香港城市大學研發(fā)頭發(fā)合成新框架,手繪草圖妙變逼真秀發(fā)
現(xiàn)有的解決方案通常需要用戶提供的二進制掩碼來指定目標發(fā)型。這不僅會增加用戶的勞動成本,而且也無法捕捉復雜的頭發(fā)邊界。這些解決方案通常通過方向圖編碼頭發(fā)結(jié)構(gòu),然而,這對編碼復雜結(jié)構(gòu)并不是很有效。
其實,彩色頭發(fā)草圖已經(jīng)含蓄地定義了目標頭發(fā)形狀和頭發(fā)外觀,比方向圖更靈活地描述頭發(fā)結(jié)構(gòu)。基于這些觀察,香港城市大學提出了SketchHairSalon,一個兩階段框架,直接從手繪草圖生成真實的頭發(fā)圖像,描繪所需的頭發(fā)結(jié)構(gòu)和外觀。
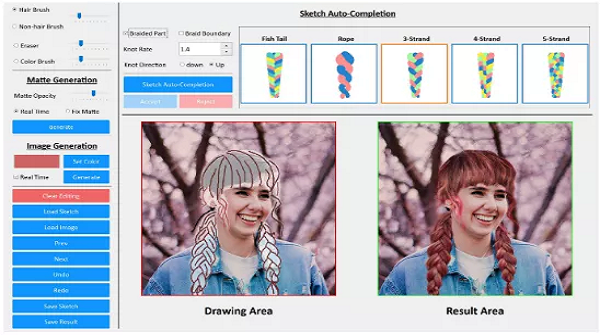
并且還提供了設(shè)計界面,如下圖所示,包括Hair Structure Specification(頭發(fā)結(jié)構(gòu)定制)、Hair Shape Refinement(頭發(fā)形狀優(yōu)化)、Hair Appearance Specification(頭發(fā)的外觀定制)、Sketch Auto-completion(自動完成草圖)等功能。
設(shè)計思想
為了解決現(xiàn)有算法存在的問題,作者觀察到頭發(fā)草圖本身包含了足夠的信息來描述局部和整體層面上所需發(fā)型的結(jié)構(gòu)、外觀和形狀。例如,對于一個波浪發(fā)型,一筆可以代表一個局部和連貫的頭發(fā)束,而兩筆可以用來形成一個t型結(jié)。彩色的筆畫能夠表明頭發(fā)圖像的局部外觀。
此外,描繪發(fā)型結(jié)構(gòu)的草圖已經(jīng)含蓄地定義了頭發(fā)區(qū)域的整體形狀,最好是沿著毛發(fā)區(qū)域的邊界自動推斷局部和柔軟的細節(jié),因為這些細節(jié)很難由用戶指定,而且耗時。在這種情況下,由于支持軟邊界,毛發(fā)啞光比二進制掩模更適合描述毛發(fā)區(qū)域。
