不一致。
研究者表示,已經(jīng)證明 IWM 可以應(yīng)用色彩抖動或?qū)D像進行著色,但這些并不是推動計算機視覺應(yīng)用的任務(wù)。這與 LLM 形成了鮮明對比,在 LLM 中,預(yù)測下一個 token 是此類模型的主要應(yīng)用之一。
因此,研究者探索了如何在視覺中利用世界模型來完成應(yīng)用變換之外的任務(wù),重點是圖像分類和圖像分割等判別任務(wù)。
首先,需要對預(yù)測器進行微調(diào)以解決判別任務(wù)。研究者按照 He et al. (2021) 的方法,重點放在與微調(diào)協(xié)議的比較上。所研究的所有方法都在 ImageNet 上進行了預(yù)訓(xùn)練和評估,并使用 ViT-B/16 作為編碼器。
表 3 展示了定義預(yù)測任務(wù)的各種方法及其對性能的影響。

表 4 中比較了預(yù)測器微調(diào)和編碼器微調(diào)以及預(yù)測器和編碼器的端到端微調(diào),編碼器使用了 ViTB/16。

從表 5 中可以看出,在對所有協(xié)議的性能進行匯總時,利用 IWM 可以在凍結(jié)編碼器的情況下獲得最佳性能,即允許利用預(yù)訓(xùn)練的每一部分。

表 6 展示了 I-JEPA 和 IWM 在 ADE20k 圖像分割任務(wù)中的表現(xiàn)。

在圖 3 中,展示了預(yù)測器微調(diào)與編碼器微調(diào)相比的效率。

表征學(xué)習(xí)的主要目標(biāo)之一是獲得可用于各種任務(wù)的表征。就像預(yù)測器是為解決各種任務(wù)(著色、內(nèi)畫、變色)而訓(xùn)練的一樣,對于每個任務(wù),都有一個任務(wù) token,以及一個任務(wù)特定的頭和 / 或損失函數(shù)。然后合并所有任務(wù)損失,并更新預(yù)測器和特定任務(wù)頭。這里研究了一種簡單的情況,即批次在任務(wù)之間平均分配,同時注意到其他采樣策略可能會進一步提高性能。
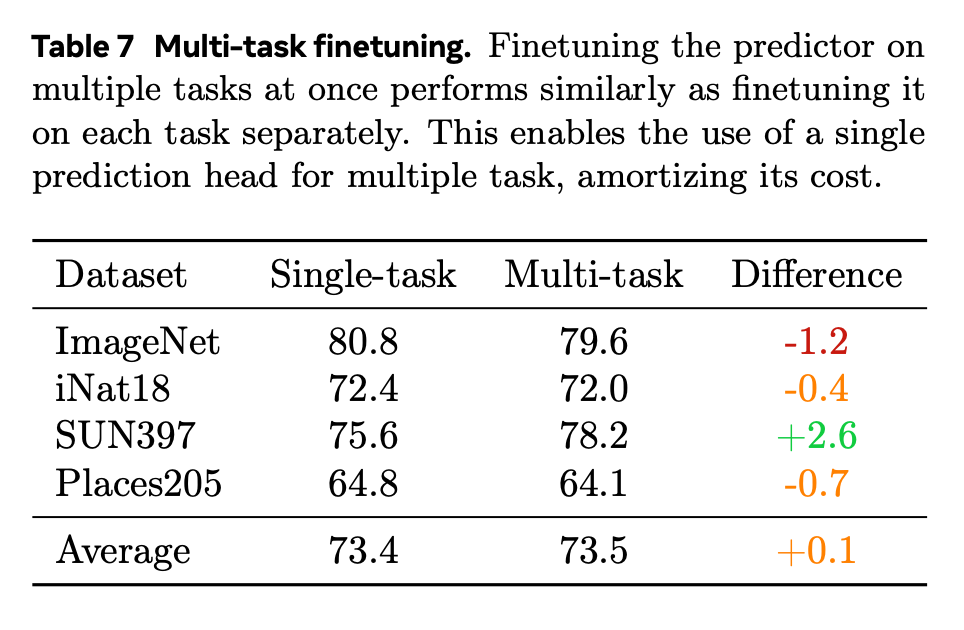
總之,當(dāng)學(xué)習(xí)到一個好的世界模型后,通過微調(diào)就可以將其重新用于下游任務(wù)。這樣就能以極低的成本實現(xiàn)與編碼器微調(diào)相媲美的性能。通過進行多任務(wù)微調(diào),它還能變得更加高效,更凸顯了這種方法的多功能性。
圖像世界模型使表征更加靈活
為了完成對 IWM 在表征學(xué)習(xí)中的分析,研究者研究了它在自監(jiān)督學(xué)習(xí)中常用的輕量級評估協(xié)議上的表現(xiàn)。本文重點關(guān)注線性探測和注意力探測。
如表 8 所示,當(dāng) IWM 學(xué)習(xí)一個不變的世界模型時,其表現(xiàn)類似于對比學(xué)習(xí)方法,如 MoCov3,在線性探測中與 MIM 或其他基于 JEPA 的方法相比有顯著的性能提升。同樣,當(dāng) IWM 學(xué)習(xí)一個等變的世界模型時,其表現(xiàn)類似于 MIM 方法,如 MAE,在線性探測中性能較低,但在注意力探測中表現(xiàn)更具競爭力。

這表明,方法之間的重大區(qū)別不一定在于表征的質(zhì)量,而在于它們的抽象級別,即從中提取信息的難易程度。線性探測是最簡單的評估之一,注意力探測稍微復(fù)雜一些,而微調(diào)則是更復(fù)雜的協(xié)議。
圖 4 可以看出,評估協(xié)議的適用性與世界模型的等價性之間有著明顯聯(lián)系。不變性較高的世界模型在線性探測中表現(xiàn)出色,而等變世界模型在使用更大的評估頭部,如在預(yù)測器微調(diào)中,有組合更好的表現(xiàn)。研究者們還注意到,由等變世界模型產(chǎn)生的更豐富的表征在跨域 OOD 數(shù)據(jù)集上具有更好的性能。

圖 5 中按表征的抽象程度將方法分類。對比學(xué)習(xí)方法占據(jù)了高抽象度的一端,只需一個簡單的協(xié)議就能輕松提取信息。然而,如表 5 所示,當(dāng)忽略調(diào)整成本時,這些方法的峰值性能較低。與之相反的是掩蔽圖像建模法(MIM),它在微調(diào)等復(fù)雜評估中性能更強,但在線性探測中由于信息不易獲取而表現(xiàn)不佳。通過改變世界模型的等變性,IWM 能夠在對比學(xué)習(xí)方法和 MIM 之間有屬于自己的位置,如圖 4 和表 8 所示, 和
和  是 IWM 光譜的兩個極端。
是 IWM 光譜的兩個極端。

這個光譜可以用自監(jiān)督學(xué)習(xí)(SSL)的理念「學(xué)習(xí)可預(yù)測之物」來概括。通過一個弱世界模型進行學(xué)習(xí)意味著它無法正確地建模世界,編碼器會移除那些無法預(yù)測的信息。反之,如果世界模型非常強大,那么表征就不需要那么抽象或語義化,因為它能夠在任何情況下找到預(yù)測表征的方法。這意味著,學(xué)習(xí)一個世界模型提供了一種可度量的方式來控制表征的抽象級別。
更多技術(shù)細(xì)節(jié),請參閱原文。






























