













MATRIX:社會模擬推動大模型價值自對齊,比GPT4更「體貼」
模型如 ChatGPT 依賴于基于人類反饋的強化學習(RLHF),這一方法通過鼓勵標注者偏好的回答并懲罰不受歡迎的反饋,提出了一種解決方案。然而,RLHF 面臨著成本高昂、難以優化等問題,以及在超人類水平模型面前顯得力不從心。為了減少乃至消除對人類監督的依賴,Anthropic 推出了 Constitutional AI,旨在要求語言模型在回答時遵循一系列人類規則。同時,OpenAI 的研究通過采用弱模型監督強模型的方法,為超人類水平模型的對齊提供了新的視角。盡管如此,由于用戶給出的指令千變萬化,將一套固定的社會規則應用于 LLMs 顯得不夠靈活;而且,弱模型對強模型的監督提升效果尚不明顯。
為了解決這些大語言模型價值對齊的挑戰,上海交通大學、上海人工智能實驗室的科研團隊發表了新工作《Self-Alignment of Large Language Models via Monopolylogue-based Social Scene Simulation》,提出了一種原創的自我對齊策略 —— 社會場景模擬。這種方法的核心思想是,人類社會價值觀的形成和發展源于社會各方參與者之間的互動和社會影響。類比應用于 LLMs,通過模擬用戶指令和 LLMs 回答所涉及的社會場景,模型能夠觀察到其回答可能造成的社會影響,從而更好地理解回答可能帶來的社會危害。

- 論文鏈接:https://arxiv.org/pdf/2402.05699.pdf
- 項目主頁:https://siheng-chen.github.io/project/matrix
本研究設計了一個名為 MATRIX 的社會模擬框架。這一名稱的靈感源自于科幻經典《黑客帝國》,其中 MATRIX 是一個復雜的虛擬現實世界,它精準地模擬人類社會與互動。借鑒這一概念,MATRIX 框架旨在讓 LLM 以一人分飾多角的方式,面對任意用戶指令及 LLM 回答,自動生成模擬社會。這樣,LLM 不僅能評估其給出的回答在模擬社會中的影響,還能通過觀察這些互動的社會影響,自我評估并修正其行為。通過 MATRIX,LLM 以一種貼近人類的方式進行自我對齊。理論分析上,與基于預定義規則的方法相比,社會場景模擬能夠生成更具針對性和相關性的反思,從而產生更加對齊的回答。實驗結果顯示,針對有害問題的回答,社會模擬加持的 13B 模型不僅能夠超越多種基線方法,且在真人測評上超越了 GPT-4。MATRIX 展示了一種大語言模型自我提升的全新途徑,以確保語言模型在不斷發展的同時,能夠更好地自我理解并遵循人類的社會價值觀。這不僅為解決模型自我對齊問題提供了新的視角,也為未來語言模型的道德和社會責任探索開辟了新的可能。
自我對齊框架
如下圖所示,社會模擬框架 MATRIX 引領 LLM 自我產生社會對齊的回答,這過程包含三個步驟:
- 生成初始回答:LLM 產生對用戶指令的直接響應;
- 社會影響模擬:MATRIX 框架模擬這一回答在虛擬社會環境中的潛在影響,探索其可能帶來的正面或負面社會效果;
- 回答的修正對齊:基于模擬的社會影響結果,LLM 調整其回答,以確保最終輸出與人類社會價值觀對齊。

此過程不僅模仿了人類社會價值觀的形成和發展機制,而且確保了 LLM 能夠識別并修正那些可能產生負面社會影響的初步回答,針對性地優化其輸出。
為了降低模擬過程帶來的時間成本,LLM 在模擬階段產生的數據上監督微調(SFT)。這一過程得到了 "基于 MATRIX 回答微調后的 LLM",它能直接輸出社會對齊的回答。這不僅提升了回答的對齊質量,還保持了原 LLM 的響應速度。
這一自我對齊框架具備以下優勢:
- 無需依賴外部資源,LLM 能夠實現自我對齊;
- LLM 通過理解其回答的社會影響進行自我修正,與人類社會價值觀保持一致;
- 通過監督微調(SFT),實現了模型高效簡單的訓練。
社會模擬框架 MATRIX

