













LeCun怒斥Sora不能理解物理世界!Meta首發(fā)AI視頻「世界模型」V-JEPA
Sora一經(jīng)面世,瞬間成為頂流,話題熱度只增不減。

強(qiáng)大的逼真視頻生成能力,讓許多人紛紛驚呼「現(xiàn)實不存在了」。
甚至,OpenAI技術(shù)報告中透露,Sora能夠深刻地理解運動中的物理世界,堪稱為真正的「世界模型」。

而一直將「世界模型」作為研究重心的圖靈巨頭LeCun,也卷入了這場論戰(zhàn)。
起因是,網(wǎng)友挖出前幾天LeCun參加WGS峰會上發(fā)表的觀點:「在AI視頻方面,我們不知道該怎么做」。
在他看來,「僅根據(jù)文字提示生成逼真的視頻,并不代表模型理解了物理世界。生成視頻的過程與基于世界模型的因果預(yù)測完全不同」。

接下來,LeCun更詳細(xì)地解釋道:
雖然可以想象出的視頻種類繁多,但視頻生成系統(tǒng)只需創(chuàng)造出「一個」合理的樣本就算成功。
而對于一個真實視頻,其合理的后續(xù)發(fā)展路徑就相對較少,生成這些可能性中的具代表性部分,尤其是在特定動作條件下,難度大得多。
此外,生成這些視頻后續(xù)內(nèi)容不僅成本高昂,實際上也毫無意義。
更理想的做法是生成那些后續(xù)內(nèi)容的「抽象表示」,去除與我們可能采取的行動無關(guān)的場景細(xì)節(jié)。
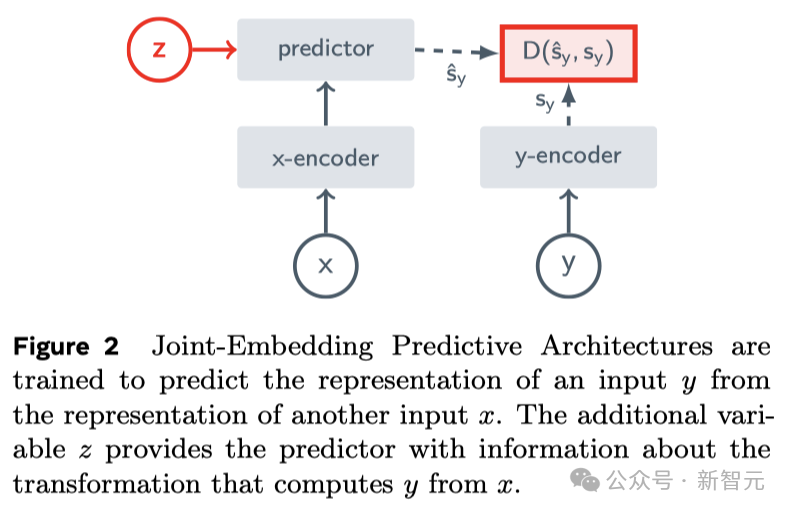
這正是JEPA(聯(lián)合嵌入預(yù)測架構(gòu))的核心思想,它并非生成式的,而是在表示空間中進(jìn)行預(yù)測。
然后,他用自家的研究VICReg、I-JEPA、V-JEPA以及他人的工作證明:
與重建像素的生成型架構(gòu),如變分自編碼器(Variational AE)、掩碼自編碼器(Masked AE)、去噪自編碼器(Denoising AE)等相比,「聯(lián)合嵌入架構(gòu)」能夠產(chǎn)生更優(yōu)秀的視覺輸入表達(dá)。
當(dāng)使用學(xué)習(xí)到的表示作為下游任務(wù)中受監(jiān)督頭部的輸入(無需對主干進(jìn)行微調(diào)),聯(lián)合嵌入架構(gòu)在效果上超過了生成式架構(gòu)。
也就是在Sora模型發(fā)布的當(dāng)天,Meta重磅推出一個全新的無監(jiān)督「視頻預(yù)測模型」——V-JEPA。
自2022年LeCun首提JEPA之后,I-JEPA和V-JEPA分別基于圖像、視頻擁有強(qiáng)大的預(yù)測能力。
號稱能夠以「人類的理解方式」看世界,通過抽象性的高效預(yù)測,生成被遮擋的部分。

