













完全地理解這個世界是世界模型要干的事!2024自動駕駛世界模型大觀~
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
何謂世界模型?
“整體上來說,完全地理解這個世界是世界模型要干的事。”——任少卿在接受采訪中說到。
那么何謂世界模型呢?按照最初wayve展示的demo,世界模型依賴實車采集的海量數據,基于生成模型去生成未來場景來和真實的未來時刻數據,進而進行監督,這是典型的無監督訓練。其最巧妙的地方則在于要想成功預測未來時刻的場景,你必須對現在時刻場景的語義信息以及世界演化的規律有著深刻的了解。當下自動駕駛方向的世界模型可以分成兩大類:生成式和端到端。今天自動駕駛之心就和大家一起盤點一下今年以來這方面的工作,文末總結!
RenderWorld: World Model with Self-Supervised 3D Label
- 論文鏈接:https://arxiv.org/abs/2409.11356v1
上海科技大學的工作:僅使用視覺的端到端自動駕駛不僅比LiDAR視覺融合更具成本效益,而且比傳統方法更可靠。為了實現經濟且穩健的純視覺自動駕駛系統,我們提出了RenderWorld,這是一種僅支持視覺的端到端自動駕駛框架,它使用基于自監督高斯的Img2Occ模塊生成3D占用標簽,然后通過AM-VAE對標簽進行編碼,并使用世界模型進行預測和規劃。RenderWorld采用高斯散射來表示3D場景和渲染2D圖像,與基于NeRF的方法相比,大大提高了分割精度并降低了GPU內存消耗。通過應用AM-VAE分別對空氣和非空氣進行編碼,RenderWorld實現了更細粒度的場景元素表示,從而在自回歸世界模型的4D占用預測和運動規劃方面取得了最先進的性能。


OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
- 論文鏈接:https://arxiv.org/abs/2409.03272v1
復旦和清華等團隊的工作:多模態大語言模型(MLLM)的興起刺激了它們在自動駕駛中的應用。最近基于MLLM的方法通過學習從感知到行動的直接映射來實現最終控制,忽略了世界的動態以及行動與世界動態之間的關系。相比之下,人類擁有世界模型,使他們能夠基于3D內部視覺表示來模擬未來的狀態,并相應地計劃行動。為此,我們提出了OccLLaMA,這是一種占用語言動作生成世界模型,它使用語義占用作為一般的視覺表示,并通過自回歸模型統一視覺語言動作(VLA)模式。具體來說,我們引入了一種新的類似VQVAE的場景標記器,以有效地離散和重建語義占用場景,同時考慮到其稀疏性和類不平衡性。然后,我們為視覺、語言和動作構建了一個統一的多模態詞匯表。此外,我們增強了LLM,特別是LLaMA,以對統一詞匯表執行下一個令牌/場景預測,從而完成自動駕駛中的多項任務。大量實驗表明,OccLLaMA在多個任務中都取得了具有競爭力的性能,包括4D占用預測、運動規劃和視覺問答,展示了其作為自動駕駛基礎模型的潛力。



Mitigating Covariate Shift in Imitation Learning for Autonomous Vehicles Using Latent Space Generative World Models
- 論文鏈接:https://arxiv.org/abs/2409.16663v2
英偉達的工作:我們建議使用潛在空間生成世界模型來解決自動駕駛中的協變量轉換問題。世界模型是一種神經網絡,能夠根據過去的狀態和動作預測代理的下一個狀態。通過在訓練過程中利用世界模型,駕駛策略有效地緩解了協變量變化,而不需要過多的訓練數據。在端到端訓練期間,我們的策略通過與人類演示中觀察到的狀態對齊來學習如何從錯誤中恢復,以便在運行時可以從訓練分布之外的擾動中恢復。此外我們介紹了一種基于Transformer的感知編碼器,該編碼器采用多視圖交叉注意力和學習場景查詢。我們呈現了定性和定量結果,展示了在CARLA模擬器閉環測試方面對現有技術的顯著改進,并展示了CARLA和NVIDIA DRIVE Sim處理擾動的能力。


Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving
- 論文鏈接:https://arxiv.org/abs/2408.14197v1
浙大&華為團隊的工作:世界模型基于各種自車行為設想了潛在的未來狀態。它們嵌入了關于駕駛環境的廣泛知識,促進了安全和可擴展的自動駕駛。大多數現有方法主要關注數據生成或世界模型的預訓練范式。與上述先前的工作不同,我們提出了Drive OccWorld,它將以視覺為中心的4D預測世界模型應用于自動駕駛的端到端規劃。具體來說,我們首先在內存模塊中引入語義和運動條件規范化,該模塊從歷史BEV嵌入中積累語義和動態信息。然后將這些BEV特征傳送到世界解碼器,以進行未來的占用和流量預測,同時考慮幾何和時空建模。此外,我們建議在世界模型中注入靈活的動作條件,如速度、轉向角、軌跡和命令,以實現可控生成,并促進更廣泛的下游應用。此外,我們探索將4D世界模型的生成能力與端到端規劃相結合,從而能夠使用基于占用的成本函數對未來狀態進行連續預測并選擇最佳軌跡。對nuScenes數據集的廣泛實驗表明,我們的方法可以生成合理可控的4D占用率,為推動世界生成和端到端規劃開辟了新途徑。




BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space
- 論文鏈接:https://arxiv.org/abs/2407.05679v2
- 開源鏈接:https://github.com/zympsyche/BevWorld
百度的工作:世界模型因其預測潛在未來情景的能力而在自動駕駛領域受到越來越多的關注。在本文中,我們提出了BEVWorld,這是一種將多模態傳感器輸入標記為統一緊湊的鳥瞰圖(BEV)潛在空間以進行環境建模的新方法。世界模型由兩部分組成:多模態標記器和潛在BEV序列擴散模型。多模態標記器首先對多模態信息進行編碼,解碼器能夠以自監督的方式通過光線投射渲染將潛在的BEV標記重建為LiDAR和圖像觀測。然后,潛在的BEV序列擴散模型在給定動作標記作為條件的情況下預測未來的情景。實驗證明了BEVWorld在自動駕駛任務中的有效性,展示了其生成未來場景的能力,并使感知和運動預測等下游任務受益。




Planning with Adaptive World Models for Autonomous Driving
- 論文鏈接:https://arxiv.org/abs/2406.10714v2
- 項目主頁:https://arunbalajeev.github.io/world_models_planning/world_model_paper.html
卡內基梅隆大學的工作:運動規劃對于復雜城市環境中的安全導航至關重要。從歷史上看,運動規劃器(MP)已經用程序生成的模擬器(如CARLA)進行了評估。然而,這種合成基準并不能捕捉到現實世界中的多智能體交互。nuPlan是最近發布的MP基準測試,它通過用閉環仿真邏輯增強現實世界的駕駛日志來解決這一局限性,有效地將固定數據集轉化為反應式模擬器。我們分析了nuPlan記錄日志的特征,發現每個城市都有自己獨特的駕駛行為,這表明穩健的規劃者必須適應不同的環境。我們學習使用BehaviorNet對這種獨特的行為進行建模,BehaviorNet是一種圖卷積神經網絡(GCNN),它使用最近觀察到的代理歷史中得出的特征來預測反應性代理行為;直覺上,一些激進的特工可能會尾隨領先的車輛,而另一些則可能不會。為了模擬這種現象,BehaviorNet預測代理運動控制器的參數,而不是直接預測其時空軌跡(就像大多數預測者那樣)。最后,我們提出了AdaptiveDriver,這是一種基于模型預測控制(MPC)的規劃器,可以展開基于BehaviorNet預測的不同世界模型。我們廣泛的實驗表明,AdaptiveDriver在nuPlan閉環規劃基準上取得了最先進的結果,在Test-14 Hard R-CLS上比之前的工作提高了2%,即使在從未見過的城市進行評估時也具有普遍性。


Enhancing End-to-End Autonomous Driving with Latent World Model
- 論文鏈接:https://arxiv.org/abs/2406.08481v1
中科院和中科院自動化研究所等團隊的工作:端到端自動駕駛引起了廣泛關注。當前的端到端方法在很大程度上依賴于感知任務的監督,如檢測、跟蹤和地圖分割,以幫助學習場景表示。然而,這些方法需要大量的標注,阻礙了數據的可擴展性。為了應對這一挑戰,我們提出了一種新的自監督方法來增強端到端的驅動,而不需要昂貴的標簽。具體來說,我們的框架LAW使用LAtent World model,根據預測的自車行為和當前框架的潛在特征來預測未來的潛在特征。預測的潛在特征由未來實際觀察到的特征進行監督。這種監督聯合優化了潛在特征學習和動作預測,大大提高了駕駛性能。因此,我們的方法在開環和閉環基準測試中都實現了最先進的性能,而無需昂貴的標注。