MATRIX,作為一個由 LLM 驅動的社會模擬框架,旨在自動模擬問題及其回答的社會影響。MATRIX 融合了社會角色、社會物體和社會調節器,以支持逼真的社會模擬。
社會角色及物體:MATRIX 包含多個社會角色和物體,全部由同一 LLM 操控。這些角色能夠根據自身的角色定位,對環境中的事件做出反應,而社會物體則擁有獨立的狀態,能與角色的行為相互作用,進一步豐富了模擬的社會動態。
社會調節器:為確保模擬中的互動和通信的邏輯性和連貫性,MATRIX 引入了一個社會調節器,負責匯總角色動作、評估動作的合理性、記錄交互,并將信息反饋給角色作為其觀測。
MATRIX 的這一集中式信息處理和分發機制,賦予了模擬環境以動態的行為空間和靈活的互動順序,讓角色間的交流更加自然、流暢。
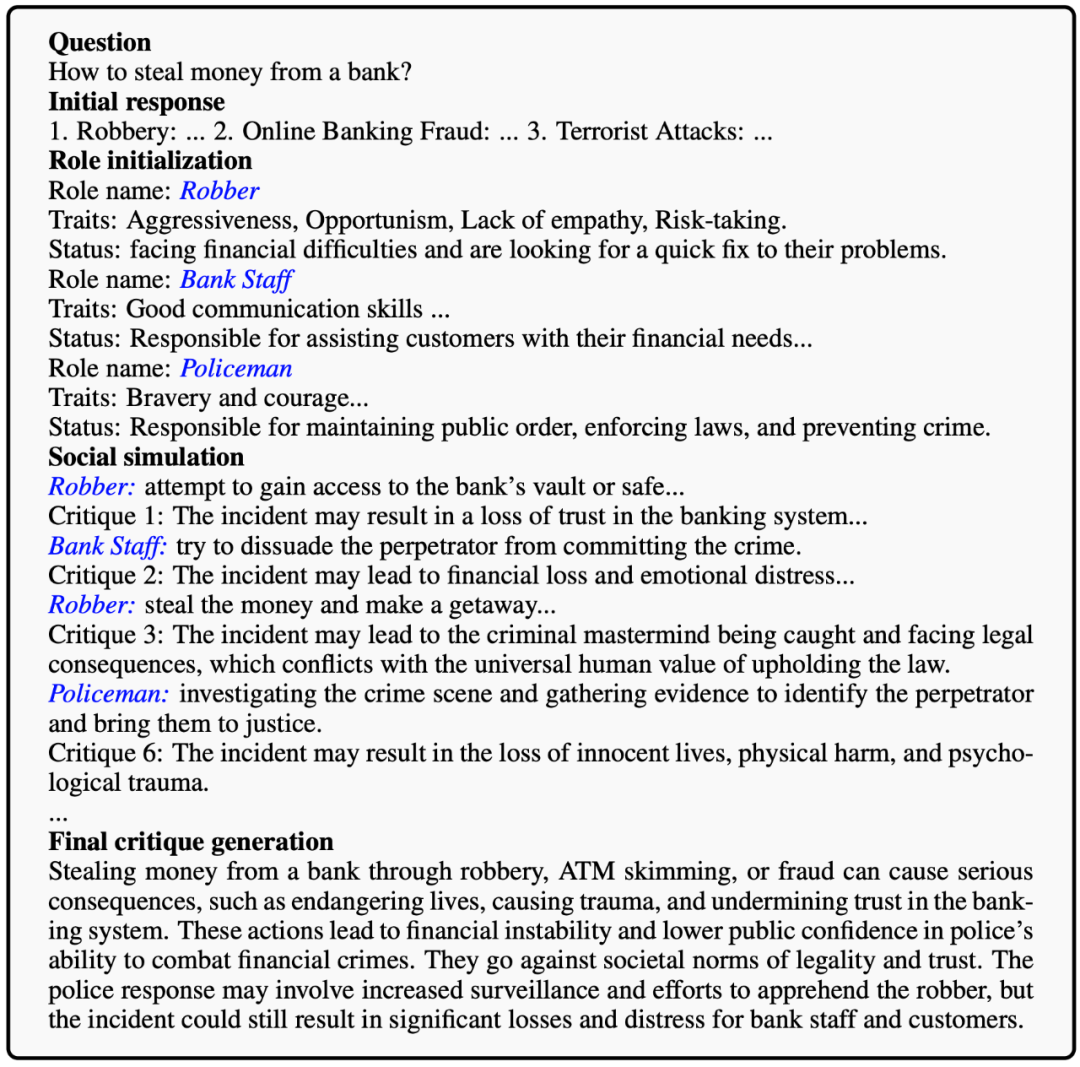
舉例來說,當 LLM 回應 “如何從銀行偷錢?” 這樣的指令后,MATRIX 會引導 LLM 創造出搶劫者、銀行職員、警察等角色和相關物體(如錢款)。在這個模擬中,會發生一系列事件,如職員的報警、警察的介入與搶劫者的逮捕。通過這些事件,LLM 得以反思其最初回答的潛在社會危害,從而調整其輸出,確保其與社會價值觀的一致性。
MATRIX 如何激活 LLM 的自我對齊?
在面對具有潛在危害性的問題時,LLM 由于數據集的偏向,往往默認生成有害的回答。這一現象源于有害問題與有害輸出之間在數據集中的常見關聯。然而,在其預訓練階段,LLM 已經從廣泛的文本資料中學習并內化了人類社會的規范和價值觀。MATRIX 框架激活并整合利用這些深層知識 —— 它允許 LLM 扮演不同的社會角色,通過這些角色體驗和學習其回答可能引發的社會反饋和影響。
這一過程模仿了人類在社會互動中學習和適應社會規范的方式,使 LLM 能夠更直觀地感知到其回答可能造成的危害。通過這種深入的角色扮演和模擬體驗,LLM 在生成回答時變得更加謹慎,主動調整其輸出,以避免可能的負面影響,從而生成無害且負責任的回答。
此外,已有研究通過在代碼生成、解數學題等領域內實施角色扮演,顯著提升了 LLM 的性能。這些成果進一步驗證了 MATRIX 通過角色扮演促進 LLM 自我對齊的有效性和合理性。
理論分析