論文地址:https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/
V-JEPA看到下面視頻中的動作時,會說「將紙撕成兩半」。

再比如,翻看筆記本的視頻被遮擋了一部分,V-JEPA便能夠?qū)P記本上的內(nèi)容做出不同的預(yù)測。

值得一提的是,這是V-JEPA在觀看200萬個視頻后,才獲取的超能力。
實驗結(jié)果表明,僅通過視頻特征預(yù)測學(xué)習(xí),就能夠得到廣泛適用于各類基于動作和外觀判斷的任務(wù)的「高效視覺表示」,而且不需要對模型參數(shù)進(jìn)行任何調(diào)整。
基于V-JEPA訓(xùn)練的ViT-H/16,在Kinetics-400、SSv2、ImageNet1K 基準(zhǔn)上分別取得了81.9%、72.2%和77.9%的高分。

看完200萬個視頻后,V-JEPA理解世界了
人類對于周遭世界的認(rèn)識,特別是在生命的早期,很大程度上是通過「觀察」獲得的。
就拿牛頓的「運動第三定律」來說,即便是嬰兒,或者貓,在多次把東西從桌上推下并觀察結(jié)果,也能自然而然地領(lǐng)悟到:凡是在高處的任何物體,終將掉落。
這種認(rèn)識,并不需要經(jīng)過長時間的指導(dǎo),或閱讀海量的書籍就能得出。
可以看出,你的內(nèi)在世界模型——一種基于心智對世界的理解所建立的情景理解——能夠預(yù)見這些結(jié)果,并且極其高效。
Yann LeCun表示,V-JEPA正是我們向著對世界有更深刻理解邁出的關(guān)鍵一步,目的是讓機(jī)器能夠更為廣泛的推理和規(guī)劃。

2022年,他曾首次提出聯(lián)合嵌入預(yù)測架構(gòu)(JEPA)。
我們的目標(biāo)是打造出能夠像人類那樣學(xué)習(xí)的先進(jìn)機(jī)器智能(AMI),通過構(gòu)建對周遭世界的內(nèi)在模型來學(xué)習(xí)、適應(yīng)和高效規(guī)劃,以解決復(fù)雜的任務(wù)。

V-JEPA:非生成式模型
與生成式AI模型Sora完全不同,V-JEPA是一種「非生成式模型」。
它通過預(yù)測視頻中被隱藏或缺失部分,在一種抽象空間的表示來進(jìn)行學(xué)習(xí)。
這與圖像聯(lián)合嵌入預(yù)測架構(gòu)(I-JEPA)類似,后者通過比較圖像的抽象表示進(jìn)行學(xué)習(xí),而不是直接比較「像素」。
不同于那些嘗試重建每一個缺失像素的生成式方法,V-JEPA能夠舍棄那些難以預(yù)測的信息,這種做法使得在訓(xùn)練和樣本效率上實現(xiàn)了1.5-6倍的提升。
V-JEPA采用了自監(jiān)督的學(xué)習(xí)方式,完全依靠未標(biāo)記的數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練。
僅在預(yù)訓(xùn)練之后,它便可以通過標(biāo)記數(shù)據(jù)微調(diào)模型,以適應(yīng)特定的任務(wù)。
因此,這種架構(gòu)比以往的模型更為高效,無論是在需要的標(biāo)記樣本數(shù)量上,還是在對未標(biāo)記數(shù)據(jù)的學(xué)習(xí)投入上。
在使用V-JEPA時,研究人員將視頻的大部分內(nèi)容遮擋,僅展示極小部分的「上下文」。
然后請求預(yù)測器補(bǔ)全所缺失的內(nèi)容——不是通過具體的像素,而是以一種更為抽象的描述形式在這個表示空間中填充內(nèi)容。