基于以上關(guān)鍵觀察,作者提出了SketchHairSalon,一個新穎的深度生成框架,直接從一組彩色筆畫合成真實的頭發(fā)圖像。它包括兩個關(guān)鍵階段:素描到亞光生成和素描到圖像生成。
第一階段側(cè)重于從輸入的頭發(fā)草圖生成頭發(fā)啞光,以減少草圖到頭發(fā)生成的模糊性。用戶可以選擇輸入非毛發(fā)筆畫,這些筆畫被用作額外的條件來指導啞光的生成。
第二階段根據(jù)給定輸入草圖和生成的頭發(fā)啞光,設(shè)法合成一個逼真的頭發(fā)圖像。同時將自我注意模塊應用到這兩個階段的網(wǎng)絡(luò)中,以學習更多的對應關(guān)系。
為了訓練這兩個階段的網(wǎng)絡(luò),作者還提出了一個新的頭發(fā)草圖-圖像數(shù)據(jù)集,其中包含了數(shù)以千計的頭發(fā)圖像和相應的手工注釋的頭發(fā)草圖,以描述底層的頭發(fā)結(jié)構(gòu)。每個頭發(fā)圖像也與自動生成的頭發(fā)啞光相關(guān)聯(lián)。
網(wǎng)絡(luò)架構(gòu)
該網(wǎng)絡(luò)框架由兩個主要網(wǎng)絡(luò)組成:
- 素描到亞光網(wǎng)絡(luò)(簡稱S2M-Net)
- 素描到圖像網(wǎng)絡(luò)(簡稱S2I-Net)
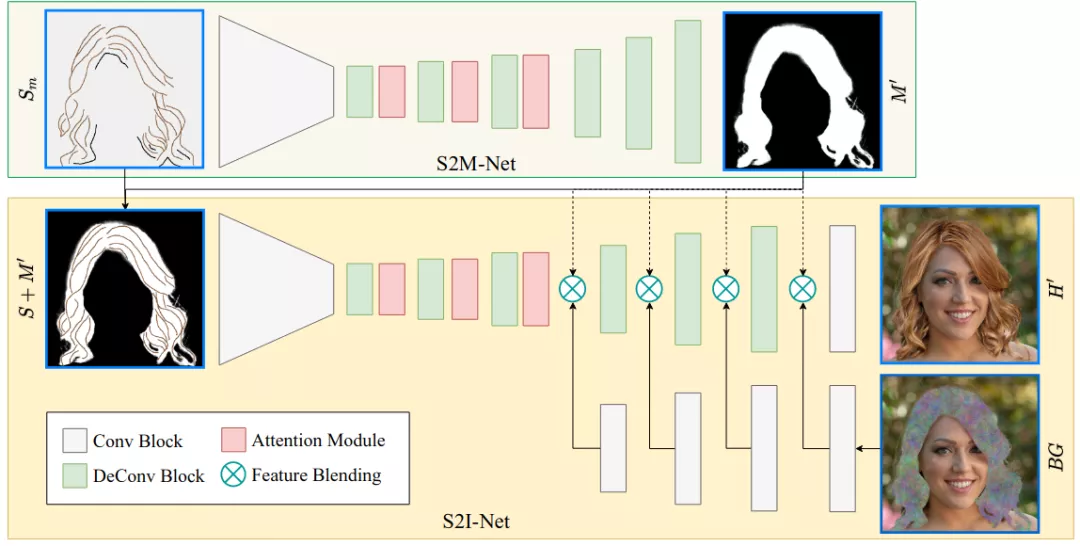
素描到亞光網(wǎng)絡(luò)(S2M-Net)
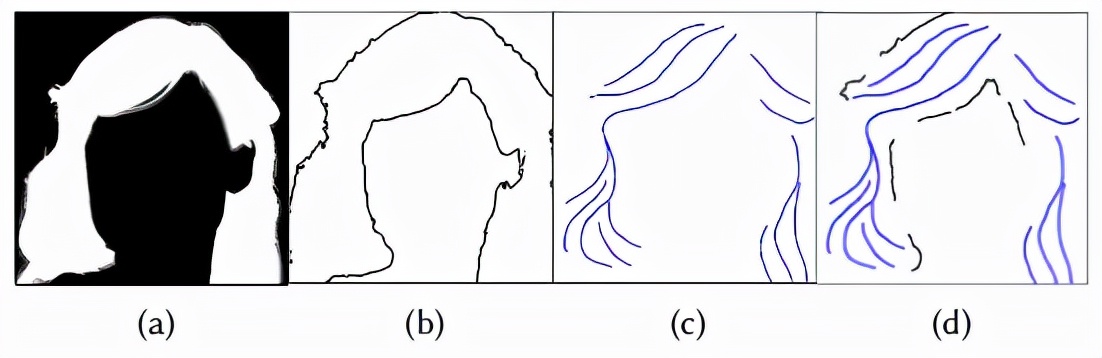
S2M-Net以素描圖Sm∈R512×512×1作為輸入,其中包含頭發(fā)和非頭發(fā)的筆畫,其中有色筆畫設(shè)置為一種顏色(例如,藍色),非筆畫設(shè)置為黑色(如圖4 (d)所示),即可輸出頭發(fā)啞光M'∈512×512×1(圖4(a))。