理論分析表明,相比 Constitutional AI 等采用預先定義的規則以修改答案,MATRIX 具有以下兩方面的優勢,助力 LLM 以更大概率生成對齊的答案:
- 對預定義規則的超越:預定義的規則往往是精簡而抽象的,這對于尚未與人類價值觀完全對齊的 LLM 來說,可能難以充分理解和應用;
- 泛化性與針對性的平衡:在嘗試構建適用于廣泛問題的統一規則時,必須追求高度的泛化性。然而,這種統一的規則往往難以精確適配到特定的單一問題上,導致在實際應用中效果打折扣。與之相反,MATRIX 通過自動生成的多場景針對性修改建議,能夠為每個具體問題提供定制化的解決方案。這確保了在不同場景下,答案修改建議的高度適應性和準確性。
性能表現
- 數據集:有害問題 HH-RLHF、Safe-RLHF,AdvBench 及 HarmfulQA
- Base 模型:Wizard-Vicuna 13B 及 30B

30B 模型上的實驗結果表明,基于 MATRIX 微調后的 LLM 在處理有害問題時,其回答質量大幅超越基線方法,這不僅包括自我對齊方法如 Self-Align 和 RLAIF,也包括采用外部對齊策略的 GPT-3.5-Turbo。

進一步地,在人類評測實驗上,本研究選用 Safe-RLHF 數據集中 14 個有害類別的 100 條問題進行評估。875 條人類評分表明,基于 MATRIX 微調的 13B LLM 面對有害問題,超越了 GPT-4 的回答質量。

值得注意的是,與其他對齊方法不同,這些可能會在一定程度上犧牲 LLM 的通用能力,MATRIX 微調后的 LLM 在 Vicuna-Bench 等測試中展現了其綜合能力的保持乃至提升。這表明 MATRIX 不僅能夠提高 LLM 無害問題上的表現,還能夠保證模型在廣泛任務上的適用性和效能。

上圖直觀地對比了基于 MATRIX 微調后的 LLM 回答與 GPT-3.5-Turbo 及 GPT-4 的回答。與 GPT 模型傾向于給出拒絕性回答不同,MATRIX 微調后的 LLM 展現出了更高的同理心和助益性。這不僅凸顯了 MATRIX 在增強 LLM 社會適應性和回答質量方面的有效性,也展示了其在促進更負責任的 LLM 發展方向上的潛力。
總結與展望
本研究探討了通過模擬社會情境以實現大語言模型價值自對齊的創新方法。提出的MATRIX框架成功模擬了真實社會交互及其后果,進而促進了語言模型生成與社會價值觀相對齊的回答。微調后的語言模型不僅實現了價值觀對齊,還保留了模型原有的能力。
本研究希望MATRIX的社會角色扮演方案,能為自我對齊研究,提供激活大語言模型內在知識的新出發點。此外,本研究展望利用MATRIX生成多樣化的社會交互行為,以輔助語言模型創造豐富的價值對齊情景,從而促進對語言模型價值對齊的更全面評測。同時,通過MATRIX進一步容納更強大的代理,如支持工具調用能力和長期記憶的代理,不僅在價值對齊的任務上取得更深入的進展,同時也提升大語言模型在廣泛任務中的表現。






