V-JEPA通過預(yù)測學(xué)習(xí)潛空間中被隱藏的時空區(qū)域來訓(xùn)練視覺編碼器
掩碼方法
V-JEPA并不是為了理解特定類型的動作而設(shè)計的。
相反,它通過在各種視頻上應(yīng)用自監(jiān)督學(xué)習(xí),掌握了許多關(guān)于世界運作方式的知識。
Meta研究人員還精心設(shè)計了掩碼(masking)策略:
如果不遮擋視頻的大部分區(qū)域,而只是隨機(jī)選取一些小片段,這會讓學(xué)習(xí)任務(wù)變得過于簡單,導(dǎo)致模型無法學(xué)習(xí)到關(guān)于世界的復(fù)雜信息。
同樣,需要注意的是,大多數(shù)視頻中,事物隨著時間的推移而逐漸演變。
如果只在短時間內(nèi)掩碼視頻的一小部分,讓模型能看到前后發(fā)生的事,同樣會降低學(xué)習(xí)難度,讓模型難以學(xué)到有趣的內(nèi)容。
因此,研究人員采取了同時在空間和時間上掩碼視頻部分區(qū)域的方法,迫使模型學(xué)習(xí)并理解場景。
高效預(yù)測,無需微調(diào)
在抽象的表示空間中進(jìn)行預(yù)測非常關(guān)鍵,因為它讓模型專注于視頻內(nèi)容的高層概念,而不必?fù)?dān)心通常對完成任務(wù)無關(guān)緊要的細(xì)節(jié)。
畢竟,如果一段視頻展示了一棵樹,你可能不會關(guān)心每一片樹葉的微小運動。
而真正讓Meta研究人員興奮的是,V-JEPA是首個在「凍結(jié)評估」上表現(xiàn)出色的視頻模型。
凍結(jié),是指在編碼器和預(yù)測器上完成所有自監(jiān)督預(yù)訓(xùn)練后,就不再對其進(jìn)行修改。
當(dāng)我們需要模型學(xué)習(xí)新技能時,只需在其上添加一個小型的、專門的層或網(wǎng)絡(luò),這種方式既高效又快速。

以往的研究還需要進(jìn)行全面的微調(diào),即在預(yù)訓(xùn)練模型后,為了讓模型在細(xì)粒度動作識別等任務(wù)上表現(xiàn)出色,需要微調(diào)模型的所有參數(shù)或權(quán)重。
直白講,微調(diào)后的模型只能專注于某個任務(wù),而無法適應(yīng)其他任務(wù)。
如果想讓模型學(xué)習(xí)不同的任務(wù),就必須更換數(shù)據(jù),并對整個模型進(jìn)行專門化調(diào)整。
V-JEPA的研究表明,就可以一次性預(yù)訓(xùn)練模型,不依賴任何標(biāo)記數(shù)據(jù),然后將模型用于多個不同的任務(wù),如動作分類、細(xì)粒度物體交互識別和活動定位,開辟了全新的可能。

- 少樣本凍結(jié)評估
研究人員將V-JEPA與其他視頻處理模型進(jìn)行了對比,特別關(guān)注在數(shù)據(jù)標(biāo)注較少的情況下的表現(xiàn)。
它們選取了Kinetics-400和Something-Something-v2兩個數(shù)據(jù)集,通過調(diào)整用于訓(xùn)練的標(biāo)注樣本比例(分別為5%,10%和50%),觀察模型在處理視頻時的效能。
為了確保結(jié)果的可靠性,在每種比例下進(jìn)行了3次獨立的測試,并計算出了平均值和標(biāo)準(zhǔn)偏差。
結(jié)果顯示,V-JEPA在標(biāo)注使用效率上優(yōu)于其他模型,尤其是當(dāng)每個類別可用的標(biāo)注樣本減少時,V-JEPA與其他模型之間的性能差距更加明顯。