為了準備用于訓練S2M-Net的數(shù)據(jù)集,首先通過距離圖從GroundTruth真實的頭發(fā)遮光物中提取頭發(fā)輪廓(圖4 (b))。頭發(fā)的輪廓從頭發(fā)區(qū)域被稍微推開(從3到8像素隨機設(shè)置)。
然后,通過隨機擦除大部分頭發(fā)輪廓推導出非頭發(fā)筆畫,以平衡訓練中非頭發(fā)筆畫和頭發(fā)筆畫的密度。描邊寬度隨機設(shè)置為3到15像素,以定義非毛發(fā)區(qū)域的大小,避免過擬合。
最后,將非毛發(fā)筆畫和毛發(fā)筆畫在草圖中融合在一起,表示為(如圖4 (d)所示),然后送入S2M-Net。
另外,該部分網(wǎng)路采用了帶有自注意模塊的編碼器-解碼器生成器,在解碼器的前三層中,在每個反卷積層之后重復應用三個自注意模塊,以關(guān)注全局和高層翻譯。
考慮到自注意力計算隨著特征圖空間尺寸的增大呈指數(shù)級增長,所以就沒有在后一層插入任何自注意模塊。
素描到圖像網(wǎng)絡(luò)(簡稱S2I-Net)
在S2M-Net之后,我們得到了一個合成的頭發(fā)掩模M’,明確了目標頭發(fā)的形狀。如圖5(下)所示,S2I-Net與S2M-Net類似,關(guān)鍵的區(qū)別在于它包含了背景混合模塊,同上面這個網(wǎng)絡(luò)不同,這里采用彩色草圖來代表頭發(fā)結(jié)構(gòu)和外觀。
背景區(qū)域在頭發(fā)啞光'的引導下,在特征層上與合成頭發(fā)區(qū)域混合,表示為:
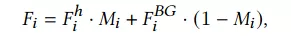
背景輸入是通過用高斯噪聲替換原始圖像的毛發(fā)區(qū)域得到的。在S2I-Net的主分支,只在最后四層混合背景區(qū)域。
- 草圖自動補全
由于大多數(shù)發(fā)型都有簡單但較大的區(qū)域,具有相似的局部結(jié)構(gòu),需要用重復的頭發(fā)筆畫填充,以減少S2I-Net的模糊性。在設(shè)計發(fā)型時,要求用戶畫一套完整的頭發(fā)線條是很乏味的。為了減少用戶的工作量,作者提出了兩種給定稀疏筆畫的編發(fā)和非編發(fā)草圖自動補全方法。