Probing Multimodal LLMs as World Models for Driving
- 論文鏈接:https://arxiv.org/abs/2405.05956v1
- 開源鏈接:https://github.com/sreeramsa/DriveSim
MIT等團隊的工作:我們冷靜地看待了多模態大語言模型(MLLM)在自動駕駛領域的應用,并挑戰/驗證了一些常見的假設,重點是它們在閉環控制環境中通過圖像/幀序列推理和解釋動態駕駛場景的能力。盡管GPT-4V等MLLM取得了重大進展,但它們在復雜、動態駕駛環境中的性能在很大程度上仍未經過測試,這是一個廣泛的探索領域。我們進行了一項全面的實驗研究,從固定車載攝像頭的角度評估各種MLLM作為世界駕駛模型的能力。我們的研究結果表明,雖然這些模型能夠熟練地解釋單個圖像,但它們在跨描述動態行為的框架合成連貫的敘事或邏輯序列方面存在很大困難。實驗表明,在預測(i)基本車輛動力學(前進/后退、加速/減速、右轉或左轉)、(ii)與其他道路參與者的相互作用(例如,識別超速行駛的汽車或繁忙的交通)、(iii)軌跡規劃和(iv)開放集動態場景推理方面存在相當大的不準確性,這表明模型訓練數據中存在偏差。為了實現這項實驗研究,我們引入了一個專門的模擬器DriveSim,旨在生成各種駕駛場景,為評估駕駛領域的MLLM提供平臺。此外,我們還貢獻了完整的開源代碼和一個新的數據集“Eval LLM Drive”,用于評估駕駛中的MLLM。我們的研究結果突顯了當前最先進MLLM能力的一個關鍵差距,強調了增強基礎模型的必要性,以提高其在現實世界動態環境中的適用性。


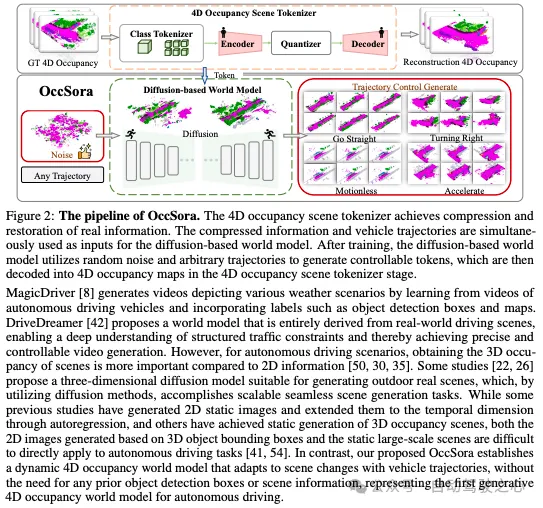
OccSora: 4D Occupancy Generation Models as World Simulators for Autonomous Driving
- 論文鏈接:https://arxiv.org/abs/2405.20337
- 開源鏈接:https://github.com/wzzheng/OccSora
北航&UC Berkeley等團隊的工作:了解3D場景的演變對于有效的自動駕駛非常重要。雖然傳統方法將場景開發與單個實例的運動相結合,但世界模型作為一個生成框架出現,用于描述一般的場景動態。然而大多數現有方法采用自回歸框架來執行下一個令牌預測,這在建模長期時間演化方面效率低下。為了解決這個問題,我們提出了一種基于擴散的4D占用生成模型OccSora,來模擬自動駕駛3D世界的發展。我們采用4D場景標記器來獲得4D占用輸入的緊湊離散時空表示,并實現長序列占用視頻的高質量重建。然后,我們學習時空表示上的擴散Transformer,并根據軌跡提示生成4D占用率。我們對廣泛使用的具有Occ3D占用注釋的nuScenes數據集進行了廣泛的實驗。OccSora可以生成具有真實3D布局和時間一致性的16秒視頻,展示了其理解駕駛場景的空間和時間分布的能力。通過軌跡感知4D生成,OccSora有可能成為自動駕駛決策的世界模擬器。



DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
- 論文鏈接:https://arxiv.org/abs/2403.06845v2
- 項目主頁:https://drivedreamer2.github.io/
中科院自動化研究所&GigaAI團隊的工作:世界模型在自動駕駛方面表現出了優勢,特別是在生成多視圖駕駛視頻方面。然而,在生成定制的駕駛視頻方面仍然存在重大挑戰。在本文中,我們提出了DriveDreamer-2,它基于DriveDreamer的框架,并結合了一個大型語言模型(LLM)來生成用戶定義的駕駛視頻。具體來說,最初結合了LLM接口,將用戶的查詢轉換為代理軌跡。隨后,根據軌跡生成符合交通規則的HDMap。最終,我們提出了統一多視圖模型來增強生成的駕駛視頻中的時間和空間連貫性。DriveDreamer-2是世界上第一款生成定制駕駛視頻的車型,它可以以用戶友好的方式生成不常見的駕駛視頻(例如,突然切入的車輛)。此外,實驗結果表明,生成的視頻增強了駕駛感知方法(如3D檢測和跟蹤)的訓練。此外,DriveDreamer-2的視頻生成質量超越了其他最先進的方法,顯示FID和FVD得分分別為11.2和55.7,相對提高了30%和50%。




WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens
- 論文鏈接:https://arxiv.org/abs/2401.09985v1
- 項目主頁:https://world-dreamer.github.io/
GigaAI和清華團隊的工作:世界模型在理解和預測世界動態方面發揮著至關重要的作用,這對視頻生成至關重要。然而,現有的世界模型僅限于游戲或駕駛等特定場景,限制了它們捕捉一般世界動態環境復雜性的能力。因此,我們介紹WorldDreamer,這是一個開創性的世界模型,旨在培養對一般世界物理和運動的全面理解,從而顯著增強視頻生成的能力。WorldDreamer從大型語言模型的成功中汲取靈感,將世界建模定義為無監督的視覺序列建模挑戰。這是通過將視覺輸入映射到離散的令牌并預測掩碼來實現的。在此過程中,我們結合了多模式提示,以促進世界模型內的交互。我們的實驗表明,WorldDreamer在生成不同場景的視頻方面表現出色,包括自然場景和駕駛環境。WorldDreamer展示了在執行文本到視頻轉換、圖像到視頻合成和視頻編輯等任務方面的多功能性。這些結果突顯了WorldDreamer在捕捉不同一般世界環境中的動態元素方面的有效性。



Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2)
- 論文鏈接:https://arxiv.org/abs/2402.16720v2
上交的工作:現實世界中的自動駕駛(AD),尤其是城市駕駛,涉及許多彎道情況。最近發布的AD模擬器CARLA v2在駕駛場景中增加了39個常見事件,與CARLA v1相比提供了更逼真的測試平臺。它給社區帶來了新的挑戰,到目前為止,還沒有文獻報道V2中的新場景取得了任何成功,因為現有的工作大多必須依賴于特定的規劃規則,但它們無法涵蓋CARLA V2中更復雜的案例。在這項工作中,我們主動直接訓練一個規劃者,希望靈活有效地處理極端情況,我們認為這也是AD的未來。據我們所知,我們開發了第一個基于模型的RL方法,名為Think2Drive for AD,使用世界模型來學習環境的轉變,然后它充當神經模擬器來訓練規劃者。由于低維狀態空間和世界模型中張量的并行計算,這種范式顯著提高了訓練效率。因此,Think2Drive能夠在單個A6000 GPU上訓練3天內以專家級熟練程度運行CARLA v2,據我們所知,到目前為止,CARLA v2上還沒有成功的報告(100%的路線完成)。我們還提出了CornerCase Repository,這是一個支持按場景評估駕駛模型的基準。此外,我們提出了一種新的平衡指標,通過路線完成情況、違規次數和場景密度來評估性能,以便駕駛分數可以提供更多關于實際駕駛性能的信息。



OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving
- 論文鏈接:https://arxiv.org/abs/2311.16038v1
- 開源鏈接:https://github.com/wzzheng/OccWorld
清華團隊的工作:了解3D場景如何演變對于自動駕駛決策至關重要。大多數現有方法通過預測對象框的運動來實現這一點,這無法捕獲更細粒度的場景信息。本文探索了一種在3D占用空間中學習世界模型OccWorld的新框架,以同時預測自車的運動和周圍場景的演變。我們建議基于3D占用而不是3D邊界框和分割圖來學習世界模型,原因有三:1)表現力:3D占用可以描述場景的更細粒度的3D結構;2)效率:獲得3D占用率更經濟(例如,從稀疏的LiDAR點)。3)多功能性:3D占用可以適應視覺和激光雷達。為了便于對世界演化進行建模,我們學習了一種基于重建的3D占用場景標記器,以獲得離散的場景標記來描述周圍的場景。然后,我們采用類似GPT的時空生成Transformer來生成后續場景和自車令牌,以解碼未來的占用和自車軌跡。在廣泛使用的nuScenes基準上進行的廣泛實驗證明了OccWorld有效模擬駕駛場景演變的能力。OccWorld還可以在不使用實例和地圖監督的情況下生成具有競爭力的規劃結果。




從這些工作中我們可以總結出以下幾點:
- 基于世界模型的端到端方法還在持續發展,未來能否落地還需觀望;
- Occ任務可以無縫地同世界模型相結合,引入VLM和3D GS也是未來可以進一步擴展研究的方向;
- 世界模型的核心是生成。基于生成的框架,可以添加很多模塊,以進一步增強可是解釋性和提升性能。
- 當下世界模型對運動規律、物理規則的建模能力還有限。





