未來研究新方向:視覺+音頻同預(yù)測
雖然V-JEPA的「V」代表視頻,但迄今為止,它主要集中于分析視頻的「視覺元素」。
顯然,Meta下一步是研究方向是,推出一種能同時處理視頻中的「視覺和音頻信息」的多模態(tài)方法。
作為一個驗證概念的模型,V-JEPA在識別視頻中細(xì)微的物體互動方面表現(xiàn)出色。
比如,能夠區(qū)分出某人是在放下筆、拿起筆,還是假裝放下筆但實際上沒有放下。
不過,這種高級別的動作識別對于短視頻片段(幾秒到10秒鐘)效果很好。
因此,下一步研究另一個重點是,如何讓模型在更長的時間跨度上進(jìn)行規(guī)劃和預(yù)測。
「世界模型」又進(jìn)一步
到目前為止,Meta研究人員使用V-JEPA主要關(guān)注于的是「感知」——通過分析視頻流來理解周圍世界的即時情況。
在這個聯(lián)合嵌入預(yù)測架構(gòu)中,預(yù)測器充當(dāng)了一個初步的「物理世界模型」,能夠概括性地告訴我們視頻中正在發(fā)生的事情。

Meta的下一步目標(biāo)是展示,如何利用這種預(yù)測器或世界模型來進(jìn)行規(guī)劃和連續(xù)決策。
我們已經(jīng)知道,JEPA模型可以通過觀察視頻來進(jìn)行訓(xùn)練,就像嬰兒觀察世界一樣,無需強(qiáng)有力的監(jiān)督就能學(xué)習(xí)很多。
通過這種方式,僅用少量標(biāo)注數(shù)據(jù),模型就能快速學(xué)習(xí)新任務(wù)和識別不同的動作。
從長遠(yuǎn)來看,在未來應(yīng)用中,V-JEPA強(qiáng)大情境理解力,對開發(fā)具身AI技術(shù)以及未來增強(qiáng)現(xiàn)實(AR)眼鏡有著重大意義。
現(xiàn)在想想,如果蘋果Vision Pro能夠得到「世界模型」的加持,更加無敵了。
網(wǎng)友討論
顯然,LeCun對生成式AI并不看好。

「聽聽一個一直在試圖訓(xùn)練用于演示和規(guī)劃的「世界模型」過來人的建議」。
Perplexity AI的首席執(zhí)行官表示:
Sora雖然令人驚嘆,但還沒有準(zhǔn)備好對物理進(jìn)行準(zhǔn)確的建模。并且Sora的作者非常機(jī)智,在博客的技術(shù)報告部分提到了這一點,比如打碎的玻璃無法很好地建模。
很明顯短期內(nèi),基于這樣復(fù)雜的世界仿真的推理,是無法在家用機(jī)器人上立即運行的。

事實上,許多人未能理解的一個非常重要的細(xì)微差別是:
在文本或視頻中生成看似有趣的內(nèi)容并不意味著(也不需要)它「理解」自己生成的內(nèi)容。一個能夠基于理解進(jìn)行推理的智能體模型必須,絕對是在大模型或擴(kuò)散模型之外。

但也有網(wǎng)友表示,「這并不是人類學(xué)習(xí)的方式」。
「我們對以往經(jīng)歷的只記得一些獨特的,丟掉了所有的細(xì)節(jié)。我們還可以隨時隨地為環(huán)境建模(創(chuàng)建表示法),因為我們感知到了它。智能最重要的部分是泛化」。

還有人稱,它仍然是插值潛在空間的嵌入,到目前為止你還不能以這種方式構(gòu)建「世界模型」。

Sora,以及V-JEPA真的能夠理解世界嗎?你怎么看?






