- 編織發(fā)型
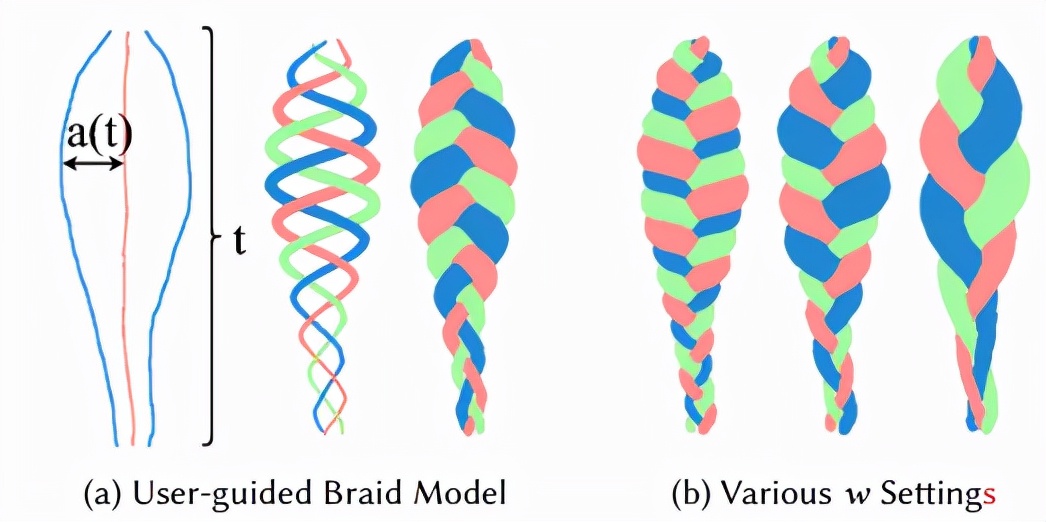
(a)生成的三股編織模型(右)在用戶指定的粗邊界線(左側(cè)藍色筆畫)指導下,由三條中心線(中)展開。(b)將分別設(shè)為1.5、1、0.5,以改變(a)中3股模型(=−1)的結(jié)數(shù)和結(jié)向。
- 解開發(fā)型

給定輸入的草圖(a),medial-axis提取算法從(a)-(b)中提取額外的筆畫(c)。(d)是完成的草圖,其中藍色筆畫和綠色筆畫分別是用戶指定的和自動生成的筆畫。
性能評估
- 頭發(fā)啞光質(zhì)量
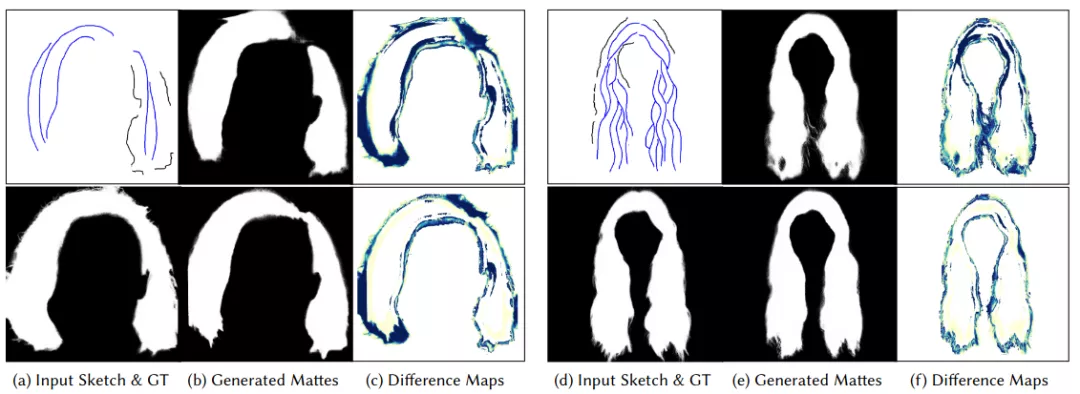
除(a)和(d)外,頂部一行為未設(shè)置自注意模塊的模型,底部一行為設(shè)置自注意模塊的模型。在每一組左右,(b)和(e)是給定草圖((a)和(d)頂部)生成的Mask,而(c)和(f)是Mask和GT((a)和(d)底部)之間的差異圖。在差值圖中,藍色區(qū)域越大,與GT值的差值越高。
- 基于草圖的頭發(fā)圖像合成與其他算法的比較

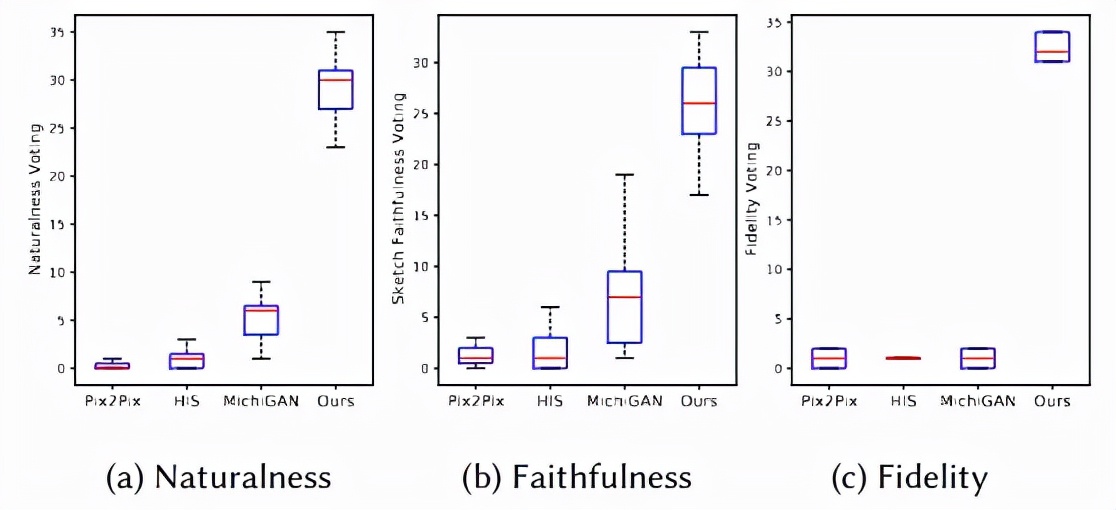
- 感知和可用性研究

- 消融實驗

對比模型包含和不包含方向圖的結(jié)果:(b)單獨使用方向圖;(c)使用草圖和方向圖;(d)單獨使用草圖。對于每一對(a),上面的是草圖和背景輸入,下面的是草圖預測的稠密方向圖。

比較模型變量在給定相同輸入的不同設(shè)置下產(chǎn)生的結(jié)果(a)。(b)在合成數(shù)據(jù)集上訓練。(c)沒有注意模塊,(d)完整模型。

兩個不太成功的例子。頂部行顯示不自然的結(jié)果缺乏足夠的分層效果,而底部行顯示自閉塞卷一起的失敗案例。